 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgee-person Architecture and Framework for Human-AI Co-adventure Relationship
Mar 28, 2025This paper proposes the e-person architecture for constructing a unified and incremental development of AI ethics. The e-person architecture takes the reduction of uncertainty through collaborative cognition and action with others as a unified basis for ethics. By classifying and defining uncertainty along two axes - (1) first, second, and third person perspectives, and (2) the difficulty of inference based on the depth of information - we support the development of unified and incremental development of AI ethics. In addition, we propose the e-person framework based on the free energy principle, which considers the reduction of uncertainty as a unifying principle of brain function, with the aim of implementing the e-person architecture, and we show our previous works and future challenges based on the proposed framework.
Environment-Centric Active Inference
Aug 23, 2024



To handle unintended changes in the environment by agents, we propose an environment-centric active inference EC-AIF in which the Markov Blanket of active inference is defined starting from the environment. In normal active inference, the Markov Blanket is defined starting from the agent. That is, first the agent was defined as the entity that performs the "action" such as a robot or a person, then the environment was defined as other people or objects that are directly affected by the agent's "action," and the boundary between the agent and the environment was defined as the Markov Blanket. This agent-centric definition does not allow the agent to respond to unintended changes in the environment caused by factors outside of the defined environment. In the proposed EC-AIF, there is no entity corresponding to an agent. The environment includes all observable things, including people and things conventionally considered to be the environment, as well as entities that perform "actions" such as robots and people. Accordingly, all states, including robots and people, are included in inference targets, eliminating unintended changes in the environment. The EC-AIF was applied to a robot arm and validated with an object transport task by the robot arm. The results showed that the robot arm successfully transported objects while responding to changes in the target position of the object and to changes in the orientation of another robot arm.
Response Style Characterization for Repeated Measures Using the Visual Analogue Scale
Mar 15, 2024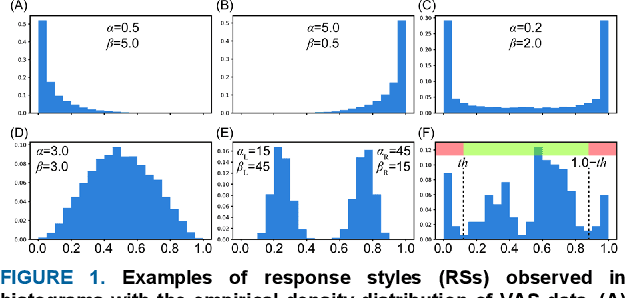

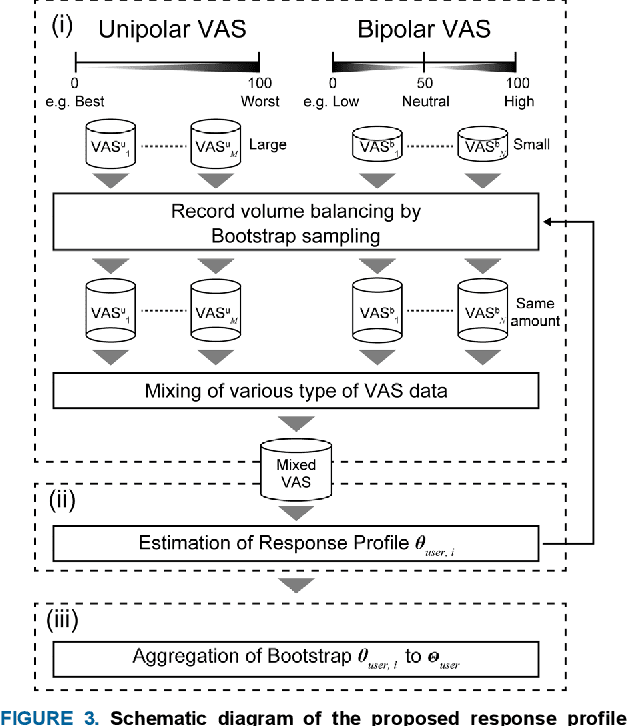
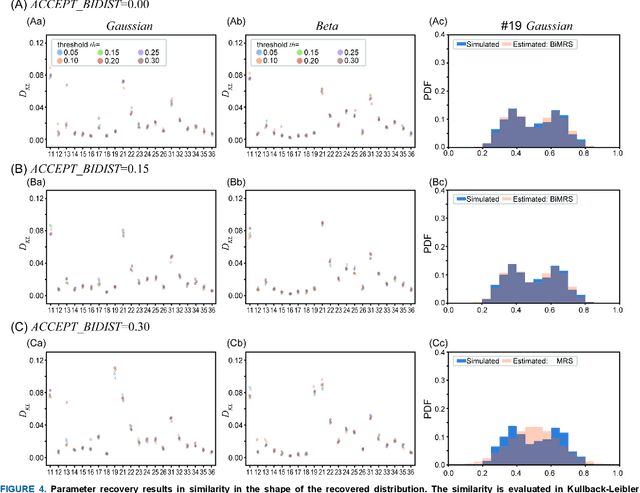
Self-report measures (e.g., Likert scales) are widely used to evaluate subjective health perceptions. Recently, the visual analog scale (VAS), a slider-based scale, has become popular owing to its ability to precisely and easily assess how people feel. These data can be influenced by the response style (RS), a user-dependent systematic tendency that occurs regardless of questionnaire instructions. Despite its importance, especially in between-individual analysis, little attention has been paid to handling the RS in the VAS (denoted as response profile (RP)), as it is mainly used for within-individual monitoring and is less affected by RP. However, VAS measurements often require repeated self-reports of the same questionnaire items, making it difficult to apply conventional methods on a Likert scale. In this study, we developed a novel RP characterization method for various types of repeatedly measured VAS data. This approach involves the modeling of RP as distributional parameters ${\theta}$ through a mixture of RS-like distributions, and addressing the issue of unbalanced data through bootstrap sampling for treating repeated measures. We assessed the effectiveness of the proposed method using simulated pseudo-data and an actual dataset from an empirical study. The assessment of parameter recovery showed that our method accurately estimated the RP parameter ${\theta}$, demonstrating its robustness. Moreover, applying our method to an actual VAS dataset revealed the presence of individual RP heterogeneity, even in repeated VAS measurements, similar to the findings of the Likert scale. Our proposed method enables RP heterogeneity-aware VAS data analysis, similar to Likert-scale data analysis.
The impact of individual information exchange strategies on the distribution of social wealth
Apr 02, 2023



Wealth distribution is a complex and critical aspect of any society. Information exchange is considered to have played a role in shaping wealth distribution patterns, but the specific dynamic mechanism is still unclear. In this research, we used simulation-based methods to investigate the impact of different modes of information exchange on wealth distribution. We compared different combinations of information exchange strategies and moving strategies, analyzed their impact on wealth distribution using classic wealth distribution indicators such as the Gini coefficient. Our findings suggest that information exchange strategies have significant impact on wealth distribution and that promoting more equitable access to information and resources is crucial in building a just and equitable society for all.
Mask Atari for Deep Reinforcement Learning as POMDP Benchmarks
Mar 31, 2022
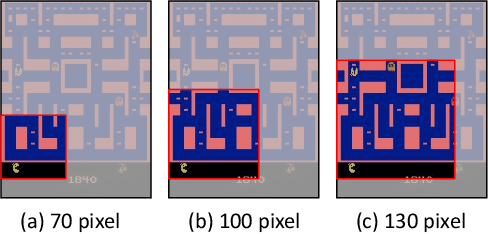
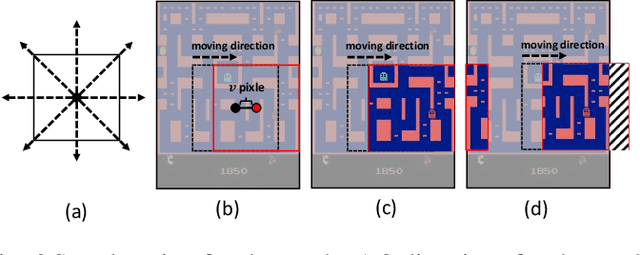
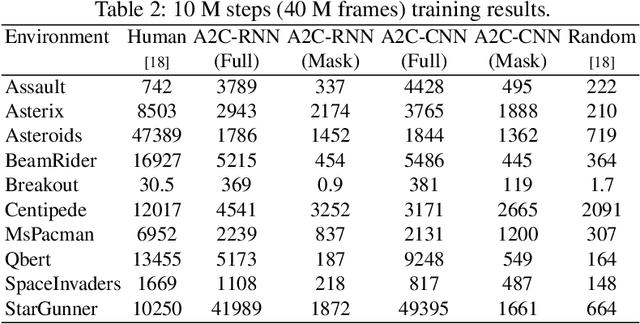
We present Mask Atari, a new benchmark to help solve partially observable Markov decision process (POMDP) problems with Deep Reinforcement Learning (DRL)-based approaches. To achieve a simulation environment for the POMDP problems, Mask Atari is constructed based on Atari 2600 games with controllable, moveable, and learnable masks as the observation area for the target agent, especially with the active information gathering (AIG) setting in POMDPs. Given that one does not yet exist, Mask Atari provides a challenging, efficient benchmark for evaluating the methods that focus on the above problem. Moreover, the mask operation is a trial for introducing the receptive field in the human vision system into a simulation environment for an agent, which means the evaluations are not biased from the sensing ability and purely focus on the cognitive performance of the methods when compared with the human baseline. We describe the challenges and features of our benchmark and evaluate several baselines with Mask Atari.
Sensorimotor Visual Perception on Embodied System Using Free Energy Principle
Jun 11, 2020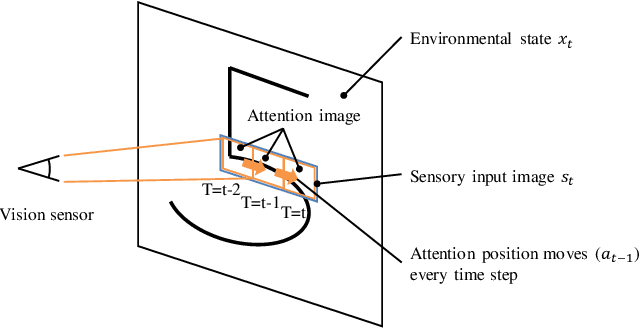
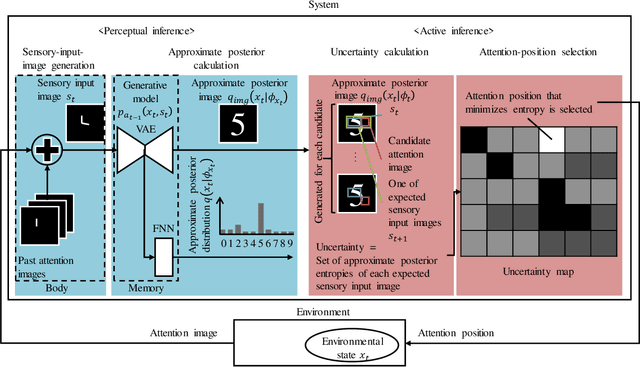
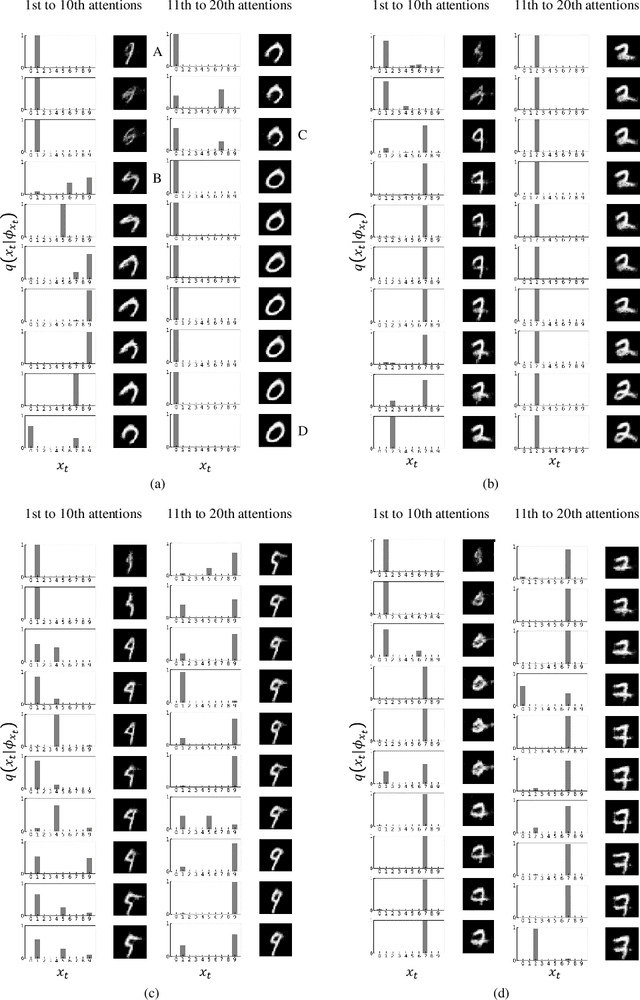

We propose an embodied system based on the free energy principle (FEP) for sensorimotor visual perception. We evaluated it in a character-recognition task using the MNIST dataset. Although the FEP has successfully described a rule that living things obey mathematically and claims that a biological system continues to change its internal models and behaviors to minimize the difference in predicting sensory input, it is not enough to model sensorimotor visual perception. An embodiment of the system is the key to achieving sensorimotor visual perception. The proposed embodied system is configured by a body and memory. The body has an ocular motor system controlling the direction of eye gaze, which means that the eye can only observe a small focused area of the environment. The memory is not photographic, but is a generative model implemented with a variational autoencoder that contains prior knowledge about the environment, and that knowledge is classified. By limiting body and memory abilities and operating according to the FEP, the embodied system repeatedly takes action to obtain the next sensory input based on various potentials of future sensory inputs. In the evaluation, the inference of the environment was represented as an approximate posterior distribution of characters (0 - 9). As the number of repetitions increased, the attention area moved continuously, gradually reducing the uncertainty of characters. Finally, the probability of the correct character became the highest among the characters. Changing the initial attention position provides a different final distribution, suggesting that the proposed system has a confirmation bias.
Automatic Source Code Summarization with Extended Tree-LSTM
Jun 20, 2019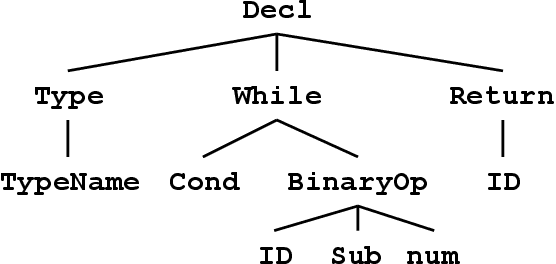
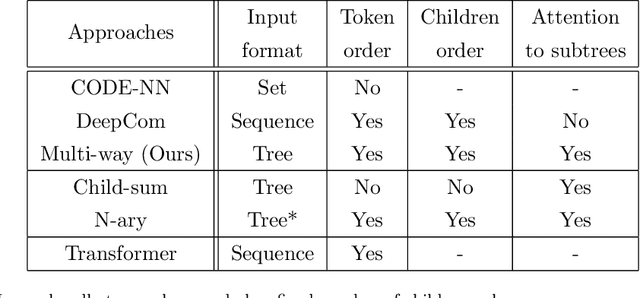
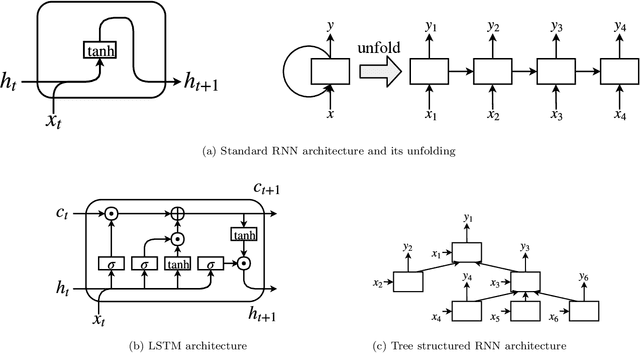

Neural machine translation models are used to automatically generate a document from given source code since this can be regarded as a machine translation task. Source code summarization is one of the components for automatic document generation, which generates a summary in natural language from given source code. This suggests that techniques used in neural machine translation, such as Long Short-Term Memory (LSTM), can be used for source code summarization. However, there is a considerable difference between source code and natural language: Source code is essentially {\em structured}, having loops and conditional branching, etc. Therefore, there is some obstacle to apply known machine translation models to source code. Abstract syntax trees (ASTs) capture these structural properties and play an important role in recent machine learning studies on source code. Tree-LSTM is proposed as a generalization of LSTMs for tree-structured data. However, there is a critical issue when applying it to ASTs: It cannot handle a tree that contains nodes having an arbitrary number of children and their order simultaneously, which ASTs generally have such nodes. To address this issue, we propose an extension of Tree-LSTM, which we call \emph{Multi-way Tree-LSTM} and apply it for source code summarization. As a result of computational experiments, our proposal achieved better results when compared with several state-of-the-art techniques.