 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Supervised Word Alignment Method based on Cross-Language Span Prediction using Multilingual BERT
Paper and Code
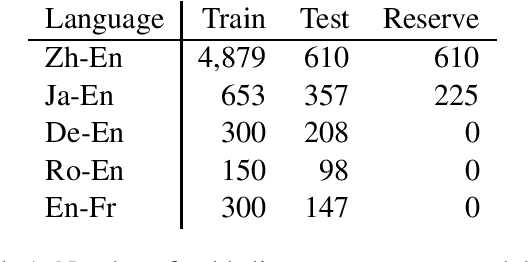
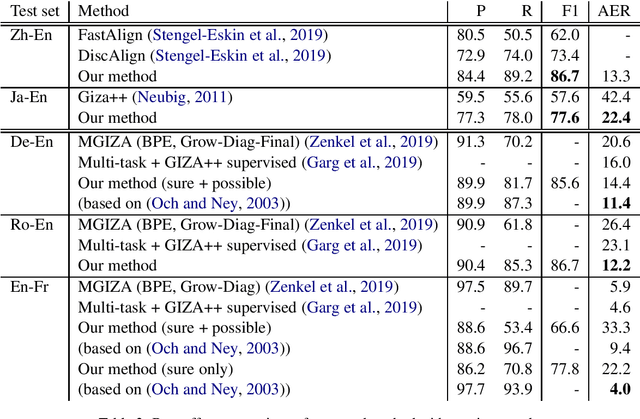
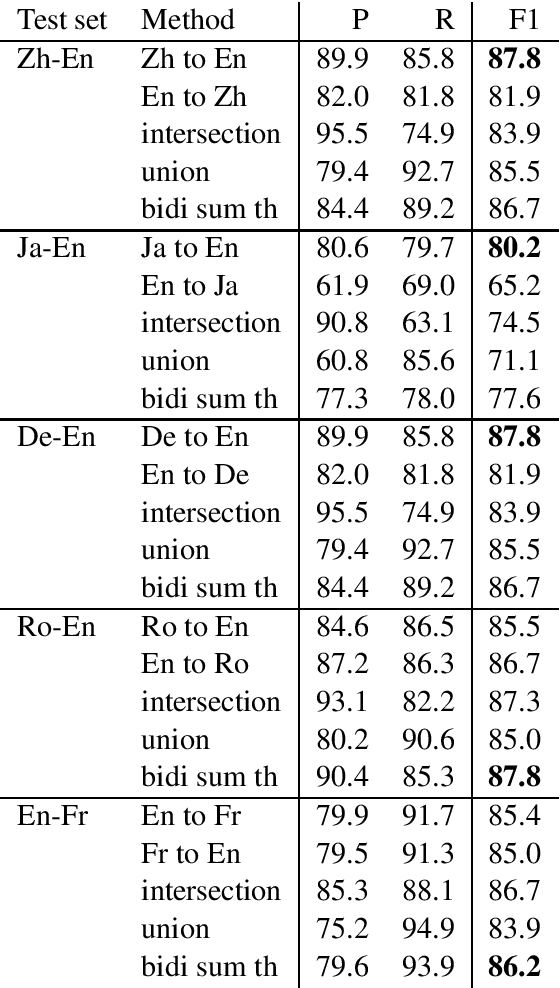
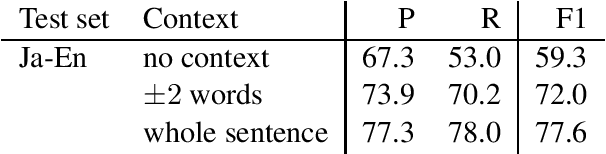
We present a novel supervised word alignment method based on cross-language span prediction. We first formalize a word alignment problem as a collection of independent predictions from a token in the source sentence to a span in the target sentence. As this is equivalent to a SQuAD v2.0 style question answering task, we then solve this problem by using multilingual BERT, which is fine-tuned on a manually created gold word alignment data. We greatly improved the word alignment accuracy by adding the context of the token to the question. In the experiments using five word alignment datasets among Chinese, Japanese, German, Romanian, French, and English, we show that the proposed method significantly outperformed previous supervised and unsupervised word alignment methods without using any bitexts for pretraining. For example, we achieved an F1 score of 86.7 for the Chinese-English data, which is 13.3 points higher than the previous state-of-the-art supervised methods.