 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument Mining as a Text-to-Text Generation Task
Mar 25, 2026Argument Mining(AM) aims to uncover the argumentative structures within a text. Previous methods require several subtasks, such as span identification, component classification, and relation classification. Consequently, these methods need rule-based postprocessing to derive argumentative structures from the output of each subtask. This approach adds to the complexity of the model and expands the search space of the hyperparameters. To address this difficulty, we propose a simple yet strong method based on a text-to-text generation approach using a pretrained encoder-decoder language model. Our method simultaneously generates argumentatively annotated text for spans, components, and relations, eliminating the need for task-specific postprocessing and hyperparameter tuning. Furthermore, because it is a straightforward text-to-text generation method, we can easily adapt our approach to various types of argumentative structures. Experimental results demonstrate the effectiveness of our method, as it achieves state-of-the-art performance on three different types of benchmark datasets: the Argument-annotated Essays Corpus(AAEC), AbstRCT, and the Cornell eRulemaking Corpus(CDCP)
NeoAMT: Neologism-Aware Agentic Machine Translation with Reinforcement Learning
Jan 07, 2026Neologism-aware machine translation aims to translate source sentences containing neologisms into target languages. This field remains underexplored compared with general machine translation (MT). In this paper, we propose an agentic framework, NeoAMT, for neologism-aware machine translation using a Wiktionary search tool. Specifically, we first create a new dataset for neologism-aware machine translation and develop a search tool based on Wiktionary. The new dataset covers 16 languages and 75 translation directions and is derived from approximately 10 million records of an English Wiktionary dump. The retrieval corpus of the search tool is also constructed from around 3 million cleaned records of the Wiktionary dump. We then use it for training the translation agent with reinforcement learning (RL) and evaluating the accuracy of neologism-aware machine translation. Based on this, we also propose an RL training framework that contains a novel reward design and an adaptive rollout generation approach by leveraging "translation difficulty" to further improve the translation quality of translation agents using our search tool.
Case-Based Decision-Theoretic Decoding with Quality Memories
Sep 16, 2025Minimum Bayes risk (MBR) decoding is a decision rule of text generation, which selects the hypothesis that maximizes the expected utility and robustly generates higher-quality texts than maximum a posteriori (MAP) decoding. However, it depends on sample texts drawn from the text generation model; thus, it is difficult to find a hypothesis that correctly captures the knowledge or information of out-of-domain. To tackle this issue, we propose case-based decision-theoretic (CBDT) decoding, another method to estimate the expected utility using examples of domain data. CBDT decoding not only generates higher-quality texts than MAP decoding, but also the combination of MBR and CBDT decoding outperformed MBR decoding in seven domain De--En and Ja$\leftrightarrow$En translation tasks and image captioning tasks on MSCOCO and nocaps datasets.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
Enhancing Translation Accuracy of Large Language Models through Continual Pre-Training on Parallel Data
Jul 03, 2024



In this paper, we propose a two-phase training approach where pre-trained large language models are continually pre-trained on parallel data and then supervised fine-tuned with a small amount of high-quality parallel data. To investigate the effectiveness of our proposed approach, we conducted continual pre-training with a 3.8B-parameter model and parallel data across eight different formats. We evaluate these methods on thirteen test sets for Japanese-to-English and English-to-Japanese translation. The results demonstrate that when utilizing parallel data in continual pre-training, it is essential to alternate between source and target sentences. Additionally, we demonstrated that the translation accuracy improves only for translation directions where the order of source and target sentences aligns between continual pre-training data and inference. In addition, we demonstrate that the LLM-based translation model is more robust in translating spoken language and achieves higher accuracy with less training data compared to supervised encoder-decoder models. We also show that the highest accuracy is achieved when the data for continual pre-training consists of interleaved source and target sentences and when tags are added to the source sentences.
A Japanese-Chinese Parallel Corpus Using Crowdsourcing for Web Mining
May 15, 2024



Using crowdsourcing, we collected more than 10,000 URL pairs (parallel top page pairs) of bilingual websites that contain parallel documents and created a Japanese-Chinese parallel corpus of 4.6M sentence pairs from these websites. We used a Japanese-Chinese bilingual dictionary of 160K word pairs for document and sentence alignment. We then used high-quality 1.2M Japanese-Chinese sentence pairs to train a parallel corpus filter based on statistical language models and word translation probabilities. We compared the translation accuracy of the model trained on these 4.6M sentence pairs with that of the model trained on Japanese-Chinese sentence pairs from CCMatrix (12.4M), a parallel corpus from global web mining. Although our corpus is only one-third the size of CCMatrix, we found that the accuracy of the two models was comparable and confirmed that it is feasible to use crowdsourcing for web mining of parallel data.
Word Alignment as Preference for Machine Translation
May 15, 2024The problem of hallucination and omission, a long-standing problem in machine translation (MT), is more pronounced when a large language model (LLM) is used in MT because an LLM itself is susceptible to these phenomena. In this work, we mitigate the problem in an LLM-based MT model by guiding it to better word alignment. We first study the correlation between word alignment and the phenomena of hallucination and omission in MT. Then we propose to utilize word alignment as preference to optimize the LLM-based MT model. The preference data are constructed by selecting chosen and rejected translations from multiple MT tools. Subsequently, direct preference optimization is used to optimize the LLM-based model towards the preference signal. Given the absence of evaluators specifically designed for hallucination and omission in MT, we further propose selecting hard instances and utilizing GPT-4 to directly evaluate the performance of the models in mitigating these issues. We verify the rationality of these designed evaluation methods by experiments, followed by extensive results demonstrating the effectiveness of word alignment-based preference optimization to mitigate hallucination and omission.
WSPAlign: Word Alignment Pre-training via Large-Scale Weakly Supervised Span Prediction
Jun 09, 2023



Most existing word alignment methods rely on manual alignment datasets or parallel corpora, which limits their usefulness. Here, to mitigate the dependence on manual data, we broaden the source of supervision by relaxing the requirement for correct, fully-aligned, and parallel sentences. Specifically, we make noisy, partially aligned, and non-parallel paragraphs. We then use such a large-scale weakly-supervised dataset for word alignment pre-training via span prediction. Extensive experiments with various settings empirically demonstrate that our approach, which is named WSPAlign, is an effective and scalable way to pre-train word aligners without manual data. When fine-tuned on standard benchmarks, WSPAlign has set a new state-of-the-art by improving upon the best-supervised baseline by 3.3~6.1 points in F1 and 1.5~6.1 points in AER. Furthermore, WSPAlign also achieves competitive performance compared with the corresponding baselines in few-shot, zero-shot and cross-lingual tests, which demonstrates that WSPAlign is potentially more practical for low-resource languages than existing methods.
Domain Adaptation of Machine Translation with Crowdworkers
Oct 28, 2022Although a machine translation model trained with a large in-domain parallel corpus achieves remarkable results, it still works poorly when no in-domain data are available. This situation restricts the applicability of machine translation when the target domain's data are limited. However, there is great demand for high-quality domain-specific machine translation models for many domains. We propose a framework that efficiently and effectively collects parallel sentences in a target domain from the web with the help of crowdworkers. With the collected parallel data, we can quickly adapt a machine translation model to the target domain. Our experiments show that the proposed method can collect target-domain parallel data over a few days at a reasonable cost. We tested it with five domains, and the domain-adapted model improved the BLEU scores to +19.7 by an average of +7.8 points compared to a general-purpose translation model.
A Simple and Strong Baseline for End-to-End Neural RST-style Discourse Parsing
Oct 15, 2022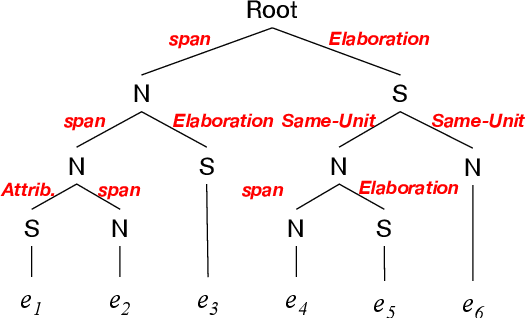

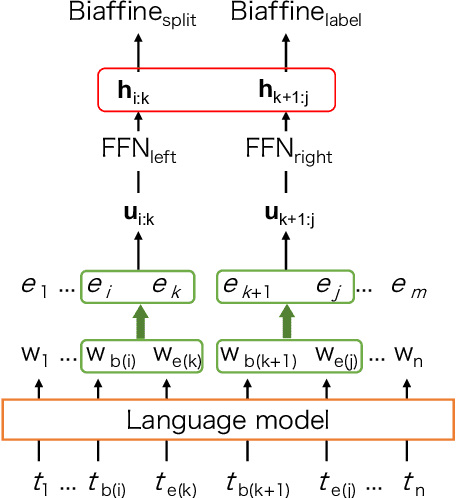
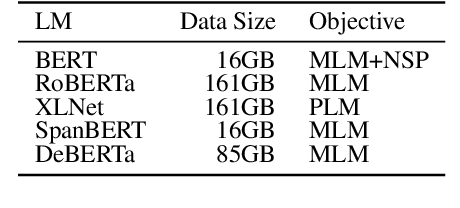
To promote and further develop RST-style discourse parsing models, we need a strong baseline that can be regarded as a reference for reporting reliable experimental results. This paper explores a strong baseline by integrating existing simple parsing strategies, top-down and bottom-up, with various transformer-based pre-trained language models. The experimental results obtained from two benchmark datasets demonstrate that the parsing performance strongly relies on the pretrained language models rather than the parsing strategies. In particular, the bottom-up parser achieves large performance gains compared to the current best parser when employing DeBERTa. We further reveal that language models with a span-masking scheme especially boost the parsing performance through our analysis within intra- and multi-sentential parsing, and nuclearity prediction.