 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Focus on Hard Samples for Lung Nodule Detection
Mar 07, 2024Recently, lung nodule detection methods based on deep learning have shown excellent performance in the medical image processing field. Considering that only a few public lung datasets are available and lung nodules are more difficult to detect in CT images than in natural images, the existing methods face many bottlenecks when detecting lung nodules, especially hard ones in CT images. In order to solve these problems, we plan to enhance the focus of our network. In this work, we present an improved detection network that pays more attention to hard samples and datasets to deal with lung nodules by introducing deformable convolution and self-paced learning. Experiments on the LUNA16 dataset demonstrate the effectiveness of our proposed components and show that our method has reached competitive performance.
Distribution Fitting for Combating Mode Collapse in GANs
Dec 03, 2022Mode collapse is still a major unsolved problem in generative adversarial networks. In this work, we analyze the causes of mode collapse from a new perspective. Due to the nonuniform sampling in the training process, some sub-distributions can be missed while sampling data. Therefore, the GAN objective can reach the minimum when the generated distribution is not the same as the real one. To alleviate the problem, we propose a global distribution fitting (GDF) method by a penalty term to constrain generated data distribution. On the basis of not changing the global minimum of the GAN objective, GDF will make it harder to reach the minimum value when the generated distribution is not the same as the real one. Furthermore, we also propose a local distribution fitting (LDF) method to cope with the situation that the real distribution is unknown. Experiments on several benchmarks demonstrate the effectiveness and competitive performance of GDF and LDF.
Unified Chinese License Plate Detection and Recognition with High Efficiency
May 07, 2022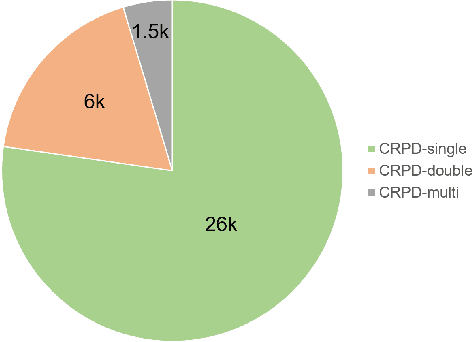
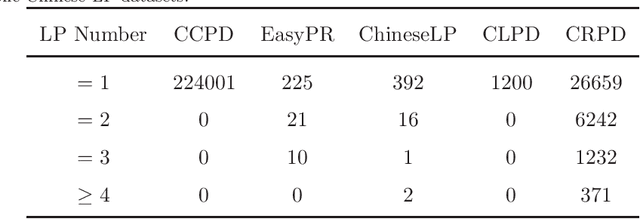

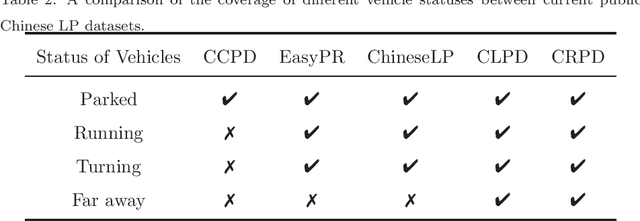
Recently, deep learning-based methods have reached an excellent performance on License Plate (LP) detection and recognition tasks. However, it is still challenging to build a robust model for Chinese LPs since there are not enough large and representative datasets. In this work, we propose a new dataset named Chinese Road Plate Dataset (CRPD) that contains multi-objective Chinese LP images as a supplement to the existing public benchmarks. The images are mainly captured with electronic monitoring systems with detailed annotations. To our knowledge, CRPD is the largest public multi-objective Chinese LP dataset with annotations of vertices. With CRPD, a unified detection and recognition network with high efficiency is presented as the baseline. The network is end-to-end trainable with totally real-time inference efficiency (30 fps with 640p). The experiments on several public benchmarks demonstrate that our method has reached competitive performance. The code and dataset will be publicly available at https://github.com/yxgong0/CRPD.
Unsupervised domain adaptation via coarse-to-fine feature alignment method using contrastive learning
Mar 23, 2021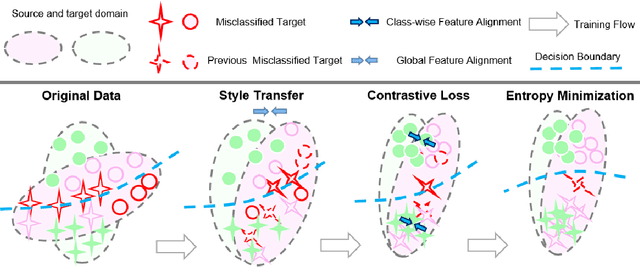

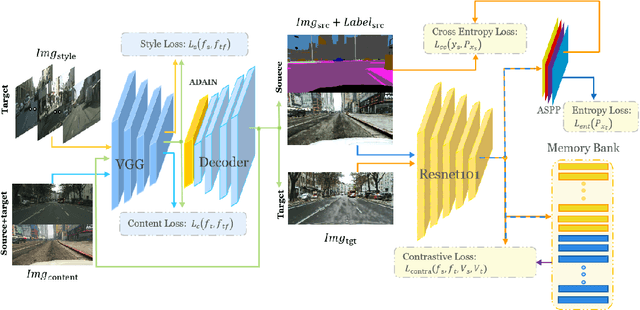

Previous feature alignment methods in Unsupervised domain adaptation(UDA) mostly only align global features without considering the mismatch between class-wise features. In this work, we propose a new coarse-to-fine feature alignment method using contrastive learning called CFContra. It draws class-wise features closer than coarse feature alignment or class-wise feature alignment only, therefore improves the model's performance to a great extent. We build it upon one of the most effective methods of UDA called entropy minimization to further improve performance. In particular, to prevent excessive memory occupation when applying contrastive loss in semantic segmentation, we devise a new way to build and update the memory bank. In this way, we make the algorithm more efficient and viable with limited memory. Extensive experiments show the effectiveness of our method and model trained on the GTA5 to Cityscapes dataset has boost mIOU by 3.5 compared to the MinEnt algorithm. Our code will be publicly available.
Single Image Super-Resolution via Residual Neuron Attention Networks
May 21, 2020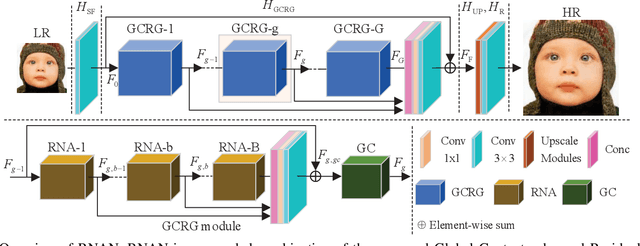
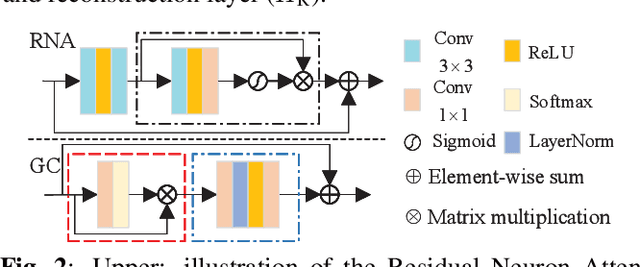
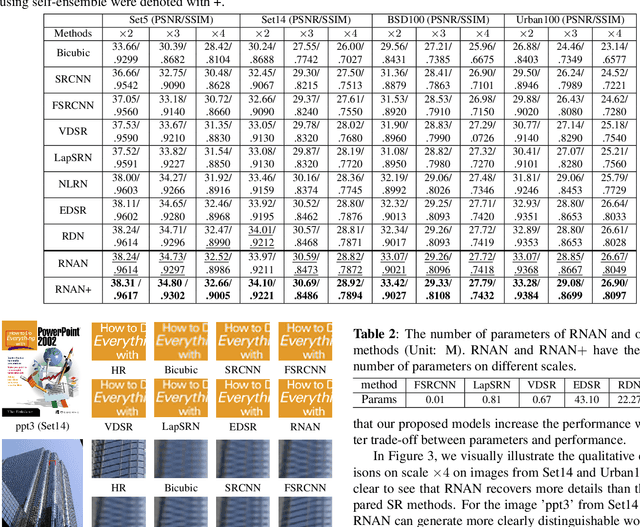
Deep Convolutional Neural Networks (DCNNs) have achieved impressive performance in Single Image Super-Resolution (SISR). To further improve the performance, existing CNN-based methods generally focus on designing deeper architecture of the network. However, we argue blindly increasing network's depth is not the most sensible way. In this paper, we propose a novel end-to-end Residual Neuron Attention Networks (RNAN) for more efficient and effective SISR. Structurally, our RNAN is a sequential integration of the well-designed Global Context-enhanced Residual Groups (GCRGs), which extracts super-resolved features from coarse to fine. Our GCRG is designed with two novelties. Firstly, the Residual Neuron Attention (RNA) mechanism is proposed in each block of GCRG to reveal the relevance of neurons for better feature representation. Furthermore, the Global Context (GC) block is embedded into RNAN at the end of each GCRG for effectively modeling the global contextual information. Experiments results demonstrate that our RNAN achieves the comparable results with state-of-the-art methods in terms of both quantitative metrics and visual quality, however, with simplified network architecture.
What's the relationship between CNNs and communication systems?
Mar 03, 2020The interpretability of Convolutional Neural Networks (CNNs) is an important topic in the field of computer vision. In recent years, works in this field generally adopt a mature model to reveal the internal mechanism of CNNs, helping to understand CNNs thoroughly. In this paper, we argue the working mechanism of CNNs can be revealed through a totally different interpretation, by comparing the communication systems and CNNs. This paper successfully obtained the corresponding relationship between the modules of the two, and verified the rationality of the corresponding relationship with experiments. Finally, through the analysis of some cutting-edge research on neural networks, we find the inherent relation between these two tasks can be of help in explaining these researches reasonably, as well as helping us discover the correct research direction of neural networks.
Defending from adversarial examples with a two-stream architecture
Dec 30, 2019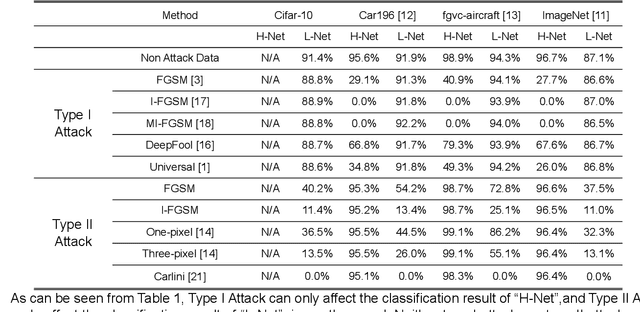
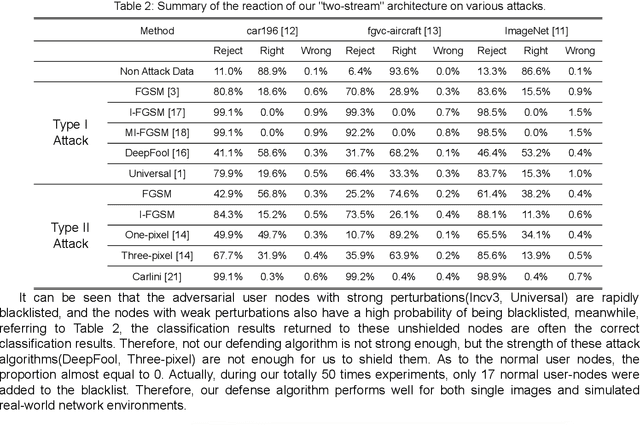
In recent years, deep learning has shown impressive performance on many tasks. However, recent researches showed that deep learning systems are vulnerable to small, specially crafted perturbations that are imperceptible to humans. Images with such perturbations are the so called adversarial examples, which have proven to be an indisputable threat to the DNN based applications. The lack of better understanding of the DNNs has prevented the development of efficient defenses against adversarial examples. In this paper, we propose a two-stream architecture to protect CNN from attacking by adversarial examples. Our model draws on the idea of "two-stream" which commonly used in the security field, and successfully defends different kinds of attack methods by the differences of "high-resolution" and "low-resolution" networks in feature extraction. We provide a reasonable interpretation on why our two-stream architecture is difficult to defeat, and show experimentally that our method is hard to defeat with state-of-the-art attacks. We demonstrate that our two-stream architecture is robust to adversarial examples built by currently known attacking algorithms.
Focus-Enhanced Scene Text Recognition with Deformable Convolutions
Sep 23, 2019
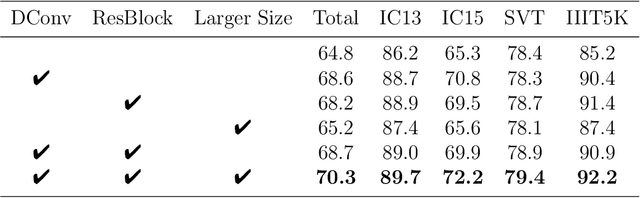
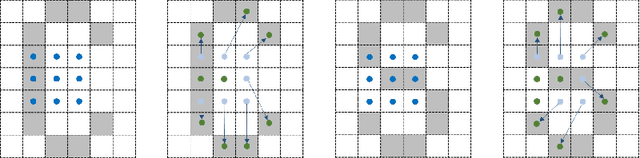
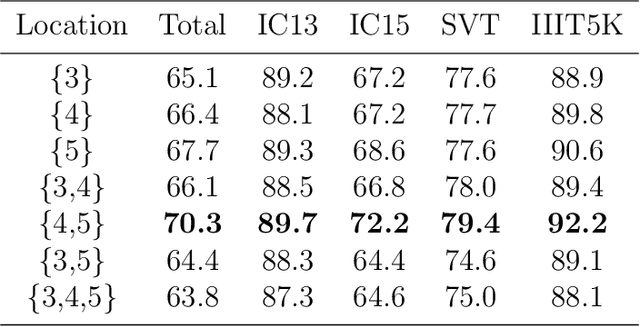
Recently, scene text recognition methods based on deep learning have sprung up in computer vision area. The existing methods achieved great performances, but the recognition of irregular text is still challenging due to the various shapes and distorted patterns. Consider that at the time of reading words in the real world, normally we will not rectify it in our mind but adjust our focus and visual fields. Similarly, through utilizing deformable convolutional layers whose geometric structures are adjustable, we present an enhanced recognition network without the steps of rectification to deal with irregular text in this work. A number of experiments have been applied, where the results on public benchmarks demonstrate the effectiveness of our proposed components and shows that our method has reached satisfactory performances. The code will be publicly available at https://github.com/Alpaca07/dtr soon.
STELA: A Real-Time Scene Text Detector with Learned Anchor
Sep 23, 2019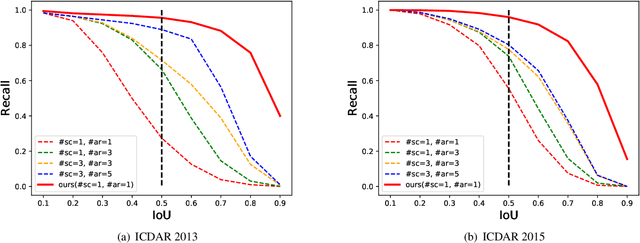
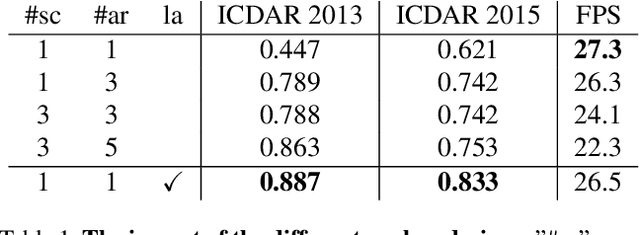
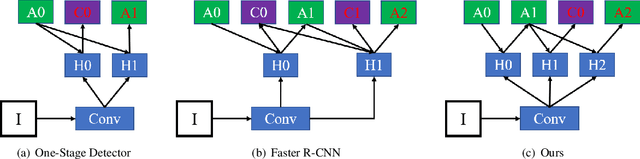
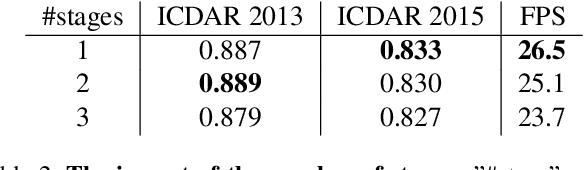
To achieve high coverage of target boxes, a normal strategy of conventional one-stage anchor-based detectors is to utilize multiple priors at each spatial position, especially in scene text detection tasks. In this work, we present a simple and intuitive method for multi-oriented text detection where each location of feature maps only associates with one reference box. The idea is inspired from the twostage R-CNN framework that can estimate the location of objects with any shape by using learned proposals. The aim of our method is to integrate this mechanism into a onestage detector and employ the learned anchor which is obtained through a regression operation to replace the original one into the final predictions. Based on RetinaNet, our method achieves competitive performances on several public benchmarks with a totally real-time efficiency (26:5fps at 800p), which surpasses all of anchor-based scene text detectors. In addition, with less attention on anchor design, we believe our method is easy to be applied on other analogous detection tasks. The code will publicly available at https://github.com/xhzdeng/stela.
Learning Robust 3D Face Reconstruction and Discriminative Identity Representation
May 16, 2019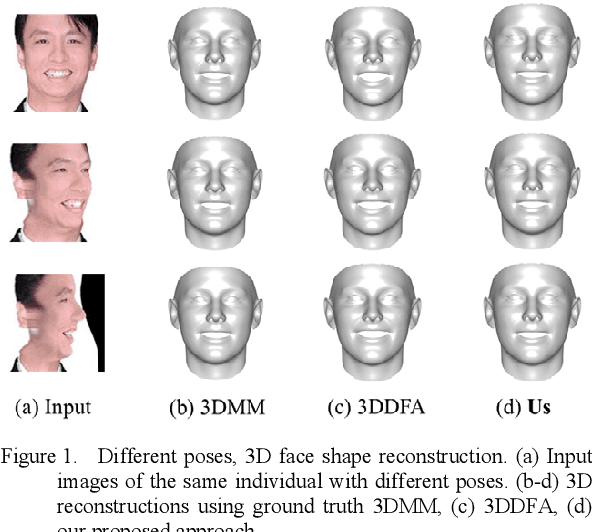
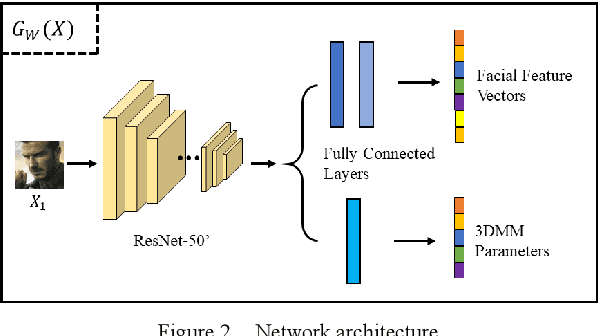
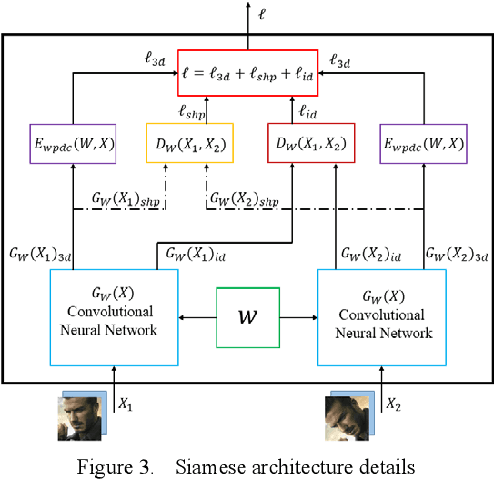
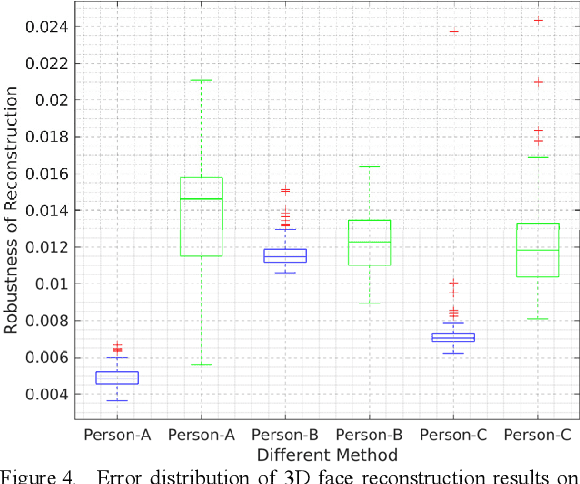
3D face reconstruction from a single 2D image is a very important topic in computer vision. However, the current reconstruction methods are usually non-sensitive to face identities and over-sensitive to facial poses, which may result in similar 3D geometries for faces of different identities, or obtain different shapes for the same identity with different poses. When such methods are applied practically, their 3D estimates are either changeable for different photos of the same subject or over-regularized and generic to distinguish face identities. In this paper, we propose a robust solution to solve this problem by carefully designing a novel Siamese Convolutional Neural Network (SCNN). Specifically, regarding the 3D Morphable face Model (3DMM) parameters of the same individual as the same class, we employ the contrastive loss to enlarge the inter-class distance and meanwhile reduce the intra-class distance for the output 3DMM parameters. We also propose an identity loss to preserve the identity information for the same individual in the feature space. Training with these two losses, our SCNN could learn representations that are more discriminative for face identity and generalizable for pose variants. Experiments on the challenging database 300W-LP and AFLW2000-3D have shown the effectiveness of our method by comparing with state-of-the-arts.