 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask Atari for Deep Reinforcement Learning as POMDP Benchmarks
Mar 31, 2022
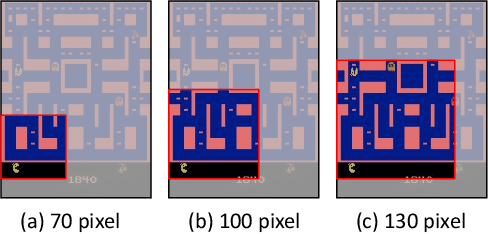
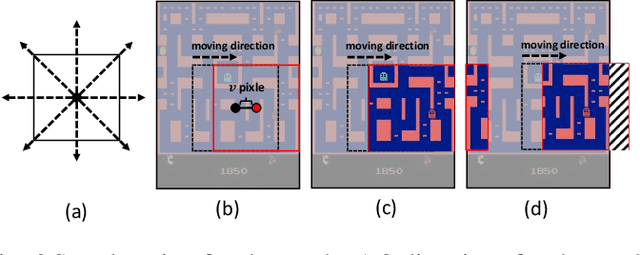
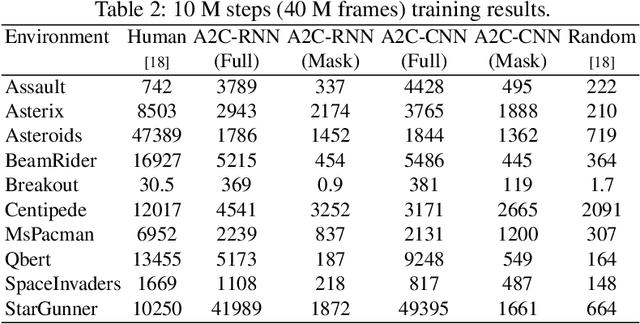
We present Mask Atari, a new benchmark to help solve partially observable Markov decision process (POMDP) problems with Deep Reinforcement Learning (DRL)-based approaches. To achieve a simulation environment for the POMDP problems, Mask Atari is constructed based on Atari 2600 games with controllable, moveable, and learnable masks as the observation area for the target agent, especially with the active information gathering (AIG) setting in POMDPs. Given that one does not yet exist, Mask Atari provides a challenging, efficient benchmark for evaluating the methods that focus on the above problem. Moreover, the mask operation is a trial for introducing the receptive field in the human vision system into a simulation environment for an agent, which means the evaluations are not biased from the sensing ability and purely focus on the cognitive performance of the methods when compared with the human baseline. We describe the challenges and features of our benchmark and evaluate several baselines with Mask Atari.
Sensorimotor Visual Perception on Embodied System Using Free Energy Principle
Jun 11, 2020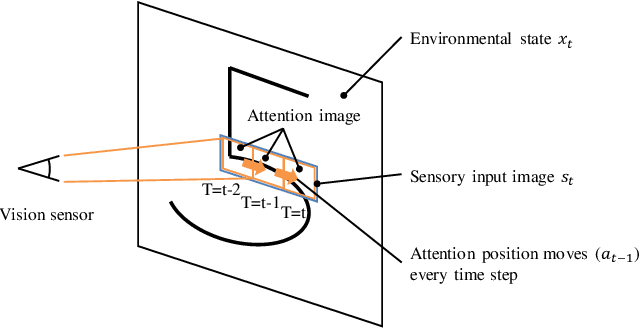
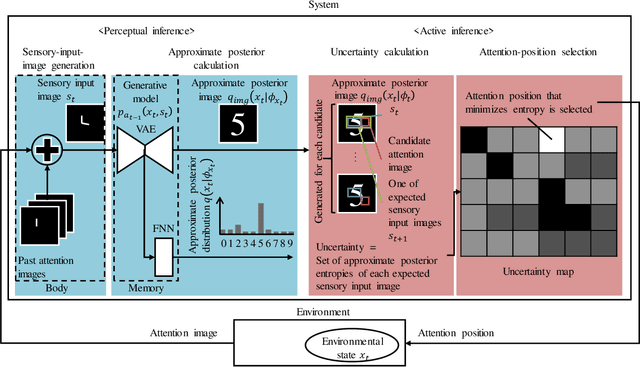
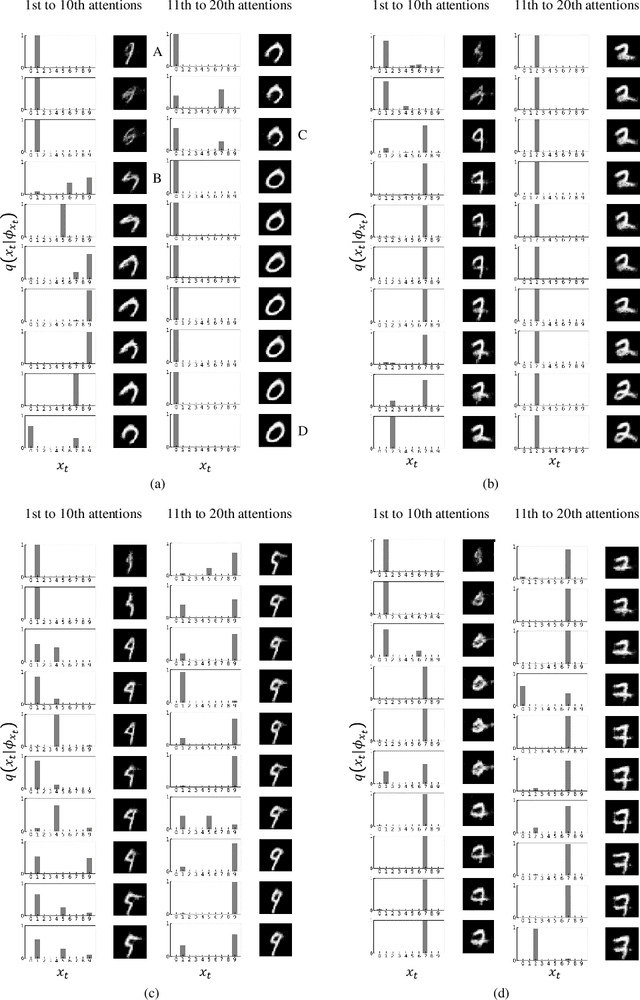

We propose an embodied system based on the free energy principle (FEP) for sensorimotor visual perception. We evaluated it in a character-recognition task using the MNIST dataset. Although the FEP has successfully described a rule that living things obey mathematically and claims that a biological system continues to change its internal models and behaviors to minimize the difference in predicting sensory input, it is not enough to model sensorimotor visual perception. An embodiment of the system is the key to achieving sensorimotor visual perception. The proposed embodied system is configured by a body and memory. The body has an ocular motor system controlling the direction of eye gaze, which means that the eye can only observe a small focused area of the environment. The memory is not photographic, but is a generative model implemented with a variational autoencoder that contains prior knowledge about the environment, and that knowledge is classified. By limiting body and memory abilities and operating according to the FEP, the embodied system repeatedly takes action to obtain the next sensory input based on various potentials of future sensory inputs. In the evaluation, the inference of the environment was represented as an approximate posterior distribution of characters (0 - 9). As the number of repetitions increased, the attention area moved continuously, gradually reducing the uncertainty of characters. Finally, the probability of the correct character became the highest among the characters. Changing the initial attention position provides a different final distribution, suggesting that the proposed system has a confirmation bias.