 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Failure Detection Based on Projected Quantum Models
Jan 22, 2026Detecting machine failures promptly is of utmost importance in industry for maintaining efficiency and minimizing downtime. This paper introduces a failure detection algorithm based on quantum computing and a statistical change-point detection approach. Our method leverages the potential of projected quantum feature maps to enhance the precision of anomaly detection in machine monitoring systems. We empirically validate our approach on benchmark multi-dimensional time series datasets as well as on a real-world dataset comprising IoT sensor readings from operational machines, ensuring the practical relevance of our study. The algorithm was executed on IBM's 133-qubit Heron quantum processor, demonstrating the feasibility of integrating quantum computing into industrial maintenance procedures. The presented results underscore the effectiveness of our quantum-based failure detection system, showcasing its capability to accurately identify anomalies in noisy time series data. This work not only highlights the potential of quantum computing in industrial diagnostics but also paves the way for more sophisticated quantum algorithms in the realm of predictive maintenance.
A Security Verification Framework of Cryptographic Protocols Using Machine Learning
Apr 26, 2023



We propose a security verification framework for cryptographic protocols using machine learning. In recent years, as cryptographic protocols have become more complex, research on automatic verification techniques has been focused on. The main technique is formal verification. However, the formal verification has two problems: it requires a large amount of computational time and does not guarantee decidability. We propose a method that allows security verification with computational time on the order of linear with respect to the size of the protocol using machine learning. In training machine learning models for security verification of cryptographic protocols, a sufficient amount of data, i.e., a set of protocol data with security labels, is difficult to collect from academic papers and other sources. To overcome this issue, we propose a way to create arbitrarily large datasets by automatically generating random protocols and assigning security labels to them using formal verification tools. Furthermore, to exploit structural features of protocols, we construct a neural network that processes a protocol along its series and tree structures. We evaluate the proposed method by applying it to verification of practical cryptographic protocols.
Fast Saturating Gate for Learning Long Time Scales with Recurrent Neural Networks
Oct 04, 2022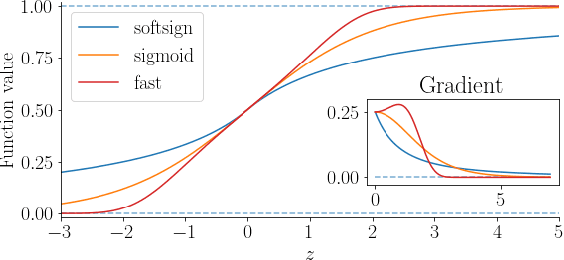

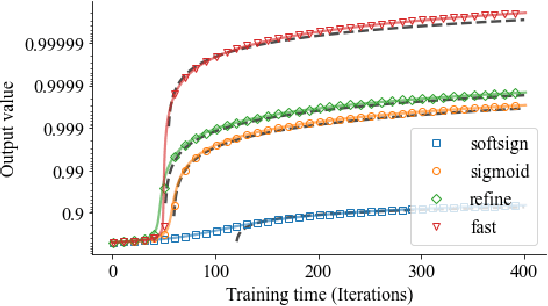
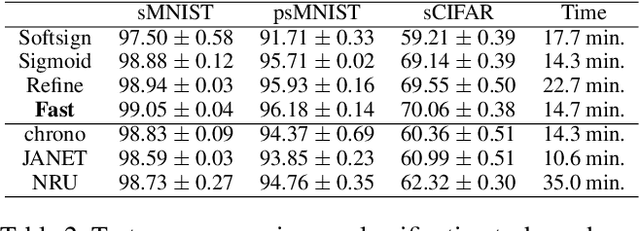
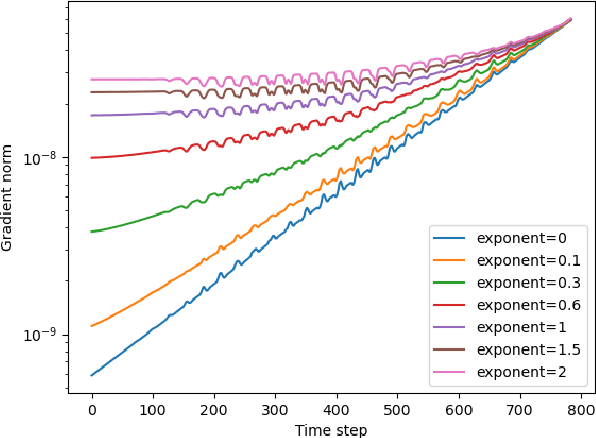
Gate functions in recurrent models, such as an LSTM and GRU, play a central role in learning various time scales in modeling time series data by using a bounded activation function. However, it is difficult to train gates to capture extremely long time scales due to gradient vanishing of the bounded function for large inputs, which is known as the saturation problem. We closely analyze the relation between saturation of the gate function and efficiency of the training. We prove that the gradient vanishing of the gate function can be mitigated by accelerating the convergence of the saturating function, i.e., making the output of the function converge to 0 or 1 faster. Based on the analysis results, we propose a gate function called fast gate that has a doubly exponential convergence rate with respect to inputs by simple function composition. We empirically show that our method outperforms previous methods in accuracy and computational efficiency on benchmark tasks involving extremely long time scales.
Recurrent Neural Networks for Learning Long-term Temporal Dependencies with Reanalysis of Time Scale Representation
Nov 05, 2021

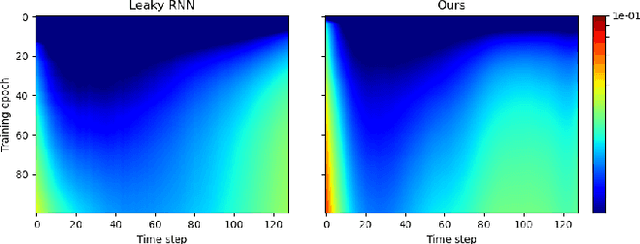
Recurrent neural networks with a gating mechanism such as an LSTM or GRU are powerful tools to model sequential data. In the mechanism, a forget gate, which was introduced to control information flow in a hidden state in the RNN, has recently been re-interpreted as a representative of the time scale of the state, i.e., a measure how long the RNN retains information on inputs. On the basis of this interpretation, several parameter initialization methods to exploit prior knowledge on temporal dependencies in data have been proposed to improve learnability. However, the interpretation relies on various unrealistic assumptions, such as that there are no inputs after a certain time point. In this work, we reconsider this interpretation of the forget gate in a more realistic setting. We first generalize the existing theory on gated RNNs so that we can consider the case where inputs are successively given. We then argue that the interpretation of a forget gate as a temporal representation is valid when the gradient of loss with respect to the state decreases exponentially as time goes back. We empirically demonstrate that existing RNNs satisfy this gradient condition at the initial training phase on several tasks, which is in good agreement with previous initialization methods. On the basis of this finding, we propose an approach to construct new RNNs that can represent a longer time scale than conventional models, which will improve the learnability for long-term sequential data. We verify the effectiveness of our method by experiments with real-world datasets.