 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Quantized Training of Language Models with Stochastic Rounding
Paper and Code
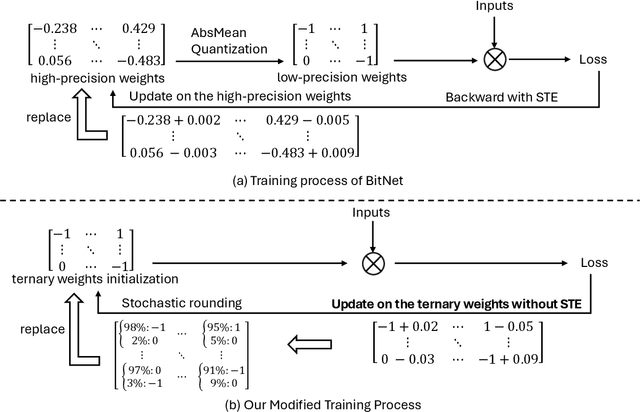
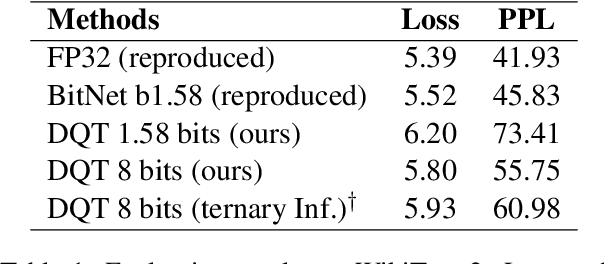
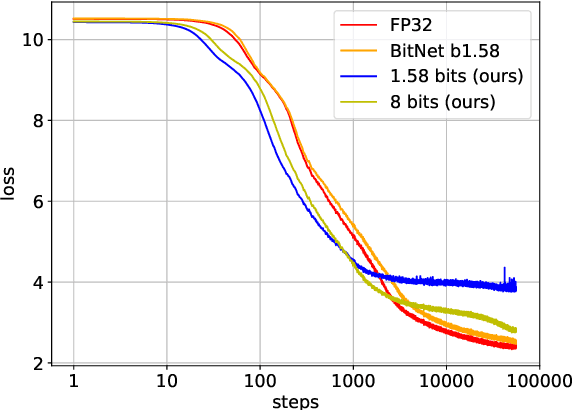
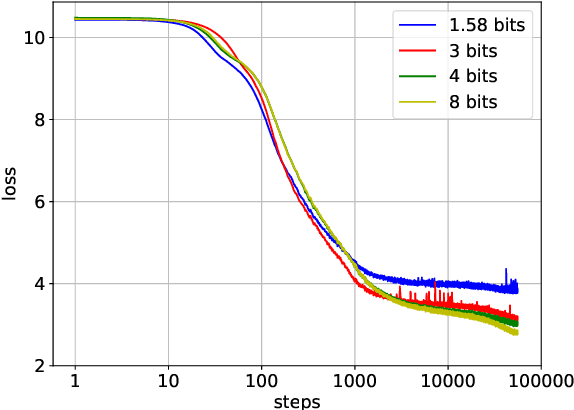
Although recent quantized Large Language Models (LLMs), such as BitNet, have paved the way for significant reduction in memory usage during deployment with binary or ternary weights, training these models still demands substantial memory footprints. This is partly because high-precision (i.e., unquantized) weight matrices required for straight-through estimation must be maintained throughout the whole training process. To address this, we explore the potential of directly updating the quantized low-precision weight matrices without relying on the straight-through estimator during backpropagation, thereby saving memory usage during training. Specifically, we employ a stochastic rounding technique to minimize information loss caused by the use of low-bit weights throughout training. Experimental results on our LLaMA-structured models indicate that (1) training with only low-precision weights is feasible even when they are constrained to ternary values, (2) extending the bit width to 8 bits results in only a 5% loss degradation compared to BitNet b1.58 while offering the potential for reduced memory usage during training, and (3) our models can also perform inference using ternary weights, showcasing their flexibility in deployment.