 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Quantized Training of Language Models with Stochastic Rounding
Dec 06, 2024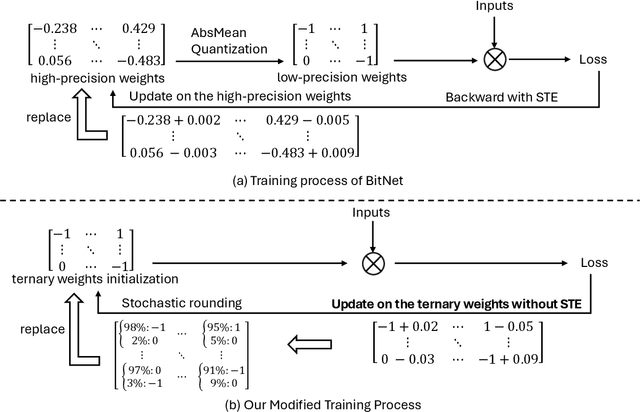
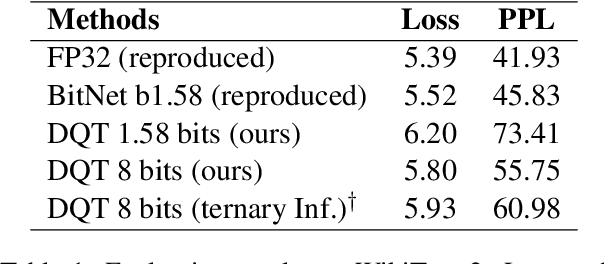
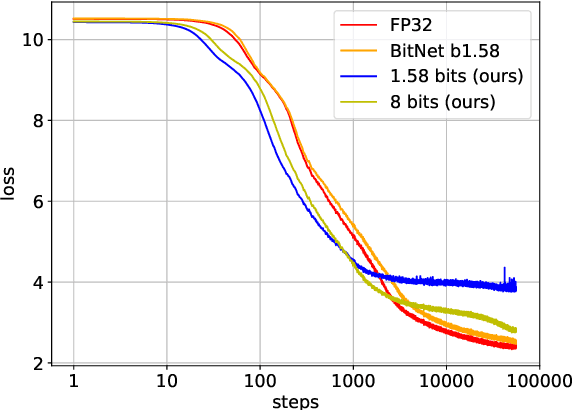
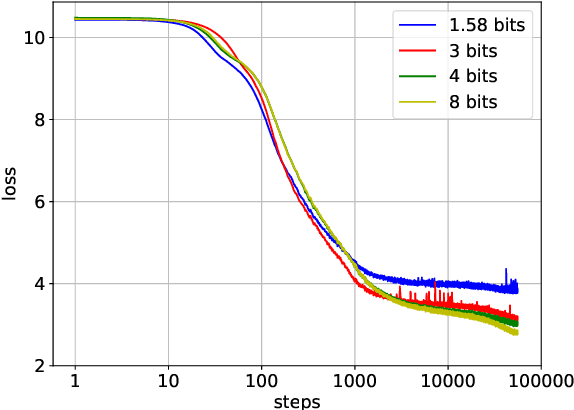
Although recent quantized Large Language Models (LLMs), such as BitNet, have paved the way for significant reduction in memory usage during deployment with binary or ternary weights, training these models still demands substantial memory footprints. This is partly because high-precision (i.e., unquantized) weight matrices required for straight-through estimation must be maintained throughout the whole training process. To address this, we explore the potential of directly updating the quantized low-precision weight matrices without relying on the straight-through estimator during backpropagation, thereby saving memory usage during training. Specifically, we employ a stochastic rounding technique to minimize information loss caused by the use of low-bit weights throughout training. Experimental results on our LLaMA-structured models indicate that (1) training with only low-precision weights is feasible even when they are constrained to ternary values, (2) extending the bit width to 8 bits results in only a 5% loss degradation compared to BitNet b1.58 while offering the potential for reduced memory usage during training, and (3) our models can also perform inference using ternary weights, showcasing their flexibility in deployment.
Neural Network Module Decomposition and Recomposition
Dec 25, 2021

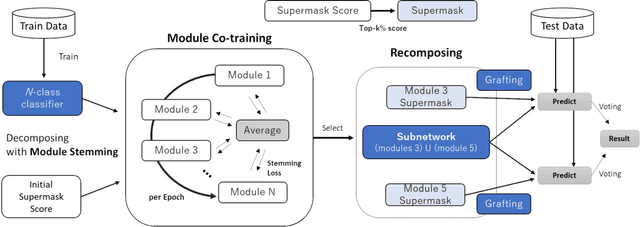

We propose a modularization method that decomposes a deep neural network (DNN) into small modules from a functionality perspective and recomposes them into a new model for some other task. Decomposed modules are expected to have the advantages of interpretability and verifiability due to their small size. In contrast to existing studies based on reusing models that involve retraining, such as a transfer learning model, the proposed method does not require retraining and has wide applicability as it can be easily combined with existing functional modules. The proposed method extracts modules using weight masks and can be applied to arbitrary DNNs. Unlike existing studies, it requires no assumption about the network architecture. To extract modules, we designed a learning method and a loss function to maximize shared weights among modules. As a result, the extracted modules can be recomposed without a large increase in the size. We demonstrate that the proposed method can decompose and recompose DNNs with high compression ratio and high accuracy and is superior to the existing method through sharing weights between modules.