 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBilingual Text Extraction as Reading Comprehension
Paper and Code

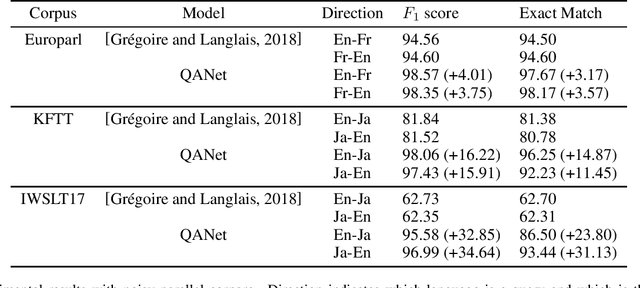
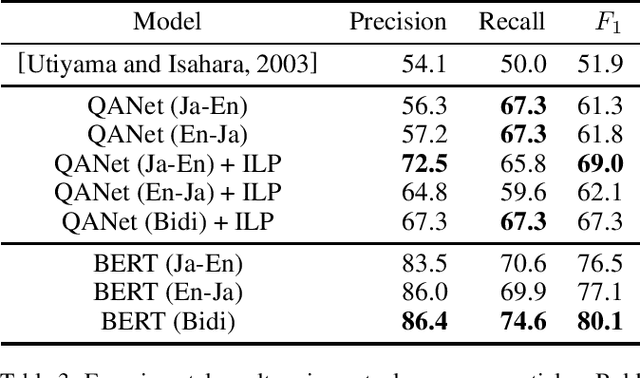
In this paper, we propose a method to extract bilingual texts automatically from noisy parallel corpora by framing the problem as a token-level span prediction, such as SQuAD-style Reading Comprehension. To extract a span of the target document that is a translation of a given source sentence (span), we use either QANet or multilingual BERT. QANet can be trained for a specific parallel corpus from scratch, while multilingual BERT can utilize pre-trained multilingual representations. For the span prediction method using QANet, we introduce a total optimization method using integer linear programming to achieve consistency in the predicted parallel spans. We conduct a parallel sentence extraction experiment using simulated noisy parallel corpora with two language pairs (En-Fr and En-Ja) and find that the proposed method using QANet achieves significantly better accuracy than a baseline method using two bi-directional RNN encoders, particularly for distant language pairs (En-Ja). We also conduct a sentence alignment experiment using En-Ja newspaper articles and find that the proposed method using multilingual BERT achieves significantly better accuracy than a baseline method using a bilingual dictionary and dynamic programming.