Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Proximal Policy Optimization
Paper and Code
Jun 25, 2019
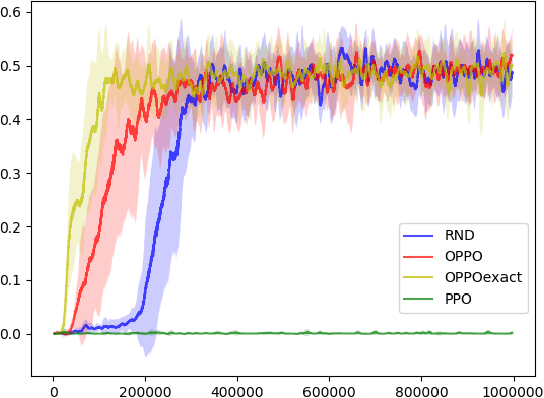
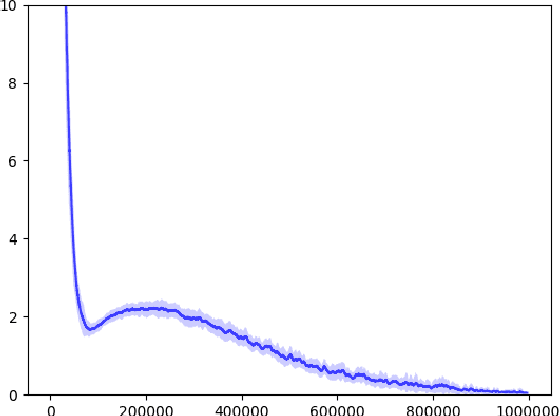
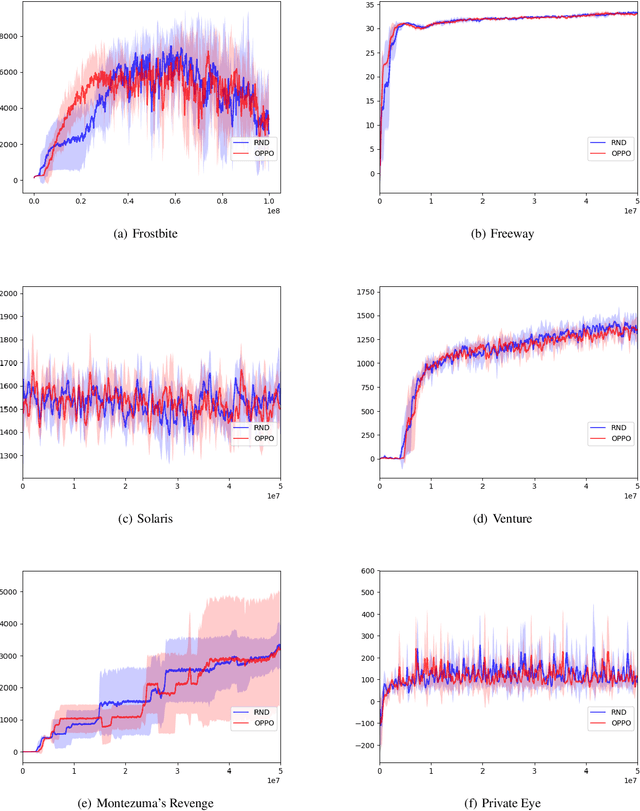
Reinforcement Learning, a machine learning framework for training an autonomous agent based on rewards, has shown outstanding results in various domains. However, it is known that learning a good policy is difficult in a domain where rewards are rare. We propose a method, optimistic proximal policy optimization (OPPO) to alleviate this difficulty. OPPO considers the uncertainty of the estimated total return and optimistically evaluates the policy based on that amount. We show that OPPO outperforms the existing methods in a tabular task.
* Exploration in RL (workshop @ ICML2019)
View paper on