 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementing Derivations of Definite Logic Programs with Self-Attention Networks
Paper and Code
Oct 15, 2024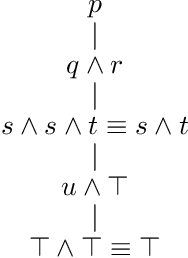
In this paper we propose that a restricted version of logical inference can be implemented with self-attention networks. We are aiming at showing that LLMs (Large Language Models) constructed with transformer networks can make logical inferences. We would reveal the potential of LLMs by analyzing self-attention networks, which are main components of transformer networks. Our approach is not based on semantics of natural languages but operations of logical inference. %point of view. We show that hierarchical constructions of self-attention networks with feed forward networks (FFNs) can implement top-down derivations for a class of logical formulae. We also show bottom-up derivations are also implemented for the same class. We believe that our results show that LLMs implicitly have the power of logical inference.