 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Learning with Proper Partial Labels
Dec 23, 2021

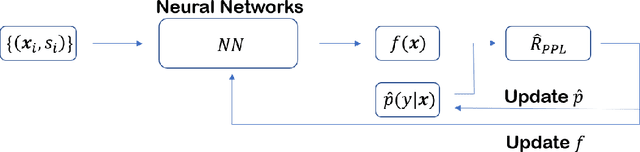

Partial-label learning is a kind of weakly-supervised learning with inexact labels, where for each training example, we are given a set of candidate labels instead of only one true label. Recently, various approaches on partial-label learning have been proposed under different generation models of candidate label sets. However, these methods require relatively strong distributional assumptions on the generation models. When the assumptions do not hold, the performance of the methods is not guaranteed theoretically. In this paper, we propose the notion of properness on partial labels. We show that this proper partial-label learning framework includes many previous partial-label learning settings as special cases. We then derive a unified unbiased estimator of the classification risk. We prove that our estimator is risk-consistent by obtaining its estimation error bound. Finally, we validate the effectiveness of our algorithm through experiments.
Learning from Aggregate Observations
Apr 14, 2020

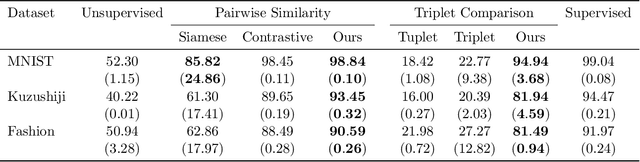
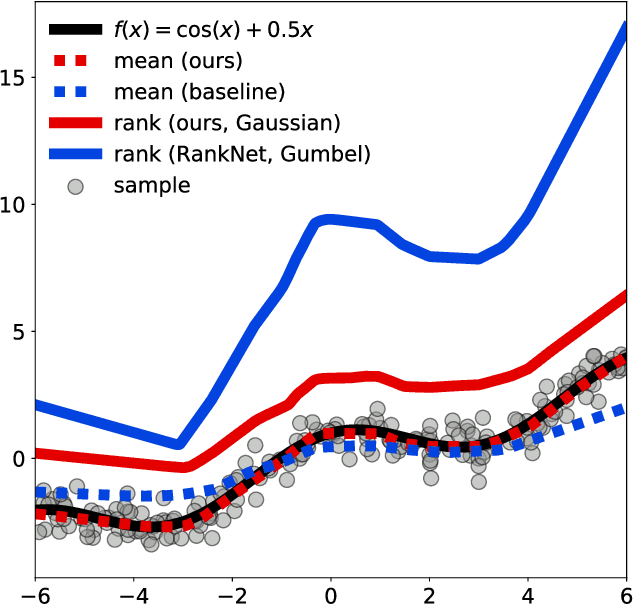
We study the problem of learning from aggregate observations where supervision signals are given to sets of instances instead of individual instances, while the goal is still to predict labels of unseen individuals. A well-known example is multiple instance learning (MIL). In this paper, we extend MIL beyond binary classification to other problems such as multiclass classification and regression. We present a probabilistic framework that is applicable to a variety of aggregate observations, e.g., pairwise similarity for classification and mean/difference/rank observation for regression. We propose a simple yet effective method based on the maximum likelihood principle, which can be simply implemented for various differentiable models such as deep neural networks and gradient boosting machines. Experiments on three novel problem settings -- classification via triplet comparison and regression via mean/rank observation indicate the effectiveness of the proposed method.