 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison and Combination of Sentence Embeddings Derived from Different Supervision Signals
Paper and Code
Feb 07, 2022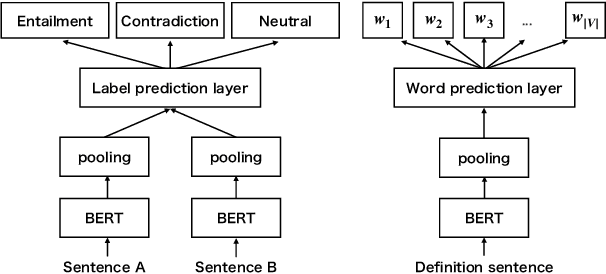
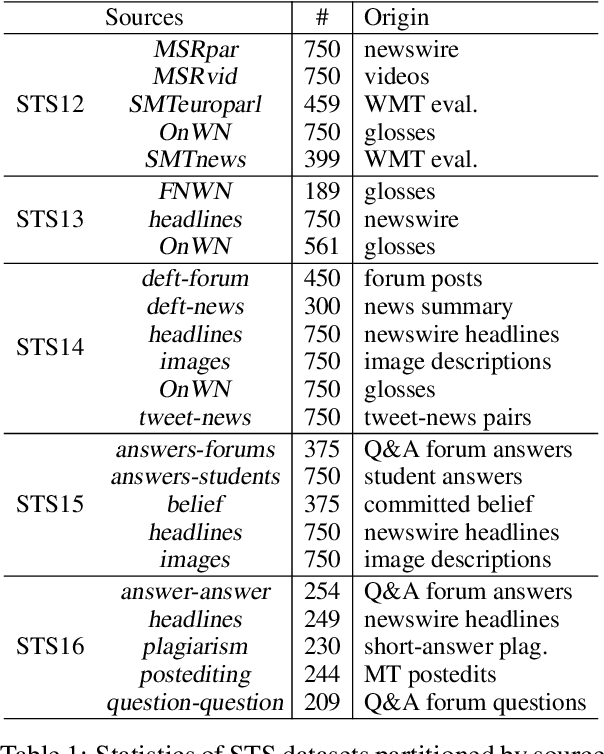


We have recently seen many successful applications of sentence embedding methods. It has not been well understood, however, what kind of properties are captured in the resulting sentence embeddings, depending on the supervision signals. In this paper, we focus on two types of sentence embeddings obtained by using natural language inference (NLI) datasets and definition sentences from a word dictionary and investigate their properties by comparing their performance with the semantic textual similarity (STS) task using the STS data partitioned by two perspectives: 1) the sources of sentences, and 2) the superficial similarity of the sentence pairs, and their performance on the downstream and probing tasks. We also demonstrate that combining the two types of embeddings yields substantially better performances than respective models on unsupervised STS tasks and downstream tasks.