 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariance Computation for Weighted Model Counting with Knowledge Compilation Approach
Jan 07, 2026One of the most important queries in knowledge compilation is weighted model counting (WMC), which has been applied to probabilistic inference on various models, such as Bayesian networks. In practical situations on inference tasks, the model's parameters have uncertainty because they are often learned from data, and thus we want to compute the degree of uncertainty in the inference outcome. One possible approach is to regard the inference outcome as a random variable by introducing distributions for the parameters and evaluate the variance of the outcome. Unfortunately, the tractability of computing such a variance is hardly known. Motivated by this, we consider the problem of computing the variance of WMC and investigate this problem's tractability. First, we derive a polynomial time algorithm to evaluate the WMC variance when the input is given as a structured d-DNNF. Second, we prove the hardness of this problem for structured DNNFs, d-DNNFs, and FBDDs, which is intriguing because the latter two allow polynomial time WMC algorithms. Finally, we show an application that measures the uncertainty in the inference of Bayesian networks. We empirically show that our algorithm can evaluate the variance of the marginal probability on real-world Bayesian networks and analyze the impact of the variances of parameters on the variance of the marginal.
Generalization Analysis on Learning with a Concurrent Verifier
Oct 11, 2022


Machine learning technologies have been used in a wide range of practical systems. In practical situations, it is natural to expect the input-output pairs of a machine learning model to satisfy some requirements. However, it is difficult to obtain a model that satisfies requirements by just learning from examples. A simple solution is to add a module that checks whether the input-output pairs meet the requirements and then modifies the model's outputs. Such a module, which we call a {\em concurrent verifier} (CV), can give a certification, although how the generalizability of the machine learning model changes using a CV is unclear. This paper gives a generalization analysis of learning with a CV. We analyze how the learnability of a machine learning model changes with a CV and show a condition where we can obtain a guaranteed hypothesis using a verifier only in the inference time. We also show that typical error bounds based on Rademacher complexity will be no larger than that of the original model when using a CV in multi-class classification and structured prediction settings.
Differentiable Inductive Logic Programming for Structured Examples
Mar 02, 2021
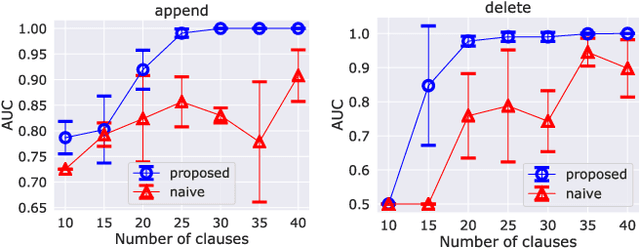
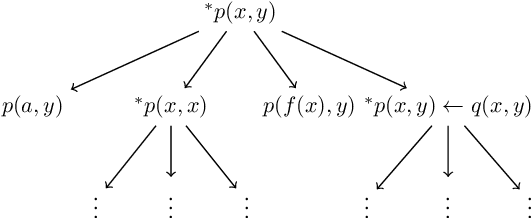
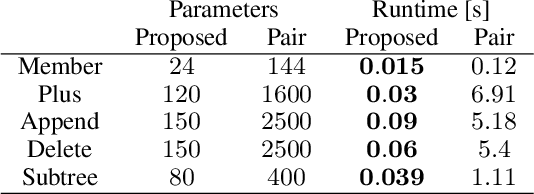
The differentiable implementation of logic yields a seamless combination of symbolic reasoning and deep neural networks. Recent research, which has developed a differentiable framework to learn logic programs from examples, can even acquire reasonable solutions from noisy datasets. However, this framework severely limits expressions for solutions, e.g., no function symbols are allowed, and the shapes of clauses are fixed. As a result, the framework cannot deal with structured examples. Therefore we propose a new framework to learn logic programs from noisy and structured examples, including the following contributions. First, we propose an adaptive clause search method by looking through structured space, which is defined by the generality of the clauses, to yield an efficient search space for differentiable solvers. Second, we propose for ground atoms an enumeration algorithm, which determines a necessary and sufficient set of ground atoms to perform differentiable inference functions. Finally, we propose a new method to compose logic programs softly, enabling the system to deal with complex programs consisting of several clauses. Our experiments show that our new framework can learn logic programs from noisy and structured examples, such as sequences or trees. Our framework can be scaled to deal with complex programs that consist of several clauses with function symbols.
Bilingual Text Extraction as Reading Comprehension
Apr 29, 2020
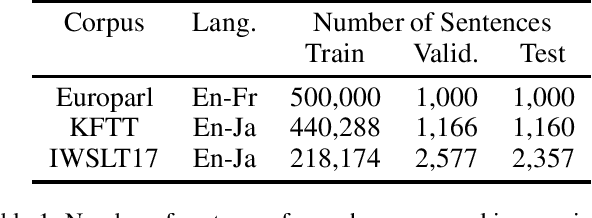
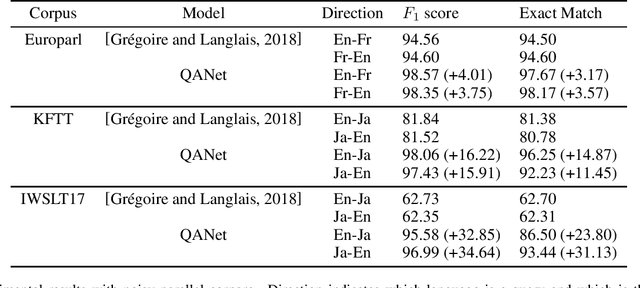
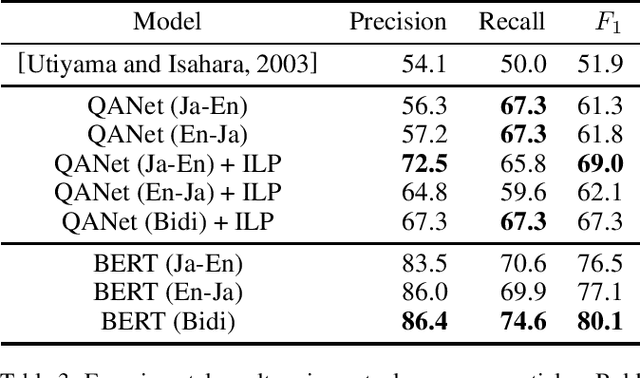
In this paper, we propose a method to extract bilingual texts automatically from noisy parallel corpora by framing the problem as a token-level span prediction, such as SQuAD-style Reading Comprehension. To extract a span of the target document that is a translation of a given source sentence (span), we use either QANet or multilingual BERT. QANet can be trained for a specific parallel corpus from scratch, while multilingual BERT can utilize pre-trained multilingual representations. For the span prediction method using QANet, we introduce a total optimization method using integer linear programming to achieve consistency in the predicted parallel spans. We conduct a parallel sentence extraction experiment using simulated noisy parallel corpora with two language pairs (En-Fr and En-Ja) and find that the proposed method using QANet achieves significantly better accuracy than a baseline method using two bi-directional RNN encoders, particularly for distant language pairs (En-Ja). We also conduct a sentence alignment experiment using En-Ja newspaper articles and find that the proposed method using multilingual BERT achieves significantly better accuracy than a baseline method using a bilingual dictionary and dynamic programming.
A Supervised Word Alignment Method based on Cross-Language Span Prediction using Multilingual BERT
Apr 29, 2020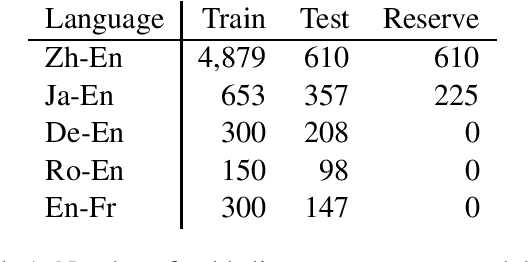
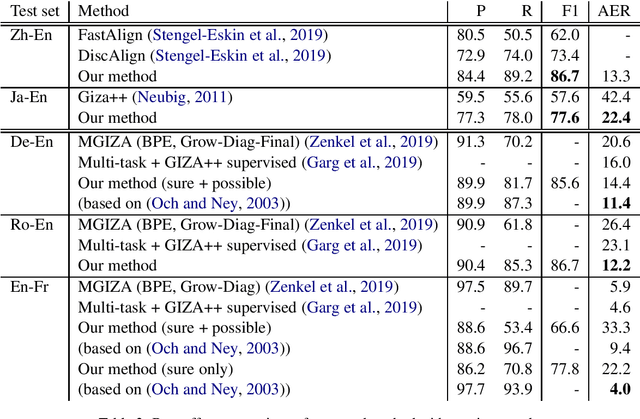
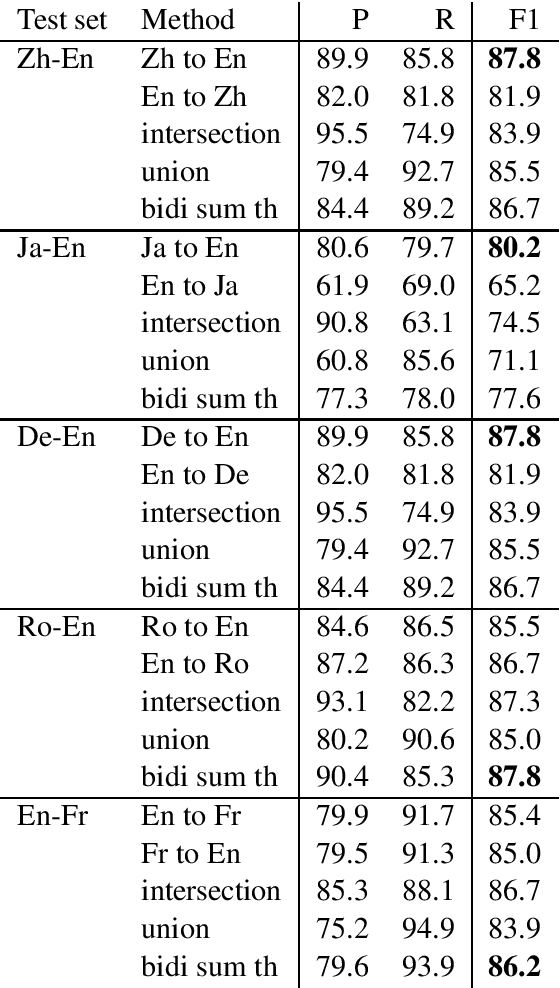
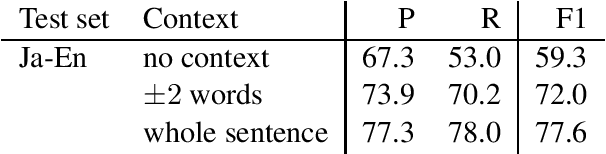
We present a novel supervised word alignment method based on cross-language span prediction. We first formalize a word alignment problem as a collection of independent predictions from a token in the source sentence to a span in the target sentence. As this is equivalent to a SQuAD v2.0 style question answering task, we then solve this problem by using multilingual BERT, which is fine-tuned on a manually created gold word alignment data. We greatly improved the word alignment accuracy by adding the context of the token to the question. In the experiments using five word alignment datasets among Chinese, Japanese, German, Romanian, French, and English, we show that the proposed method significantly outperformed previous supervised and unsupervised word alignment methods without using any bitexts for pretraining. For example, we achieved an F1 score of 86.7 for the Chinese-English data, which is 13.3 points higher than the previous state-of-the-art supervised methods.
Variable Shift SDD: A More Succinct Sentential Decision Diagram
Apr 06, 2020
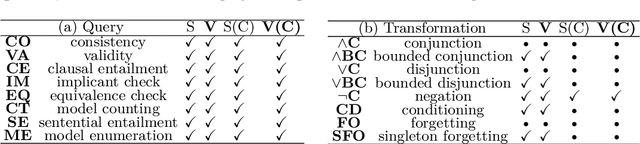
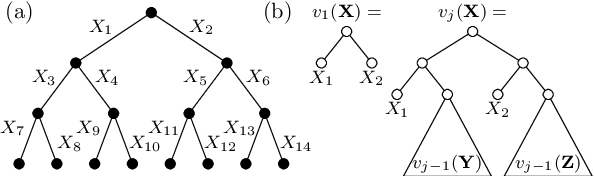
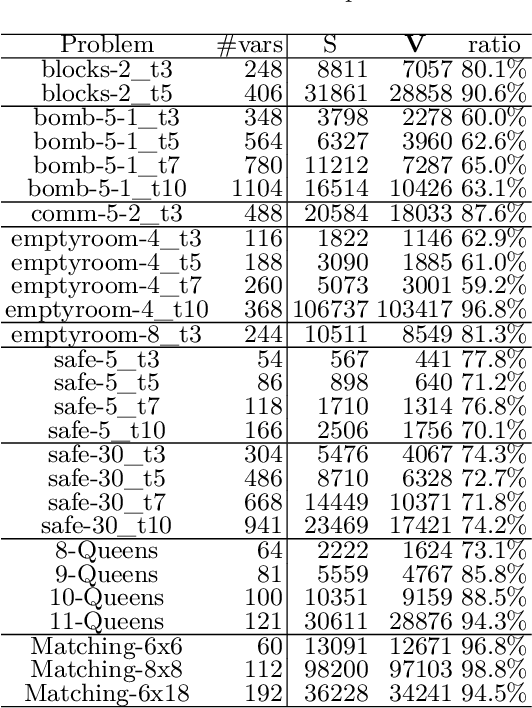
The Sentential Decision Diagram (SDD) is a tractable representation of Boolean functions that subsumes the famous Ordered Binary Decision Diagram (OBDD) as a strict subset. SDDs are attracting much attention because they are more succinct than OBDDs, as well as having canonical forms and supporting many useful queries and transformations such as model counting and Apply operation. In this paper, we propose a more succinct variant of SDD named Variable Shift SDD (VS-SDD). The key idea is to create a unique representation for Boolean functions that are equivalent under a specific variable substitution. We show that VS-SDDs are never larger than SDDs and there are cases in which the size of a VS-SDD is exponentially smaller than that of an SDD. Moreover, despite such succinctness, we show that numerous basic operations that are supported in polytime with SDD are also supported in polytime with VS-SDD. Experiments confirm that VS-SDDs are significantly more succinct than SDDs when applied to classical planning instances, where inherent symmetry exists.
Recovery command generation towards automatic recovery in ICT systems by Seq2Seq learning
Mar 24, 2020

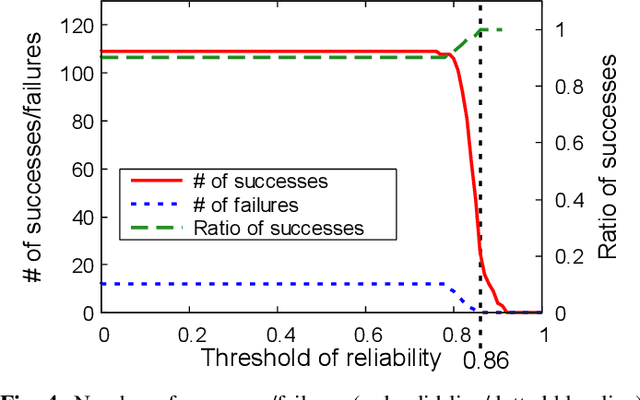
With the increase in scale and complexity of ICT systems, their operation increasingly requires automatic recovery from failures. Although it has become possible to automatically detect anomalies and analyze root causes of failures with current methods, making decisions on what commands should be executed to recover from failures still depends on manual operation, which is quite time-consuming. Toward automatic recovery, we propose a method of estimating recovery commands by using Seq2Seq, a neural network model. This model learns complex relationships between logs obtained from equipment and recovery commands that operators executed in the past. When a new failure occurs, our method estimates plausible commands that recover from the failure on the basis of collected logs. We conducted experiments using a synthetic dataset and realistic OpenStack dataset, demonstrating that our method can estimate recovery commands with high accuracy.
Metric Learning for Ordered Labeled Trees with pq-grams
Mar 09, 2020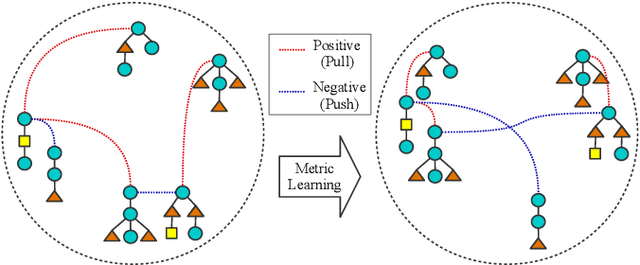
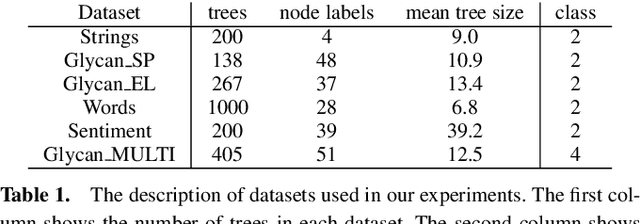

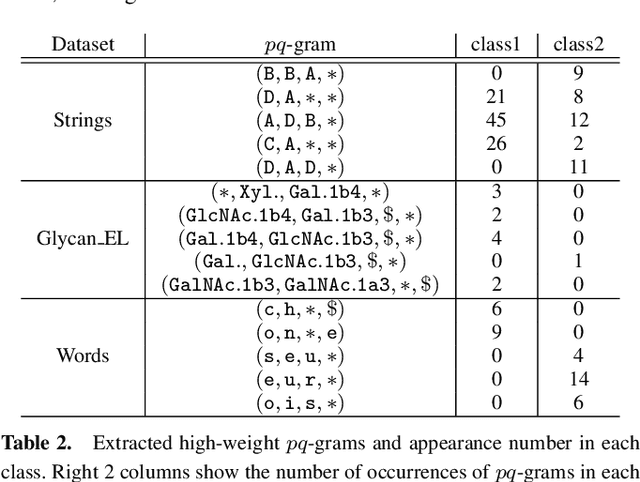
Computing the similarity between two data points plays a vital role in many machine learning algorithms. Metric learning has the aim of learning a good metric automatically from data. Most existing studies on metric learning for tree-structured data have adopted the approach of learning the tree edit distance. However, the edit distance is not amenable for big data analysis because it incurs high computation cost. In this paper, we propose a new metric learning approach for tree-structured data with pq-grams. The pq-gram distance is a distance for ordered labeled trees, and has much lower computation cost than the tree edit distance. In order to perform metric learning based on pq-grams, we propose a new differentiable parameterized distance, weighted pq-gram distance. We also propose a way to learn the proposed distance based on Large Margin Nearest Neighbors (LMNN), which is a well-studied and practical metric learning scheme. We formulate the metric learning problem as an optimization problem and use the gradient descent technique to perform metric learning. We empirically show that the proposed approach not only achieves competitive results with the state-of-the-art edit distance-based methods in various classification problems, but also solves the classification problems much more rapidly than the edit distance-based methods.
Enumeration of Extractive Oracle Summaries
Jan 06, 2017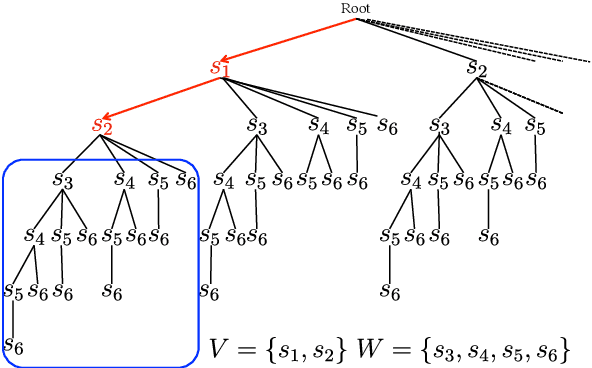
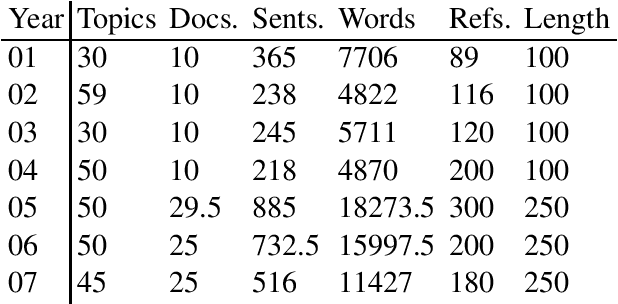
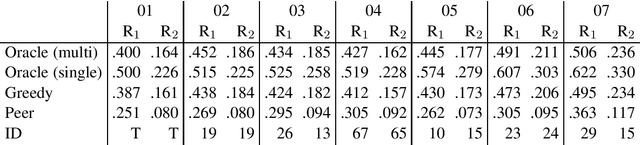
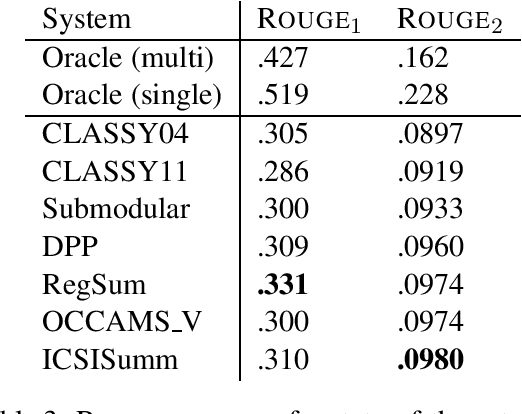
To analyze the limitations and the future directions of the extractive summarization paradigm, this paper proposes an Integer Linear Programming (ILP) formulation to obtain extractive oracle summaries in terms of ROUGE-N. We also propose an algorithm that enumerates all of the oracle summaries for a set of reference summaries to exploit F-measures that evaluate which system summaries contain how many sentences that are extracted as an oracle summary. Our experimental results obtained from Document Understanding Conference (DUC) corpora demonstrated the following: (1) room still exists to improve the performance of extractive summarization; (2) the F-measures derived from the enumerated oracle summaries have significantly stronger correlations with human judgment than those derived from single oracle summaries.