 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuri: Japanese General Text Embeddings
Sep 12, 2024We report the development of Ruri, a series of Japanese general text embedding models. While the development of general-purpose text embedding models in English and multilingual contexts has been active in recent years, model development in Japanese remains insufficient. The primary reasons for this are the lack of datasets and the absence of necessary expertise. In this report, we provide a detailed account of the development process of Ruri. Specifically, we discuss the training of embedding models using synthesized datasets generated by LLMs, the construction of the reranker for dataset filtering and knowledge distillation, and the performance evaluation of the resulting general-purpose text embedding models.
WikiSplit++: Easy Data Refinement for Split and Rephrase
Apr 13, 2024The task of Split and Rephrase, which splits a complex sentence into multiple simple sentences with the same meaning, improves readability and enhances the performance of downstream tasks in natural language processing (NLP). However, while Split and Rephrase can be improved using a text-to-text generation approach that applies encoder-decoder models fine-tuned with a large-scale dataset, it still suffers from hallucinations and under-splitting. To address these issues, this paper presents a simple and strong data refinement approach. Here, we create WikiSplit++ by removing instances in WikiSplit where complex sentences do not entail at least one of the simpler sentences and reversing the order of reference simple sentences. Experimental results show that training with WikiSplit++ leads to better performance than training with WikiSplit, even with fewer training instances. In particular, our approach yields significant gains in the number of splits and the entailment ratio, a proxy for measuring hallucinations.
Improving Sentence Embeddings with an Automatically Generated NLI Dataset
Feb 23, 2024



Decoder-based large language models (LLMs) have shown high performance on many tasks in natural language processing. This is also true for sentence embedding learning, where a decoder-based model, PromptEOL, has achieved the best performance on semantic textual similarity (STS) tasks. However, PromptEOL makes great use of fine-tuning with a manually annotated natural language inference (NLI) dataset. We aim to improve sentence embeddings learned in an unsupervised setting by automatically generating an NLI dataset with an LLM and using it to fine-tune PromptEOL. In experiments on STS tasks, the proposed method achieved an average Spearman's rank correlation coefficient of 82.21 with respect to human evaluation, thus outperforming existing methods without using large, manually annotated datasets.
Japanese SimCSE Technical Report
Oct 30, 2023



We report the development of Japanese SimCSE, Japanese sentence embedding models fine-tuned with SimCSE. Since there is a lack of sentence embedding models for Japanese that can be used as a baseline in sentence embedding research, we conducted extensive experiments on Japanese sentence embeddings involving 24 pre-trained Japanese or multilingual language models, five supervised datasets, and four unsupervised datasets. In this report, we provide the detailed training setup for Japanese SimCSE and their evaluation results.
Sentence Representations via Gaussian Embedding
May 22, 2023


Recent progress in sentence embedding, which represents the meaning of a sentence as a point in a vector space, has achieved high performance on tasks such as a semantic textual similarity (STS) task. However, sentence representations as a point in a vector space can express only a part of the diverse information that sentences have, such as asymmetrical relationships between sentences. This paper proposes GaussCSE, a Gaussian distribution-based contrastive learning framework for sentence embedding that can handle asymmetric relationships between sentences, along with a similarity measure for identifying inclusion relations. Our experiments show that GaussCSE achieves the same performance as previous methods in natural language inference tasks, and is able to estimate the direction of entailment relations, which is difficult with point representations.
Comparison and Combination of Sentence Embeddings Derived from Different Supervision Signals
Feb 07, 2022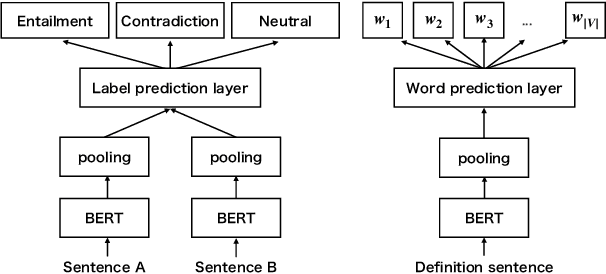


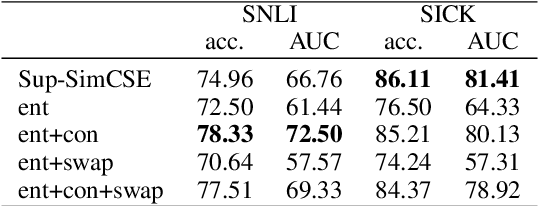
We have recently seen many successful applications of sentence embedding methods. It has not been well understood, however, what kind of properties are captured in the resulting sentence embeddings, depending on the supervision signals. In this paper, we focus on two types of sentence embeddings obtained by using natural language inference (NLI) datasets and definition sentences from a word dictionary and investigate their properties by comparing their performance with the semantic textual similarity (STS) task using the STS data partitioned by two perspectives: 1) the sources of sentences, and 2) the superficial similarity of the sentence pairs, and their performance on the downstream and probing tasks. We also demonstrate that combining the two types of embeddings yields substantially better performances than respective models on unsupervised STS tasks and downstream tasks.
DefSent: Sentence Embeddings using Definition Sentences
May 11, 2021
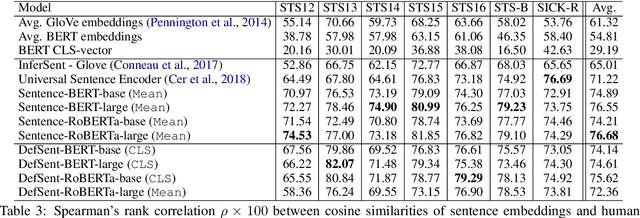
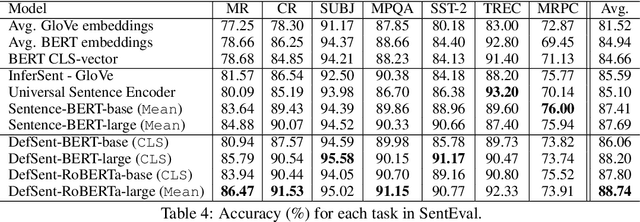
Sentence embedding methods using natural language inference (NLI) datasets have been successfully applied to various tasks. However, these methods are only available for limited languages due to relying heavily on the large NLI datasets. In this paper, we propose DefSent, a sentence embedding method that uses definition sentences from a word dictionary. Since dictionaries are available for many languages, DefSent is more broadly applicable than methods using NLI datasets without constructing additional datasets. We demonstrate that DefSent performs comparably on unsupervised semantics textual similarity (STS) tasks and slightly better on SentEval tasks to the methods using large NLI datasets.