 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Backdoor Removal by Reconstructing Trigger-Activated Changes in Latent Representation
Nov 12, 2025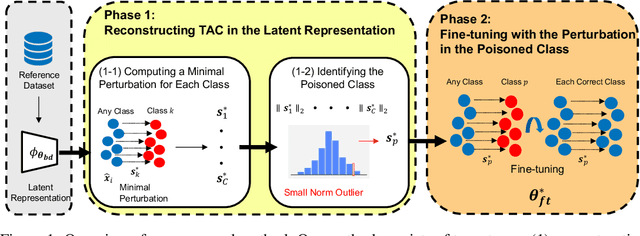
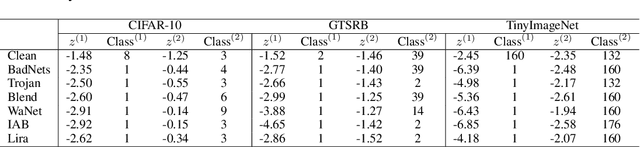
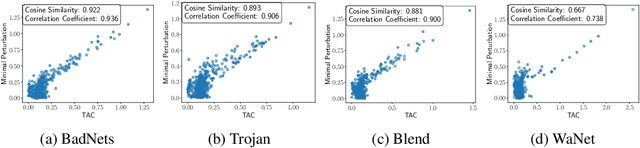
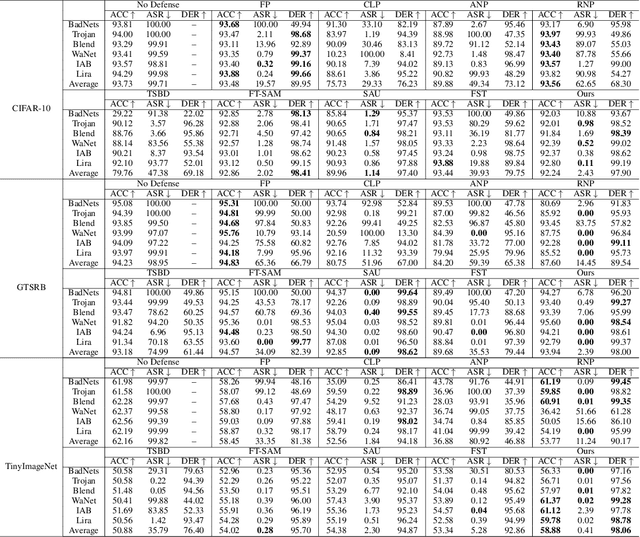
Backdoor attacks pose a critical threat to machine learning models, causing them to behave normally on clean data but misclassify poisoned data into a poisoned class. Existing defenses often attempt to identify and remove backdoor neurons based on Trigger-Activated Changes (TAC) which is the activation differences between clean and poisoned data. These methods suffer from low precision in identifying true backdoor neurons due to inaccurate estimation of TAC values. In this work, we propose a novel backdoor removal method by accurately reconstructing TAC values in the latent representation. Specifically, we formulate the minimal perturbation that forces clean data to be classified into a specific class as a convex quadratic optimization problem, whose optimal solution serves as a surrogate for TAC. We then identify the poisoned class by detecting statistically small $L^2$ norms of perturbations and leverage the perturbation of the poisoned class in fine-tuning to remove backdoors. Experiments on CIFAR-10, GTSRB, and TinyImageNet demonstrated that our approach consistently achieves superior backdoor suppression with high clean accuracy across different attack types, datasets, and architectures, outperforming existing defense methods.
Do We Really Need Permutations? Impact of Width Expansion on Linear Mode Connectivity
Oct 09, 2025Recently, Ainsworth et al. empirically demonstrated that, given two independently trained models, applying a parameter permutation that preserves the input-output behavior allows the two models to be connected by a low-loss linear path. When such a path exists, the models are said to achieve linear mode connectivity (LMC). Prior studies, including Ainsworth et al., have reported that achieving LMC requires not only an appropriate permutation search but also sufficiently wide models (e.g., a 32 $\times$ width multiplier for ResNet-20). This is broadly believed to be because increasing the model width ensures a large enough space of candidate permutations, increasing the chance of finding one that yields LMC. In this work, we empirically demonstrate that, even without any permutations, simply widening the models is sufficient for achieving LMC when using a suitable softmax temperature calibration. We further explain why this phenomenon arises by analyzing intermediate layer outputs. Specifically, we introduce layerwise exponentially weighted connectivity (LEWC), which states that the output of each layer of the merged model can be represented as an exponentially weighted sum of the outputs of the corresponding layers of the original models. Consequently the merged model's output matches that of an ensemble of the original models, which facilitates LMC. To the best of our knowledge, this work is the first to show that widening the model not only facilitates nonlinear mode connectivity, as suggested in prior research, but also significantly increases the possibility of achieving linear mode connectivity.
Sparse-Autoencoder-Guided Internal Representation Unlearning for Large Language Models
Sep 19, 2025As large language models (LLMs) are increasingly deployed across various applications, privacy and copyright concerns have heightened the need for more effective LLM unlearning techniques. Many existing unlearning methods aim to suppress undesirable outputs through additional training (e.g., gradient ascent), which reduces the probability of generating such outputs. While such suppression-based approaches can control model outputs, they may not eliminate the underlying knowledge embedded in the model's internal activations; muting a response is not the same as forgetting it. Moreover, such suppression-based methods often suffer from model collapse. To address these issues, we propose a novel unlearning method that directly intervenes in the model's internal activations. In our formulation, forgetting is defined as a state in which the activation of a forgotten target is indistinguishable from that of ``unknown'' entities. Our method introduces an unlearning objective that modifies the activation of the target entity away from those of known entities and toward those of unknown entities in a sparse autoencoder latent space. By aligning the target's internal activation with those of unknown entities, we shift the model's recognition of the target entity from ``known'' to ``unknown'', achieving genuine forgetting while avoiding over-suppression and model collapse. Empirically, we show that our method effectively aligns the internal activations of the forgotten target, a result that the suppression-based approaches do not reliably achieve. Additionally, our method effectively reduces the model's recall of target knowledge in question-answering tasks without significant damage to the non-target knowledge.
Analysis of Linear Mode Connectivity via Permutation-Based Weight Matching
Feb 19, 2024Recently, Ainsworth et al. showed that using weight matching (WM) to minimize the $L_2$ distance in a permutation search of model parameters effectively identifies permutations that satisfy linear mode connectivity (LMC), in which the loss along a linear path between two independently trained models with different seeds remains nearly constant. This paper provides a theoretical analysis of LMC using WM, which is crucial for understanding stochastic gradient descent's effectiveness and its application in areas like model merging. We first experimentally and theoretically show that permutations found by WM do not significantly reduce the $L_2$ distance between two models and the occurrence of LMC is not merely due to distance reduction by WM in itself. We then provide theoretical insights showing that permutations can change the directions of the singular vectors, but not the singular values, of the weight matrices in each layer. This finding shows that permutations found by WM mainly align the directions of singular vectors associated with large singular values across models. This alignment brings the singular vectors with large singular values, which determine the model functionality, closer between pre-merged and post-merged models, so that the post-merged model retains functionality similar to the pre-merged models, making it easy to satisfy LMC. Finally, we analyze the difference between WM and straight-through estimator (STE), a dataset-dependent permutation search method, and show that WM outperforms STE, especially when merging three or more models.
MPC Builder for Autonomous Drive: Automatic Generation of MPCs for Motion Planning and Control
Oct 29, 2022This study presents a new framework for vehicle motion planning and control based on the automatic generation of model predictive controllers (MPC) named MPC Builder. In this framework, several components necessary for MPC, such as models, constraints, and cost functions, are prepared in advance. The MPC Builder then online generates various MPCs according to traffic situations in a unified manner. This scheme enabled us to represent various driving tasks with minimal design effort. The proposed framework was implemented considering the continuation/generalized minimum residual (C/GMRES) method optimization solver, which can reduce computational costs. Finally, numerical experiments on multiple driving scenarios were presented.
Context-Sensitive Measurement of Word Distance by Adaptive Scaling of a Semantic Space
Jun 25, 1996



The paper proposes a computationally feasible method for measuring context-sensitive semantic distance between words. The distance is computed by adaptive scaling of a semantic space. In the semantic space, each word in the vocabulary V is represented by a multi-dimensional vector which is obtained from an English dictionary through a principal component analysis. Given a word set C which specifies a context for measuring word distance, each dimension of the semantic space is scaled up or down according to the distribution of C in the semantic space. In the space thus transformed, distance between words in V becomes dependent on the context C. An evaluation through a word prediction task shows that the proposed measurement successfully extracts the context of a text.