 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriching Disentanglement: Definitions to Metrics
May 19, 2023



Disentangled representation learning is a challenging task that involves separating multiple factors of variation in complex data. Although various metrics for learning and evaluating disentangled representations have been proposed, it remains unclear what these metrics truly quantify and how to compare them. In this work, we study the definitions of disentanglement given by first-order equational predicates and introduce a systematic approach for transforming an equational definition into a compatible quantitative metric based on enriched category theory. Specifically, we show how to replace (i) equality with metric or divergence, (ii) logical connectives with order operations, (iii) universal quantifier with aggregation, and (iv) existential quantifier with the best approximation. Using this approach, we derive metrics for measuring the desired properties of a disentangled representation extractor and demonstrate their effectiveness on synthetic data. Our proposed approach provides practical guidance for researchers in selecting appropriate evaluation metrics and designing effective learning algorithms for disentangled representation learning.
A Category-theoretical Meta-analysis of Definitions of Disentanglement
May 11, 2023Disentangling the factors of variation in data is a fundamental concept in machine learning and has been studied in various ways by different researchers, leading to a multitude of definitions. Despite the numerous empirical studies, more theoretical research is needed to fully understand the defining properties of disentanglement and how different definitions relate to each other. This paper presents a meta-analysis of existing definitions of disentanglement, using category theory as a unifying and rigorous framework. We propose that the concepts of the cartesian and monoidal products should serve as the core of disentanglement. With these core concepts, we show the similarities and crucial differences in dealing with (i) functions, (ii) equivariant maps, (iii) relations, and (iv) stochastic maps. Overall, our meta-analysis deepens our understanding of disentanglement and its various formulations and can help researchers navigate different definitions and choose the most appropriate one for their specific context.
Equivariant Disentangled Transformation for Domain Generalization under Combination Shift
Aug 03, 2022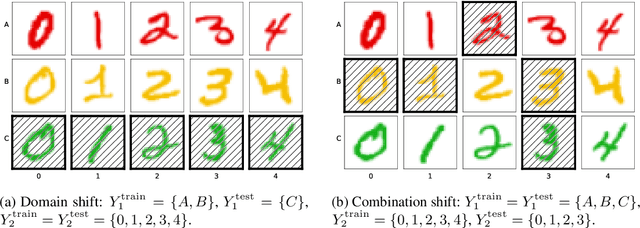
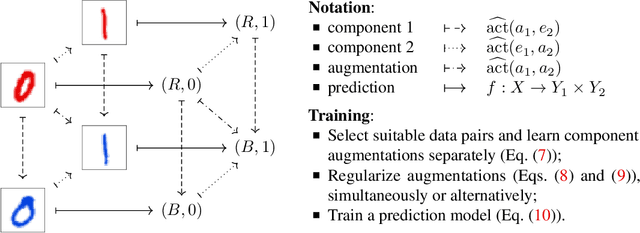
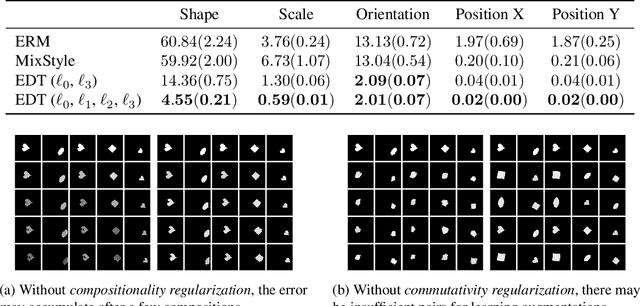
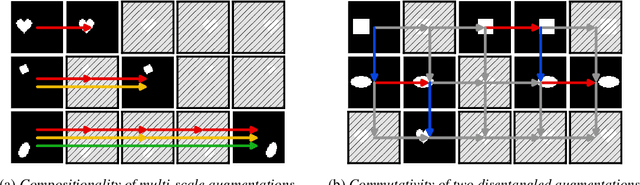
Machine learning systems may encounter unexpected problems when the data distribution changes in the deployment environment. A major reason is that certain combinations of domains and labels are not observed during training but appear in the test environment. Although various invariance-based algorithms can be applied, we find that the performance gain is often marginal. To formally analyze this issue, we provide a unique algebraic formulation of the combination shift problem based on the concepts of homomorphism, equivariance, and a refined definition of disentanglement. The algebraic requirements naturally derive a simple yet effective method, referred to as equivariant disentangled transformation (EDT), which augments the data based on the algebraic structures of labels and makes the transformation satisfy the equivariance and disentanglement requirements. Experimental results demonstrate that invariance may be insufficient, and it is important to exploit the equivariance structure in the combination shift problem.
Approximating Instance-Dependent Noise via Instance-Confidence Embedding
Mar 25, 2021
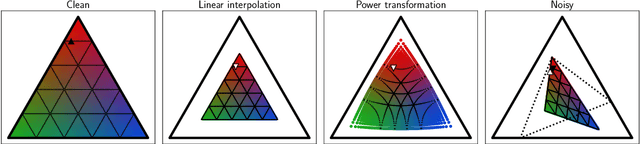


Label noise in multiclass classification is a major obstacle to the deployment of learning systems. However, unlike the widely used class-conditional noise (CCN) assumption that the noisy label is independent of the input feature given the true label, label noise in real-world datasets can be aleatory and heavily dependent on individual instances. In this work, we investigate the instance-dependent noise (IDN) model and propose an efficient approximation of IDN to capture the instance-specific label corruption. Concretely, noting the fact that most columns of the IDN transition matrix have only limited influence on the class-posterior estimation, we propose a variational approximation that uses a single-scalar confidence parameter. To cope with the situation where the mapping from the instance to its confidence value could vary significantly for two adjacent instances, we suggest using instance embedding that assigns a trainable parameter to each instance. The resulting instance-confidence embedding (ICE) method not only performs well under label noise but also can effectively detect ambiguous or mislabeled instances. We validate its utility on various image and text classification tasks.
Learning Noise Transition Matrix from Only Noisy Labels via Total Variation Regularization
Feb 04, 2021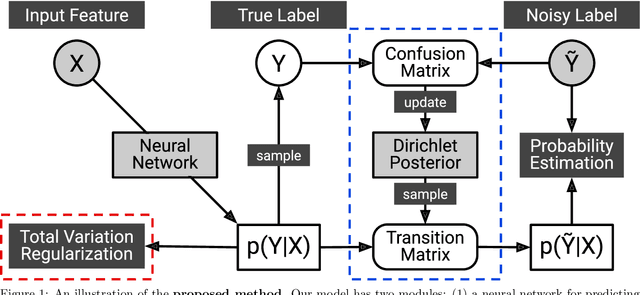
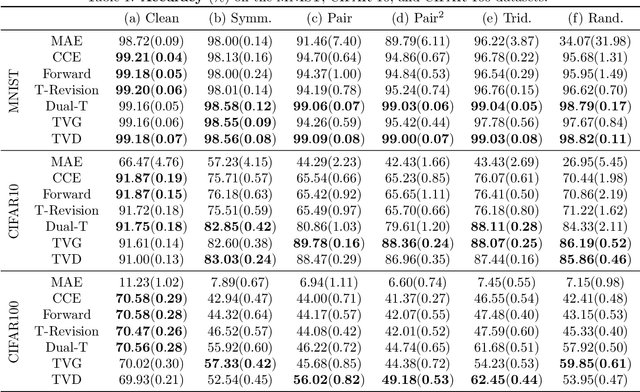
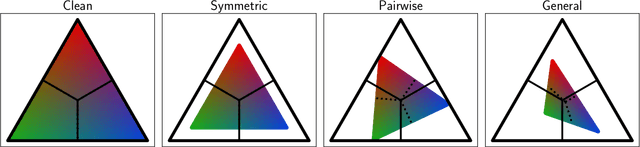
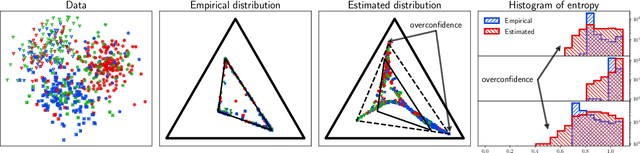
Many weakly supervised classification methods employ a noise transition matrix to capture the class-conditional label corruption. To estimate the transition matrix from noisy data, existing methods often need to estimate the noisy class-posterior, which could be unreliable due to the overconfidence of neural networks. In this work, we propose a theoretically grounded method that can estimate the noise transition matrix and learn a classifier simultaneously, without relying on the error-prone noisy class-posterior estimation. Concretely, inspired by the characteristics of the stochastic label corruption process, we propose total variation regularization, which encourages the predicted probabilities to be more distinguishable from each other. Under mild assumptions, the proposed method yields a consistent estimator of the transition matrix. We show the effectiveness of the proposed method through experiments on benchmark and real-world datasets.
Classification with Rejection Based on Cost-sensitive Classification
Oct 31, 2020
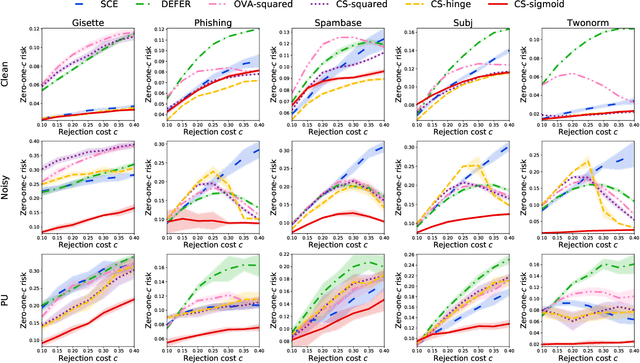
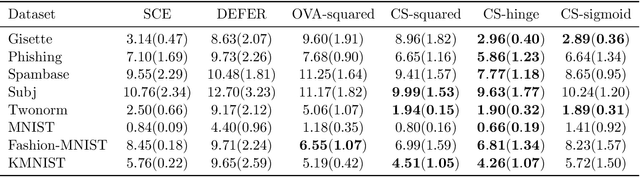

The goal of classification with rejection is to avoid risky misclassification in error-critical applications such as medical diagnosis and product inspection. In this paper, based on the relationship between classification with rejection and cost-sensitive classification, we propose a novel method of classification with rejection by learning an ensemble of cost-sensitive classifiers, which satisfies all the following properties for the first time: (i) it can avoid estimating class-posterior probabilities, resulting in improved classification accuracy. (ii) it allows a flexible choice of losses including non-convex ones, (iii) it does not require complicated modifications when using different losses, (iv) it is applicable to both binary and multiclass cases, and (v) it is theoretically justifiable for any classification-calibrated loss. Experimental results demonstrate the usefulness of our proposed approach in clean-labeled, noisy-labeled, and positive-unlabeled classification.
Learning from Aggregate Observations
Apr 14, 2020

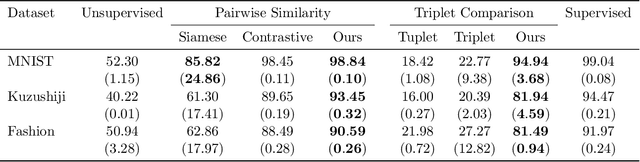
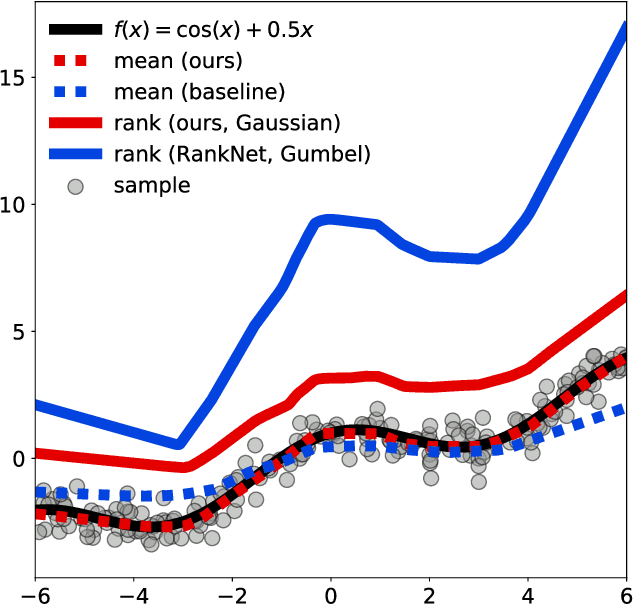
We study the problem of learning from aggregate observations where supervision signals are given to sets of instances instead of individual instances, while the goal is still to predict labels of unseen individuals. A well-known example is multiple instance learning (MIL). In this paper, we extend MIL beyond binary classification to other problems such as multiclass classification and regression. We present a probabilistic framework that is applicable to a variety of aggregate observations, e.g., pairwise similarity for classification and mean/difference/rank observation for regression. We propose a simple yet effective method based on the maximum likelihood principle, which can be simply implemented for various differentiable models such as deep neural networks and gradient boosting machines. Experiments on three novel problem settings -- classification via triplet comparison and regression via mean/rank observation indicate the effectiveness of the proposed method.
Learning from Indirect Observations
Oct 10, 2019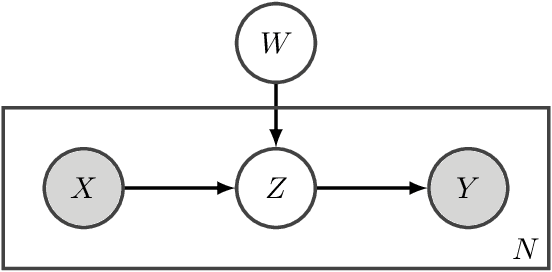
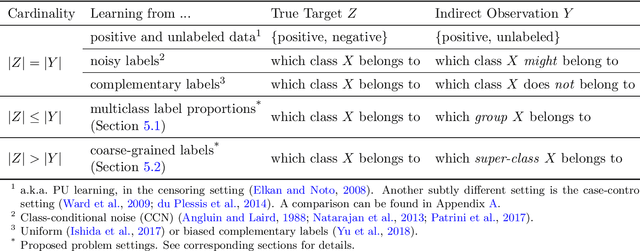


Weakly-supervised learning is a paradigm for alleviating the scarcity of labeled data by leveraging lower-quality but larger-scale supervision signals. While existing work mainly focuses on utilizing a certain type of weak supervision, we present a probabilistic framework, learning from indirect observations, for learning from a wide range of weak supervision in real-world problems, e.g., noisy labels, complementary labels and coarse-grained labels. We propose a general method based on the maximum likelihood principle, which has desirable theoretical properties and can be straightforwardly implemented for deep neural networks. Concretely, a discriminative model for the true target is used for modeling the indirect observation, which is a random variable entirely depending on the true target stochastically or deterministically. Then, maximizing the likelihood given indirect observations leads to an estimator of the true target implicitly. Comprehensive experiments for two novel problem settings --- learning from multiclass label proportions and learning from coarse-grained labels, illustrate practical usefulness of our method and demonstrate how to integrate various sources of weak supervision.