 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Relation Extraction and Graph Matching to Answering Multiple Choice Questions
Nov 18, 2025In this research, we combine Transformer-based relation extraction with matching of knowledge graphs (KGs) and apply them to answering multiple-choice questions (MCQs) while maintaining the traceability of the output process. KGs are structured representations of factual knowledge consisting of entities and relations. Due to the high construction cost, they had been regarded as static databases with validated links. However, the recent development of Transformer-based relation extraction (RE) methods has enabled us to generate KGs dynamically by giving them natural language texts, and thereby opened the possibility for representing the meaning of the input sentences with the created KGs. Using this effect, we propose a method that answers MCQs in the "fill-in-the-blank" format, taking care of the point that RE methods generate KGs that represent false information if provided with factually incorrect texts. We measure the truthfulness of each question sentence by (i) converting the sentence into a relational graph using an RE method and (ii) verifying it against factually correct KGs under the closed-world assumption. The experimental results demonstrate that our method correctly answers up to around 70% of the questions, while providing traceability of the procedure. We also highlight that the question category has a vast influence on the accuracy.
Incorporating Coupling Knowledge into Echo State Networks for Learning Spatiotemporally Chaotic Dynamics
Apr 02, 2025



Machine learning methods have shown promise in learning chaotic dynamical systems, enabling model-free short-term prediction and attractor reconstruction. However, when applied to large-scale, spatiotemporally chaotic systems, purely data-driven machine learning methods often suffer from inefficiencies, as they require a large learning model size and a massive amount of training data to achieve acceptable performance. To address this challenge, we incorporate the spatial coupling structure of the target system as an inductive bias in the network design. Specifically, we introduce physics-guided clustered echo state networks, leveraging the efficiency of the echo state networks as a base model. Experimental results on benchmark chaotic systems demonstrate that our physics-informed method outperforms existing echo state network models in learning the target chaotic systems. Additionally, our models exhibit robustness to noise in training data and remain effective even when prior coupling knowledge is imperfect. This approach has the potential to enhance other machine learning methods.
Implementing Derivations of Definite Logic Programs with Self-Attention Networks
Oct 15, 2024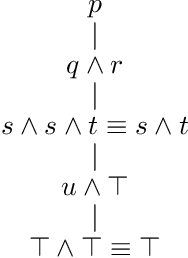
In this paper we propose that a restricted version of logical inference can be implemented with self-attention networks. We are aiming at showing that LLMs (Large Language Models) constructed with transformer networks can make logical inferences. We would reveal the potential of LLMs by analyzing self-attention networks, which are main components of transformer networks. Our approach is not based on semantics of natural languages but operations of logical inference. %point of view. We show that hierarchical constructions of self-attention networks with feed forward networks (FFNs) can implement top-down derivations for a class of logical formulae. We also show bottom-up derivations are also implemented for the same class. We believe that our results show that LLMs implicitly have the power of logical inference.
HTML-LSTM: Information Extraction from HTML Tables in Web Pages using Tree-Structured LSTM
Sep 28, 2024In this paper, we propose a novel method for extracting information from HTML tables with similar contents but with a different structure. We aim to integrate multiple HTML tables into a single table for retrieval of information containing in various Web pages. The method is designed by extending tree-structured LSTM, the neural network for tree-structured data, in order to extract information that is both linguistic and structural information of HTML data. We evaluate the proposed method through experiments using real data published on the WWW.
BERT4FCA: A Method for Bipartite Link Prediction using Formal Concept Analysis and BERT
Feb 13, 2024We propose BERT4FCA, a novel method for link prediction in bipartite networks, using formal concept analysis (FCA) and BERT. Link prediction in bipartite networks is an important task that can solve various practical problems like friend recommendation in social networks and co-authorship prediction in author-paper networks. Recent research has found that in bipartite networks, maximal bi-cliques provide important information for link prediction, and they can be extracted by FCA. Some FCA-based bipartite link prediction methods have achieved good performance. However, we figured out that their performance could be further improved because these methods did not fully capture the rich information of the extracted maximal bi-cliques. To address this limitation, we propose an approach using BERT, which can learn more information from the maximal bi-cliques extracted by FCA and use them to make link prediction. We conduct experiments on three real-world bipartite networks and demonstrate that our method outperforms previous FCA-based methods, and some classic methods such as matrix-factorization and node2vec.
Differentiable Inductive Logic Programming for Structured Examples
Mar 02, 2021
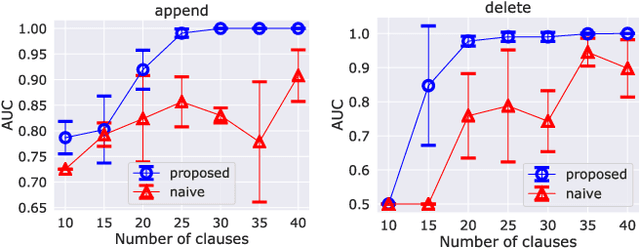
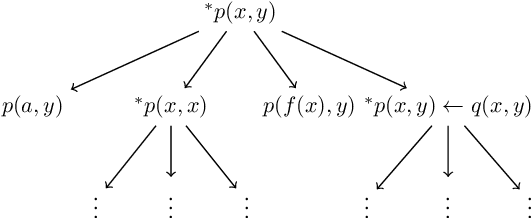
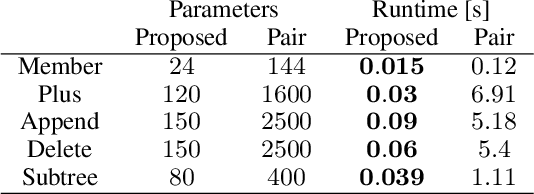
The differentiable implementation of logic yields a seamless combination of symbolic reasoning and deep neural networks. Recent research, which has developed a differentiable framework to learn logic programs from examples, can even acquire reasonable solutions from noisy datasets. However, this framework severely limits expressions for solutions, e.g., no function symbols are allowed, and the shapes of clauses are fixed. As a result, the framework cannot deal with structured examples. Therefore we propose a new framework to learn logic programs from noisy and structured examples, including the following contributions. First, we propose an adaptive clause search method by looking through structured space, which is defined by the generality of the clauses, to yield an efficient search space for differentiable solvers. Second, we propose for ground atoms an enumeration algorithm, which determines a necessary and sufficient set of ground atoms to perform differentiable inference functions. Finally, we propose a new method to compose logic programs softly, enabling the system to deal with complex programs consisting of several clauses. Our experiments show that our new framework can learn logic programs from noisy and structured examples, such as sequences or trees. Our framework can be scaled to deal with complex programs that consist of several clauses with function symbols.
Metric Learning for Ordered Labeled Trees with pq-grams
Mar 09, 2020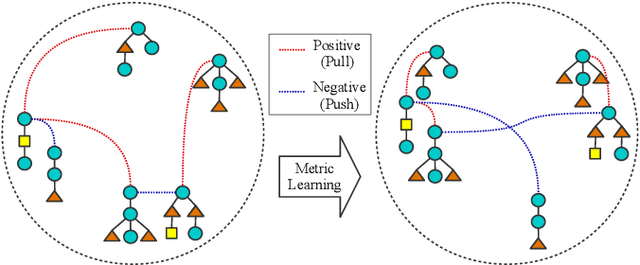

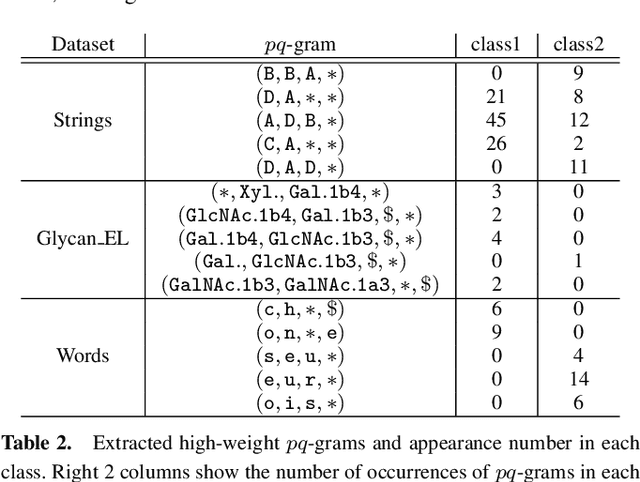
Computing the similarity between two data points plays a vital role in many machine learning algorithms. Metric learning has the aim of learning a good metric automatically from data. Most existing studies on metric learning for tree-structured data have adopted the approach of learning the tree edit distance. However, the edit distance is not amenable for big data analysis because it incurs high computation cost. In this paper, we propose a new metric learning approach for tree-structured data with pq-grams. The pq-gram distance is a distance for ordered labeled trees, and has much lower computation cost than the tree edit distance. In order to perform metric learning based on pq-grams, we propose a new differentiable parameterized distance, weighted pq-gram distance. We also propose a way to learn the proposed distance based on Large Margin Nearest Neighbors (LMNN), which is a well-studied and practical metric learning scheme. We formulate the metric learning problem as an optimization problem and use the gradient descent technique to perform metric learning. We empirically show that the proposed approach not only achieves competitive results with the state-of-the-art edit distance-based methods in various classification problems, but also solves the classification problems much more rapidly than the edit distance-based methods.
Automatic Source Code Summarization with Extended Tree-LSTM
Jun 20, 2019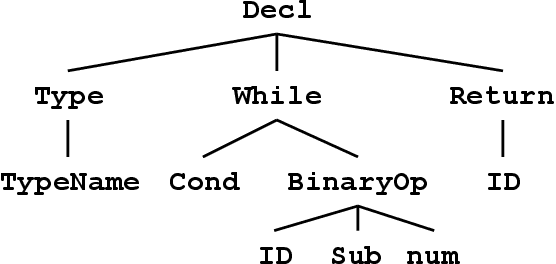
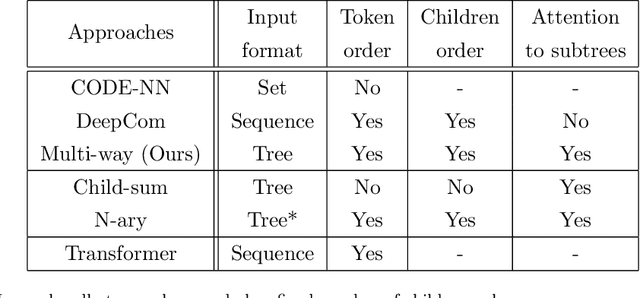
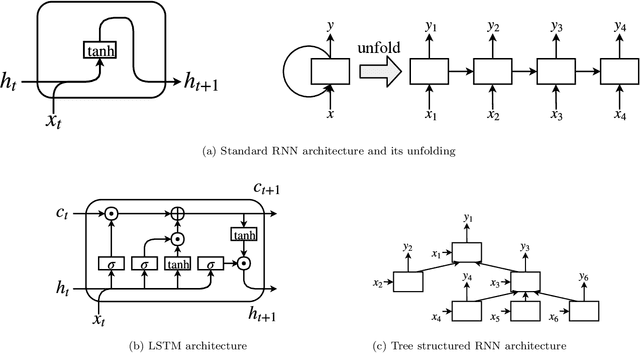

Neural machine translation models are used to automatically generate a document from given source code since this can be regarded as a machine translation task. Source code summarization is one of the components for automatic document generation, which generates a summary in natural language from given source code. This suggests that techniques used in neural machine translation, such as Long Short-Term Memory (LSTM), can be used for source code summarization. However, there is a considerable difference between source code and natural language: Source code is essentially {\em structured}, having loops and conditional branching, etc. Therefore, there is some obstacle to apply known machine translation models to source code. Abstract syntax trees (ASTs) capture these structural properties and play an important role in recent machine learning studies on source code. Tree-LSTM is proposed as a generalization of LSTMs for tree-structured data. However, there is a critical issue when applying it to ASTs: It cannot handle a tree that contains nodes having an arbitrary number of children and their order simultaneously, which ASTs generally have such nodes. To address this issue, we propose an extension of Tree-LSTM, which we call \emph{Multi-way Tree-LSTM} and apply it for source code summarization. As a result of computational experiments, our proposal achieved better results when compared with several state-of-the-art techniques.
Causal Discovery in a Binary Exclusive-or Skew Acyclic Model: BExSAM
Jan 22, 2014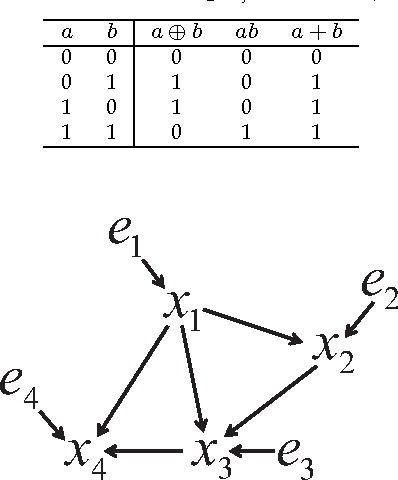


Discovering causal relations among observed variables in a given data set is a major objective in studies of statistics and artificial intelligence. Recently, some techniques to discover a unique causal model have been explored based on non-Gaussianity of the observed data distribution. However, most of these are limited to continuous data. In this paper, we present a novel causal model for binary data and propose an efficient new approach to deriving the unique causal model governing a given binary data set under skew distributions of external binary noises. Experimental evaluation shows excellent performance for both artificial and real world data sets.
Discovering causal structures in binary exclusive-or skew acyclic models
Feb 14, 2012
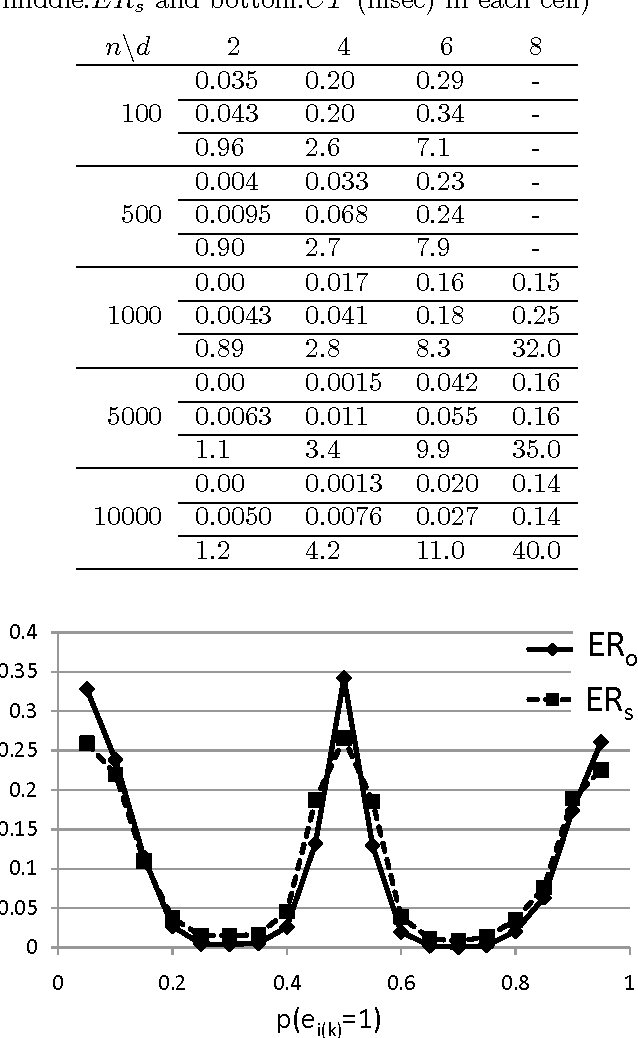
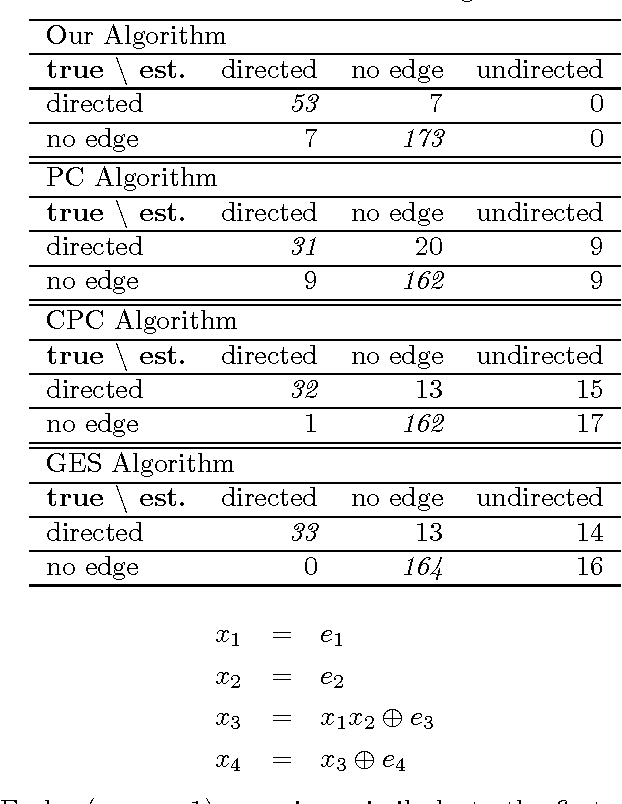
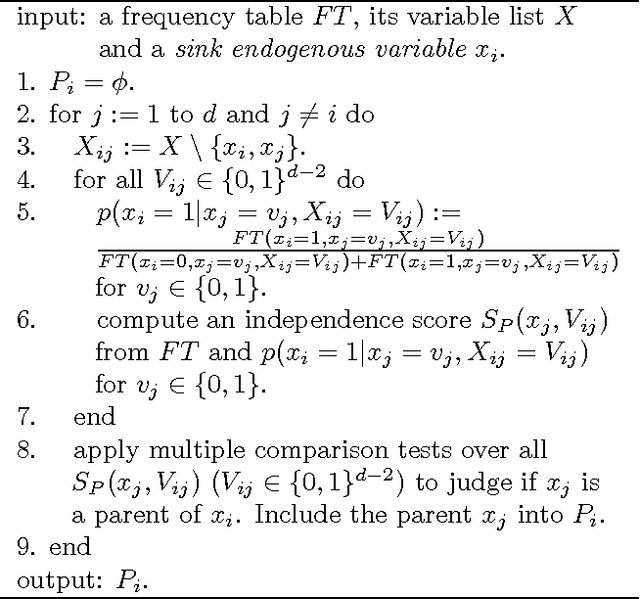
Discovering causal relations among observed variables in a given data set is a main topic in studies of statistics and artificial intelligence. Recently, some techniques to discover an identifiable causal structure have been explored based on non-Gaussianity of the observed data distribution. However, most of these are limited to continuous data. In this paper, we present a novel causal model for binary data and propose a new approach to derive an identifiable causal structure governing the data based on skew Bernoulli distributions of external noise. Experimental evaluation shows excellent performance for both artificial and real world data sets.