 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHacking Neural Evaluation Metrics with Single Hub Text
Dec 18, 2025



Strongly human-correlated evaluation metrics serve as an essential compass for the development and improvement of generation models and must be highly reliable and robust. Recent embedding-based neural text evaluation metrics, such as COMET for translation tasks, are widely used in both research and development fields. However, there is no guarantee that they yield reliable evaluation results due to the black-box nature of neural networks. To raise concerns about the reliability and safety of such metrics, we propose a method for finding a single adversarial text in the discrete space that is consistently evaluated as high-quality, regardless of the test cases, to identify the vulnerabilities in evaluation metrics. The single hub text found with our method achieved 79.1 COMET% and 67.8 COMET% in the WMT'24 English-to-Japanese (En--Ja) and English-to-German (En--De) translation tasks, respectively, outperforming translations generated individually for each source sentence by using M2M100, a general translation model. Furthermore, we also confirmed that the hub text found with our method generalizes across multiple language pairs such as Ja--En and De--En.
A Japanese-Chinese Parallel Corpus Using Crowdsourcing for Web Mining
May 15, 2024



Using crowdsourcing, we collected more than 10,000 URL pairs (parallel top page pairs) of bilingual websites that contain parallel documents and created a Japanese-Chinese parallel corpus of 4.6M sentence pairs from these websites. We used a Japanese-Chinese bilingual dictionary of 160K word pairs for document and sentence alignment. We then used high-quality 1.2M Japanese-Chinese sentence pairs to train a parallel corpus filter based on statistical language models and word translation probabilities. We compared the translation accuracy of the model trained on these 4.6M sentence pairs with that of the model trained on Japanese-Chinese sentence pairs from CCMatrix (12.4M), a parallel corpus from global web mining. Although our corpus is only one-third the size of CCMatrix, we found that the accuracy of the two models was comparable and confirmed that it is feasible to use crowdsourcing for web mining of parallel data.
WikiSplit++: Easy Data Refinement for Split and Rephrase
Apr 13, 2024



The task of Split and Rephrase, which splits a complex sentence into multiple simple sentences with the same meaning, improves readability and enhances the performance of downstream tasks in natural language processing (NLP). However, while Split and Rephrase can be improved using a text-to-text generation approach that applies encoder-decoder models fine-tuned with a large-scale dataset, it still suffers from hallucinations and under-splitting. To address these issues, this paper presents a simple and strong data refinement approach. Here, we create WikiSplit++ by removing instances in WikiSplit where complex sentences do not entail at least one of the simpler sentences and reversing the order of reference simple sentences. Experimental results show that training with WikiSplit++ leads to better performance than training with WikiSplit, even with fewer training instances. In particular, our approach yields significant gains in the number of splits and the entailment ratio, a proxy for measuring hallucinations.
JParaCrawl v3.0: A Large-scale English-Japanese Parallel Corpus
Feb 28, 2022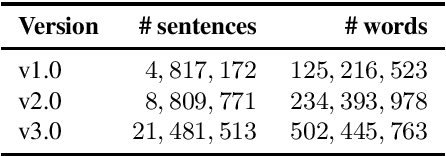

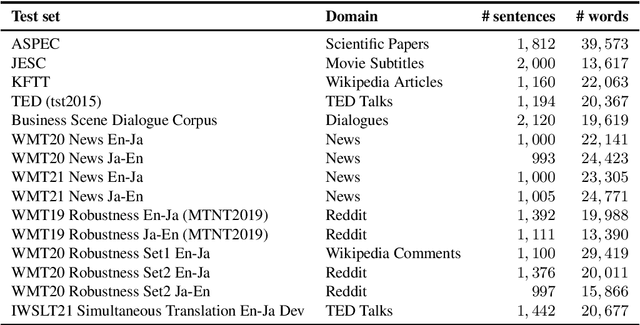
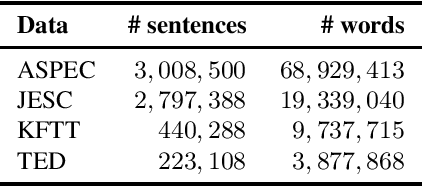
Most current machine translation models are mainly trained with parallel corpora, and their translation accuracy largely depends on the quality and quantity of the corpora. Although there are billions of parallel sentences for a few language pairs, effectively dealing with most language pairs is difficult due to a lack of publicly available parallel corpora. This paper creates a large parallel corpus for English-Japanese, a language pair for which only limited resources are available, compared to such resource-rich languages as English-German. It introduces a new web-based English-Japanese parallel corpus named JParaCrawl v3.0. Our new corpus contains more than 21 million unique parallel sentence pairs, which is more than twice as many as the previous JParaCrawl v2.0 corpus. Through experiments, we empirically show how our new corpus boosts the accuracy of machine translation models on various domains. The JParaCrawl v3.0 corpus will eventually be publicly available online for research purposes.
Input Augmentation Improves Constrained Beam Search for Neural Machine Translation: NTT at WAT 2021
Jun 10, 2021
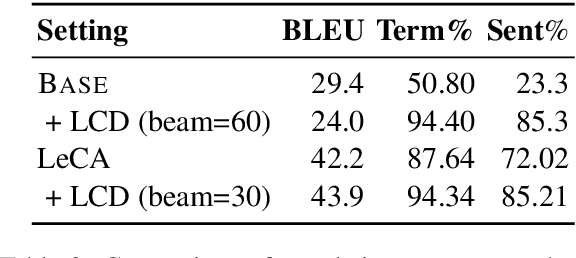
This paper describes our systems that were submitted to the restricted translation task at WAT 2021. In this task, the systems are required to output translated sentences that contain all given word constraints. Our system combined input augmentation and constrained beam search algorithms. Through experiments, we found that this combination significantly improves translation accuracy and can save inference time while containing all the constraints in the output. For both En->Ja and Ja->En, our systems obtained the best evaluation performances in automatic evaluation.
Bilingual Text Extraction as Reading Comprehension
Apr 29, 2020
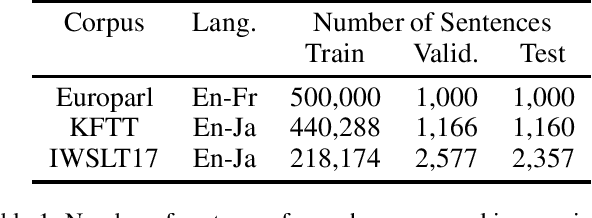
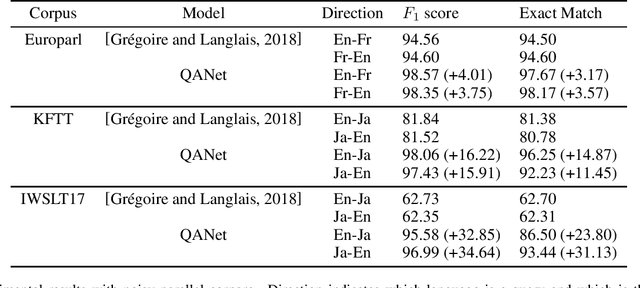
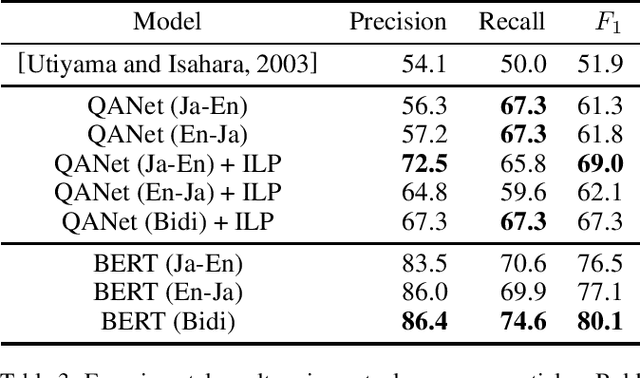
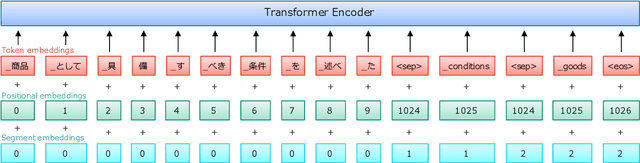
In this paper, we propose a method to extract bilingual texts automatically from noisy parallel corpora by framing the problem as a token-level span prediction, such as SQuAD-style Reading Comprehension. To extract a span of the target document that is a translation of a given source sentence (span), we use either QANet or multilingual BERT. QANet can be trained for a specific parallel corpus from scratch, while multilingual BERT can utilize pre-trained multilingual representations. For the span prediction method using QANet, we introduce a total optimization method using integer linear programming to achieve consistency in the predicted parallel spans. We conduct a parallel sentence extraction experiment using simulated noisy parallel corpora with two language pairs (En-Fr and En-Ja) and find that the proposed method using QANet achieves significantly better accuracy than a baseline method using two bi-directional RNN encoders, particularly for distant language pairs (En-Ja). We also conduct a sentence alignment experiment using En-Ja newspaper articles and find that the proposed method using multilingual BERT achieves significantly better accuracy than a baseline method using a bilingual dictionary and dynamic programming.
Simultaneous Neural Machine Translation using Connectionist Temporal Classification
Nov 27, 2019
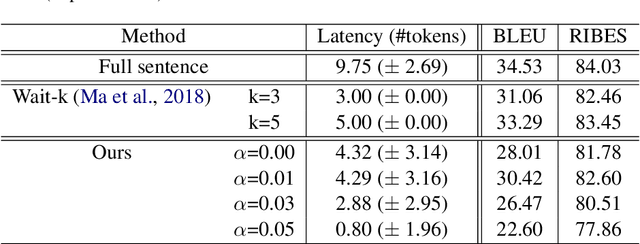


Simultaneous machine translation is a variant of machine translation that starts the translation process before the end of an input. This task faces a trade-off between translation accuracy and latency. We have to determine when we start the translation for observed inputs so far, to achieve good practical performance. In this work, we propose a neural machine translation method to determine this timing in an adaptive manner. The proposed method introduces a special token '<wait>', which is generated when the translation model chooses to read the next input token instead of generating an output token. It also introduces an objective function to handle the ambiguity in wait timings that can be optimized using an algorithm called Connectionist Temporal Classification (CTC). The use of CTC enables the optimization to consider all possible output sequences including '<wait>' that are equivalent to the reference translations and to choose the best one adaptively. We apply the proposed method into simultaneous translation from English to Japanese and investigate its performance and remaining problems.
Training Neural Machine Translation using Word Embedding-based Loss
Jul 30, 2018
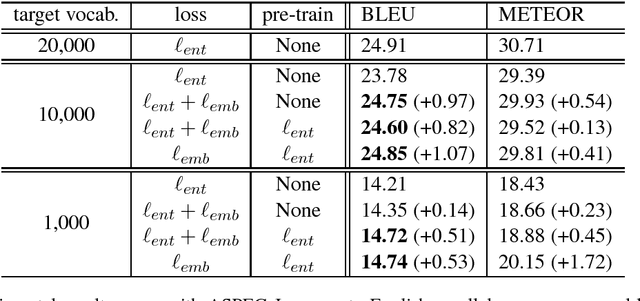
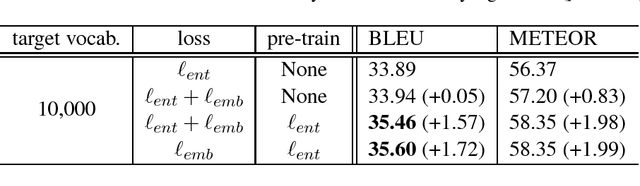
In neural machine translation (NMT), the computational cost at the output layer increases with the size of the target-side vocabulary. Using a limited-size vocabulary instead may cause a significant decrease in translation quality. This trade-off is derived from a softmax-based loss function that handles in-dictionary words independently, in which word similarity is not considered. In this paper, we propose a novel NMT loss function that includes word similarity in forms of distances in a word embedding space. The proposed loss function encourages an NMT decoder to generate words close to their references in the embedding space; this helps the decoder to choose similar acceptable words when the actual best candidates are not included in the vocabulary due to its size limitation. In experiments using ASPEC Japanese-to-English and IWSLT17 English-to-French data sets, the proposed method showed improvements against a standard NMT baseline in both datasets; especially with IWSLT17 En-Fr, it achieved up to +1.72 in BLEU and +1.99 in METEOR. When the target-side vocabulary was very limited to 1,000 words, the proposed method demonstrated a substantial gain, +1.72 in METEOR with ASPEC Ja-En.