 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel In-context Learning for Large Vision Language Models
Mar 17, 2026Large vision-language models (LVLMs) employ multi-modal in-context learning (MM-ICL) to adapt to new tasks by leveraging demonstration examples. While increasing the number of demonstrations boosts performance, they incur significant inference latency due to the quadratic computational cost of Transformer attention with respect to the context length. To address this trade-off, we propose Parallel In-Context Learning (Parallel-ICL), a plug-and-play inference algorithm. Parallel-ICL partitions the long demonstration context into multiple shorter, manageable chunks. It processes these chunks in parallel and integrates their predictions at the logit level, using a weighted Product-of-Experts (PoE) ensemble to approximate the full-context output. Guided by ensemble learning theory, we introduce principled strategies for Parallel-ICL: (i) clustering-based context chunking to maximize inter-chunk diversity and (ii) similarity-based context compilation to weight predictions by query relevance. Extensive experiments on VQA, image captioning, and classification benchmarks demonstrate that Parallel-ICL achieves performance comparable to full-context MM-ICL, while significantly improving inference speed. Our work offers an effective solution to the accuracy-efficiency trade-off in MM-ICL, enabling dynamic task adaptation with substantially reduced inference overhead.
The Strong Lottery Ticket Hypothesis for Multi-Head Attention Mechanisms
Nov 06, 2025The strong lottery ticket hypothesis (SLTH) conjectures that high-performing subnetworks, called strong lottery tickets (SLTs), are hidden in randomly initialized neural networks. Although recent theoretical studies have established the SLTH across various neural architectures, the SLTH for transformer architectures still lacks theoretical understanding. In particular, the current theory of the SLTH does not yet account for the multi-head attention (MHA) mechanism, a core component of transformers. To address this gap, we introduce a theoretical analysis of the existence of SLTs within MHAs. We prove that, if a randomly initialized MHA of $H$ heads and input dimension $d$ has the hidden dimension $O(d\log(Hd^{3/2}))$ for the key and value, it contains an SLT that approximates an arbitrary MHA with the same input dimension with high probability. Furthermore, by leveraging this theory for MHAs, we extend the SLTH to transformers without normalization layers. We empirically validate our theoretical findings, demonstrating that the approximation error between the SLT within a source model (MHA and transformer) and an approximate target counterpart decreases exponentially by increasing the hidden dimension of the source model.
Do We Really Need Permutations? Impact of Width Expansion on Linear Mode Connectivity
Oct 09, 2025Recently, Ainsworth et al. empirically demonstrated that, given two independently trained models, applying a parameter permutation that preserves the input-output behavior allows the two models to be connected by a low-loss linear path. When such a path exists, the models are said to achieve linear mode connectivity (LMC). Prior studies, including Ainsworth et al., have reported that achieving LMC requires not only an appropriate permutation search but also sufficiently wide models (e.g., a 32 $\times$ width multiplier for ResNet-20). This is broadly believed to be because increasing the model width ensures a large enough space of candidate permutations, increasing the chance of finding one that yields LMC. In this work, we empirically demonstrate that, even without any permutations, simply widening the models is sufficient for achieving LMC when using a suitable softmax temperature calibration. We further explain why this phenomenon arises by analyzing intermediate layer outputs. Specifically, we introduce layerwise exponentially weighted connectivity (LEWC), which states that the output of each layer of the merged model can be represented as an exponentially weighted sum of the outputs of the corresponding layers of the original models. Consequently the merged model's output matches that of an ensemble of the original models, which facilitates LMC. To the best of our knowledge, this work is the first to show that widening the model not only facilitates nonlinear mode connectivity, as suggested in prior research, but also significantly increases the possibility of achieving linear mode connectivity.
Rationale-Enhanced Decoding for Multi-modal Chain-of-Thought
Jul 10, 2025Large vision-language models (LVLMs) have demonstrated remarkable capabilities by integrating pre-trained vision encoders with large language models (LLMs). Similar to single-modal LLMs, chain-of-thought (CoT) prompting has been adapted for LVLMs to enhance multi-modal reasoning by generating intermediate rationales based on visual and textual inputs. While CoT is assumed to improve grounding and accuracy in LVLMs, our experiments reveal a key challenge: existing LVLMs often ignore the contents of generated rationales in CoT reasoning. To address this, we re-formulate multi-modal CoT reasoning as a KL-constrained reward maximization focused on rationale-conditional log-likelihood. As the optimal solution, we propose rationale-enhanced decoding (RED), a novel plug-and-play inference-time decoding strategy. RED harmonizes visual and rationale information by multiplying distinct image-conditional and rationale-conditional next token distributions. Extensive experiments show that RED consistently and significantly improves reasoning over standard CoT and other decoding methods across multiple benchmarks and LVLMs. Our work offers a practical and effective approach to improve both the faithfulness and accuracy of CoT reasoning in LVLMs, paving the way for more reliable rationale-grounded multi-modal systems.
Post-pre-training for Modality Alignment in Vision-Language Foundation Models
Apr 17, 2025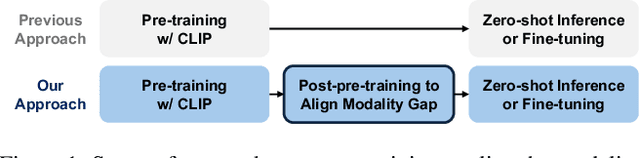
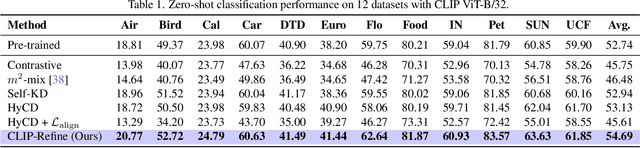
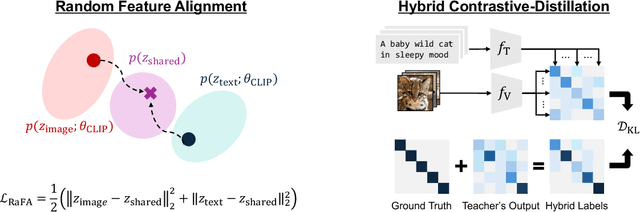
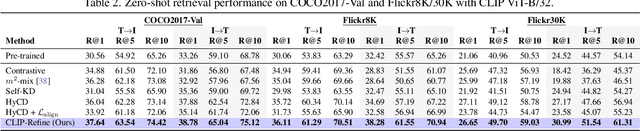
Contrastive language image pre-training (CLIP) is an essential component of building modern vision-language foundation models. While CLIP demonstrates remarkable zero-shot performance on downstream tasks, the multi-modal feature spaces still suffer from a modality gap, which is a gap between image and text feature clusters and limits downstream task performance. Although existing works attempt to address the modality gap by modifying pre-training or fine-tuning, they struggle with heavy training costs with large datasets or degradations of zero-shot performance. This paper presents CLIP-Refine, a post-pre-training method for CLIP models at a phase between pre-training and fine-tuning. CLIP-Refine aims to align the feature space with 1 epoch training on small image-text datasets without zero-shot performance degradations. To this end, we introduce two techniques: random feature alignment (RaFA) and hybrid contrastive-distillation (HyCD). RaFA aligns the image and text features to follow a shared prior distribution by minimizing the distance to random reference vectors sampled from the prior. HyCD updates the model with hybrid soft labels generated by combining ground-truth image-text pair labels and outputs from the pre-trained CLIP model. This contributes to achieving both maintaining the past knowledge and learning new knowledge to align features. Our extensive experiments with multiple classification and retrieval tasks show that CLIP-Refine succeeds in mitigating the modality gap and improving the zero-shot performance.
Portable Reward Tuning: Towards Reusable Fine-Tuning across Different Pretrained Models
Feb 18, 2025While foundation models have been exploited for various expert tasks through fine-tuning, any foundation model will become outdated due to its old knowledge or limited capability. Thus the underlying foundation model should be eventually replaced by new ones, which leads to repeated cost of fine-tuning these new models. Existing work addresses this problem by inference-time tuning, i.e., modifying the output probabilities from the new foundation model with the outputs from the old foundation model and its fine-tuned model, which involves an additional overhead in inference by the latter two models. In this paper, we propose a new fine-tuning principle, Portable Reward Tuning (PRT), that reduces the inference overhead by its nature, based on the reformulation of fine-tuning as the reward maximization. Specifically, instead of fine-tuning parameters of the foundation models, PRT trains the reward model explicitly through the same loss function as in fine-tuning. During inference, the reward model can be used with any foundation model (with the same set of vocabularies or labels) through the formulation of reward maximization. Experimental results, covering both vision and language models, demonstrate that the PRT-trained model can achieve comparable accuracy to the existing work of inference-time tuning, with less inference cost.
Zero-shot Concept Bottleneck Models
Feb 13, 2025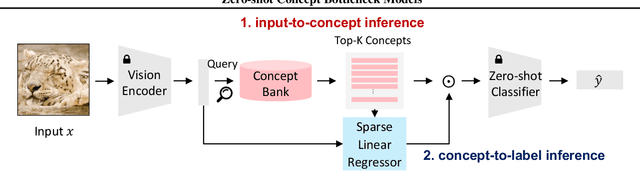

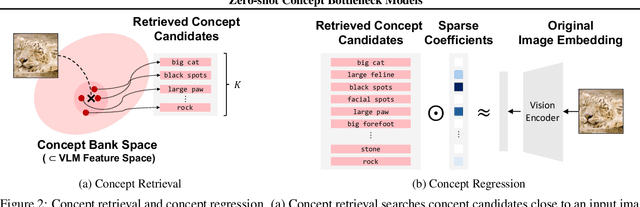

Concept bottleneck models (CBMs) are inherently interpretable and intervenable neural network models, which explain their final label prediction by the intermediate prediction of high-level semantic concepts. However, they require target task training to learn input-to-concept and concept-to-label mappings, incurring target dataset collections and training resources. In this paper, we present \textit{zero-shot concept bottleneck models} (Z-CBMs), which predict concepts and labels in a fully zero-shot manner without training neural networks. Z-CBMs utilize a large-scale concept bank, which is composed of millions of vocabulary extracted from the web, to describe arbitrary input in various domains. For the input-to-concept mapping, we introduce concept retrieval, which dynamically finds input-related concepts by the cross-modal search on the concept bank. In the concept-to-label inference, we apply concept regression to select essential concepts from the retrieved concepts by sparse linear regression. Through extensive experiments, we confirm that our Z-CBMs provide interpretable and intervenable concepts without any additional training. Code will be available at https://github.com/yshinya6/zcbm.
Adaptive Random Feature Regularization on Fine-tuning Deep Neural Networks
Mar 15, 2024While fine-tuning is a de facto standard method for training deep neural networks, it still suffers from overfitting when using small target datasets. Previous methods improve fine-tuning performance by maintaining knowledge of the source datasets or introducing regularization terms such as contrastive loss. However, these methods require auxiliary source information (e.g., source labels or datasets) or heavy additional computations. In this paper, we propose a simple method called adaptive random feature regularization (AdaRand). AdaRand helps the feature extractors of training models to adaptively change the distribution of feature vectors for downstream classification tasks without auxiliary source information and with reasonable computation costs. To this end, AdaRand minimizes the gap between feature vectors and random reference vectors that are sampled from class conditional Gaussian distributions. Furthermore, AdaRand dynamically updates the conditional distribution to follow the currently updated feature extractors and balance the distance between classes in feature spaces. Our experiments show that AdaRand outperforms the other fine-tuning regularization, which requires auxiliary source information and heavy computation costs.
Partial Search in a Frozen Network is Enough to Find a Strong Lottery Ticket
Feb 20, 2024Randomly initialized dense networks contain subnetworks that achieve high accuracy without weight learning -- strong lottery tickets (SLTs). Recently, Gadhikar et al. (2023) demonstrated theoretically and experimentally that SLTs can also be found within a randomly pruned source network, thus reducing the SLT search space. However, this limits the search to SLTs that are even sparser than the source, leading to worse accuracy due to unintentionally high sparsity. This paper proposes a method that reduces the SLT search space by an arbitrary ratio that is independent of the desired SLT sparsity. A random subset of the initial weights is excluded from the search space by freezing it -- i.e., by either permanently pruning them or locking them as a fixed part of the SLT. Indeed, the SLT existence in such a reduced search space is theoretically guaranteed by our subset-sum approximation with randomly frozen variables. In addition to reducing search space, the random freezing pattern can also be exploited to reduce model size in inference. Furthermore, experimental results show that the proposed method finds SLTs with better accuracy and model size trade-off than the SLTs obtained from dense or randomly pruned source networks. In particular, the SLT found in a frozen graph neural network achieves higher accuracy than its weight trained counterpart while reducing model size by $40.3\times$.
Regularizing Neural Networks with Meta-Learning Generative Models
Jul 26, 2023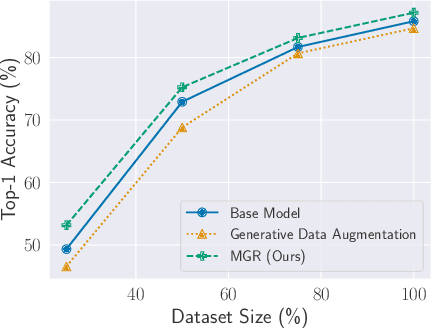

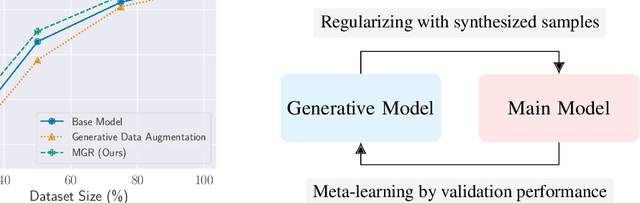

This paper investigates methods for improving generative data augmentation for deep learning. Generative data augmentation leverages the synthetic samples produced by generative models as an additional dataset for classification with small dataset settings. A key challenge of generative data augmentation is that the synthetic data contain uninformative samples that degrade accuracy. This is because the synthetic samples do not perfectly represent class categories in real data and uniform sampling does not necessarily provide useful samples for tasks. In this paper, we present a novel strategy for generative data augmentation called meta generative regularization (MGR). To avoid the degradation of generative data augmentation, MGR utilizes synthetic samples in the regularization term for feature extractors instead of in the loss function, e.g., cross-entropy. These synthetic samples are dynamically determined to minimize the validation losses through meta-learning. We observed that MGR can avoid the performance degradation of na\"ive generative data augmentation and boost the baselines. Experiments on six datasets showed that MGR is effective particularly when datasets are smaller and stably outperforms baselines.