 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Quantized Training of Language Models with Stochastic Rounding
Dec 06, 2024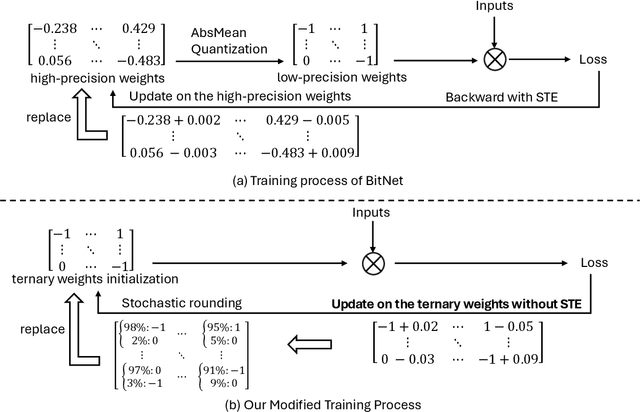
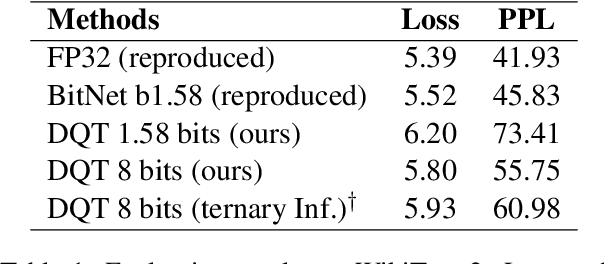
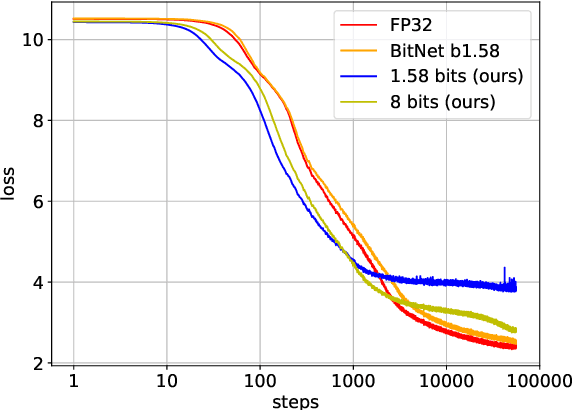
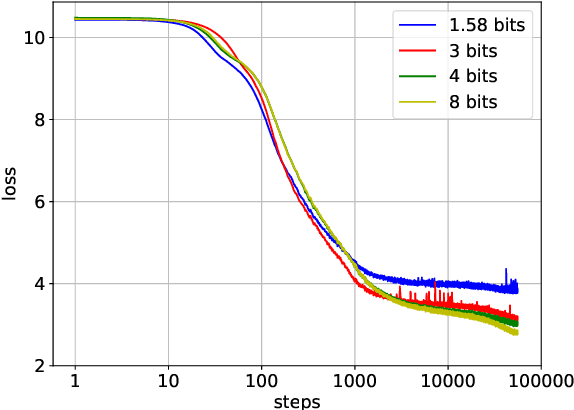
Although recent quantized Large Language Models (LLMs), such as BitNet, have paved the way for significant reduction in memory usage during deployment with binary or ternary weights, training these models still demands substantial memory footprints. This is partly because high-precision (i.e., unquantized) weight matrices required for straight-through estimation must be maintained throughout the whole training process. To address this, we explore the potential of directly updating the quantized low-precision weight matrices without relying on the straight-through estimator during backpropagation, thereby saving memory usage during training. Specifically, we employ a stochastic rounding technique to minimize information loss caused by the use of low-bit weights throughout training. Experimental results on our LLaMA-structured models indicate that (1) training with only low-precision weights is feasible even when they are constrained to ternary values, (2) extending the bit width to 8 bits results in only a 5% loss degradation compared to BitNet b1.58 while offering the potential for reduced memory usage during training, and (3) our models can also perform inference using ternary weights, showcasing their flexibility in deployment.
MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems
Oct 26, 2021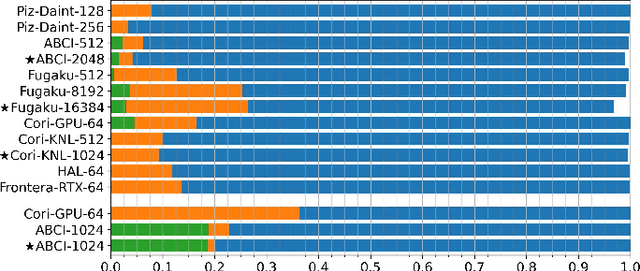
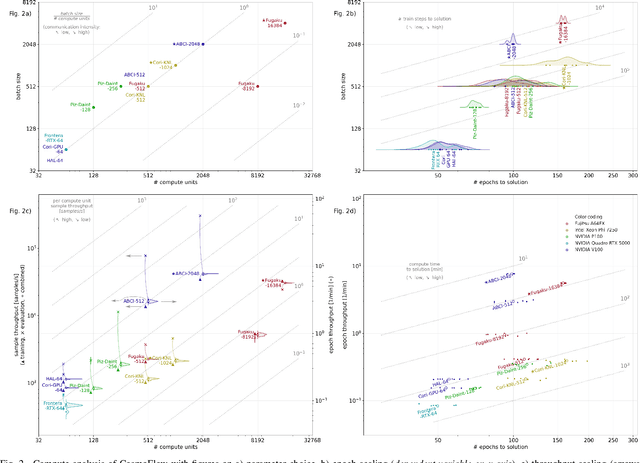
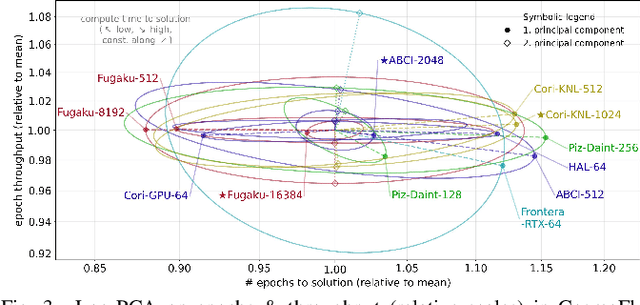
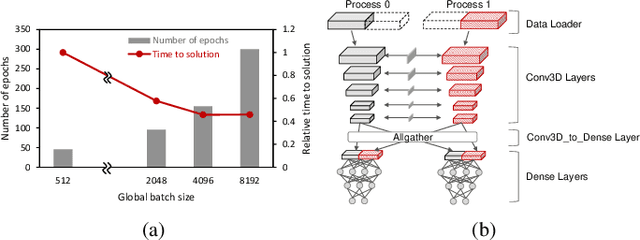
Scientific communities are increasingly adopting machine learning and deep learning models in their applications to accelerate scientific insights. High performance computing systems are pushing the frontiers of performance with a rich diversity of hardware resources and massive scale-out capabilities. There is a critical need to understand fair and effective benchmarking of machine learning applications that are representative of real-world scientific use cases. MLPerf is a community-driven standard to benchmark machine learning workloads, focusing on end-to-end performance metrics. In this paper, we introduce MLPerf HPC, a benchmark suite of large-scale scientific machine learning training applications driven by the MLCommons Association. We present the results from the first submission round, including a diverse set of some of the world's largest HPC systems. We develop a systematic framework for their joint analysis and compare them in terms of data staging, algorithmic convergence, and compute performance. As a result, we gain a quantitative understanding of optimizations on different subsystems such as staging and on-node loading of data, compute-unit utilization, and communication scheduling, enabling overall $>10 \times$ (end-to-end) performance improvements through system scaling. Notably, our analysis shows a scale-dependent interplay between the dataset size, a system's memory hierarchy, and training convergence that underlines the importance of near-compute storage. To overcome the data-parallel scalability challenge at large batch sizes, we discuss specific learning techniques and hybrid data-and-model parallelism that are effective on large systems. We conclude by characterizing each benchmark with respect to low-level memory, I/O, and network behavior to parameterize extended roofline performance models in future rounds.
Yet Another Accelerated SGD: ResNet-50 Training on ImageNet in 74.7 seconds
Mar 29, 2019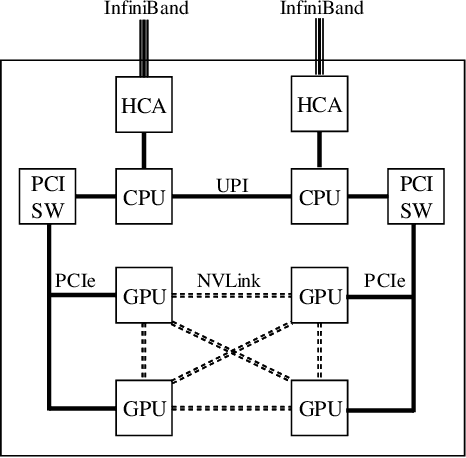
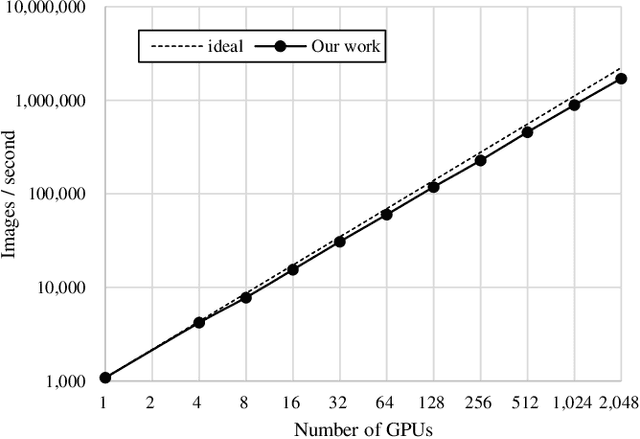
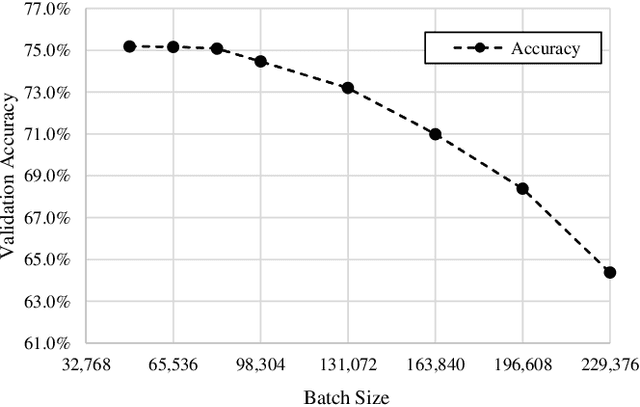
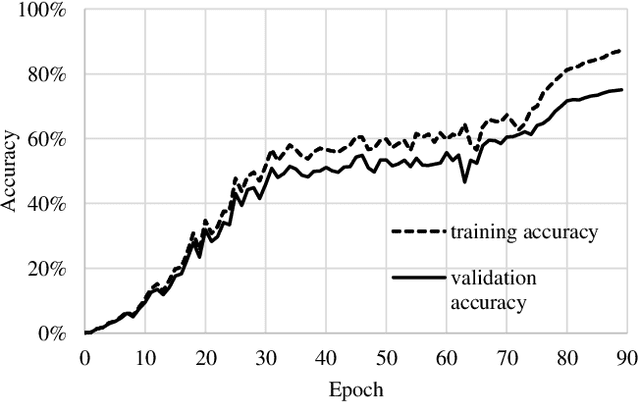
There has been a strong demand for algorithms that can execute machine learning as faster as possible and the speed of deep learning has accelerated by 30 times only in the past two years. Distributed deep learning using the large mini-batch is a key technology to address the demand and is a great challenge as it is difficult to achieve high scalability on large clusters without compromising accuracy. In this paper, we introduce optimization methods which we applied to this challenge. We achieved the training time of 74.7 seconds using 2,048 GPUs on ABCI cluster applying these methods. The training throughput is over 1.73 million images/sec and the top-1 validation accuracy is 75.08%.