 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Aggregate Observations
Paper and Code


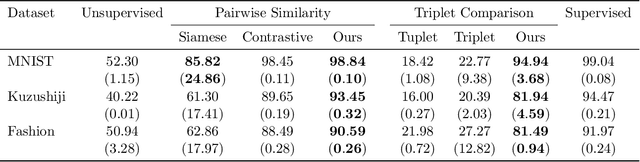
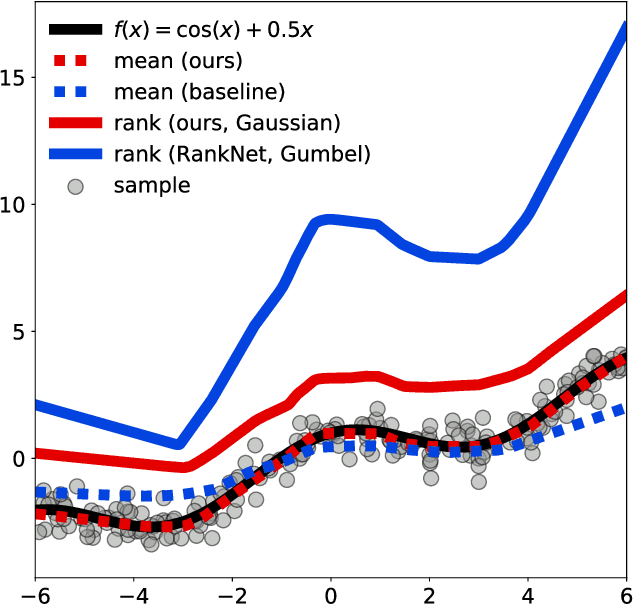
We study the problem of learning from aggregate observations where supervision signals are given to sets of instances instead of individual instances, while the goal is still to predict labels of unseen individuals. A well-known example is multiple instance learning (MIL). In this paper, we extend MIL beyond binary classification to other problems such as multiclass classification and regression. We present a probabilistic framework that is applicable to a variety of aggregate observations, e.g., pairwise similarity for classification and mean/difference/rank observation for regression. We propose a simple yet effective method based on the maximum likelihood principle, which can be simply implemented for various differentiable models such as deep neural networks and gradient boosting machines. Experiments on three novel problem settings -- classification via triplet comparison and regression via mean/rank observation indicate the effectiveness of the proposed method.