 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Generalizing to Unseen Concepts: An Evaluation Framework and An LLM-Based Auto-Labeled Pipeline for Biomedical Concept Recognition
Jan 23, 2026Generalization to unseen concepts is a central challenge due to the scarcity of human annotations in Mention-agnostic Biomedical Concept Recognition (MA-BCR). This work makes two key contributions to systematically address this issue. First, we propose an evaluation framework built on hierarchical concept indices and novel metrics to measure generalization. Second, we explore LLM-based Auto-Labeled Data (ALD) as a scalable resource, creating a task-specific pipeline for its generation. Our research unequivocally shows that while LLM-generated ALD cannot fully substitute for manual annotations, it is a valuable resource for improving generalization, successfully providing models with the broader coverage and structural knowledge needed to approach recognizing unseen concepts. Code and datasets are available at https://github.com/bio-ie-tool/hi-ald.
Retrieval-Augmented Simulacra: Generative Agents for Up-to-date and Knowledge-Adaptive Simulations
Mar 18, 2025In the 2023 edition of the White Paper on Information and Communications, it is estimated that the population of social networking services in Japan will exceed 100 million by 2022, and the influence of social networking services in Japan is growing significantly. In addition, marketing using SNS and research on the propagation of emotions and information on SNS are being actively conducted, creating the need for a system for predicting trends in SNS interactions. We have already created a system that simulates the behavior of various communities on SNS by building a virtual SNS environment in which agents post and reply to each other in a chat community created by agents using a LLMs. In this paper, we evaluate the impact of the search extension generation mechanism used to create posts and replies in a virtual SNS environment using a simulation system on the ability to generate posts and replies. As a result of the evaluation, we confirmed that the proposed search extension generation mechanism, which mimics human search behavior, generates the most natural exchange.
Good/Evil Reputation Judgment of Celebrities by LLMs via Retrieval Augmented Generation
Mar 18, 2025



The purpose of this paper is to examine whether large language models (LLMs) can understand what is good and evil with respect to judging good/evil reputation of celebrities. Specifically, we first apply a large language model (namely, ChatGPT) to the task of collecting sentences that mention the target celebrity from articles about celebrities on Web pages. Next, the collected sentences are categorized based on their contents by ChatGPT, where ChatGPT assigns a category name to each of those categories. Those assigned category names are referred to as "aspects" of each celebrity. Then, by applying the framework of retrieval augmented generation (RAG), we show that the large language model is quite effective in the task of judging good/evil reputation of aspects and descriptions of each celebrity. Finally, also in terms of proving the advantages of the proposed method over existing services incorporating RAG functions, we show that the proposed method of judging good/evil of aspects/descriptions of each celebrity significantly outperform an existing service incorporating RAG functions.
Embedded Topic Models Enhanced by Wikification
Oct 03, 2024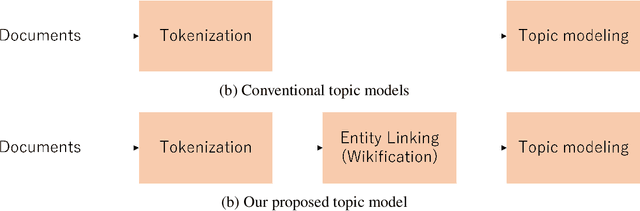



Topic modeling analyzes a collection of documents to learn meaningful patterns of words. However, previous topic models consider only the spelling of words and do not take into consideration the homography of words. In this study, we incorporate the Wikipedia knowledge into a neural topic model to make it aware of named entities. We evaluate our method on two datasets, 1) news articles of \textit{New York Times} and 2) the AIDA-CoNLL dataset. Our experiments show that our method improves the performance of neural topic models in generalizability. Moreover, we analyze frequent terms in each topic and the temporal dependencies between topics to demonstrate that our entity-aware topic models can capture the time-series development of topics well.
Enhancing Translation Accuracy of Large Language Models through Continual Pre-Training on Parallel Data
Jul 03, 2024



In this paper, we propose a two-phase training approach where pre-trained large language models are continually pre-trained on parallel data and then supervised fine-tuned with a small amount of high-quality parallel data. To investigate the effectiveness of our proposed approach, we conducted continual pre-training with a 3.8B-parameter model and parallel data across eight different formats. We evaluate these methods on thirteen test sets for Japanese-to-English and English-to-Japanese translation. The results demonstrate that when utilizing parallel data in continual pre-training, it is essential to alternate between source and target sentences. Additionally, we demonstrated that the translation accuracy improves only for translation directions where the order of source and target sentences aligns between continual pre-training data and inference. In addition, we demonstrate that the LLM-based translation model is more robust in translating spoken language and achieves higher accuracy with less training data compared to supervised encoder-decoder models. We also show that the highest accuracy is achieved when the data for continual pre-training consists of interleaved source and target sentences and when tags are added to the source sentences.
Extending Word-Level Quality Estimation for Post-Editing Assistance
Sep 23, 2022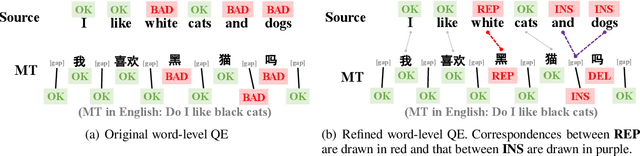
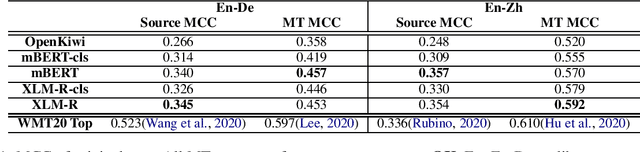


We define a novel concept called extended word alignment in order to improve post-editing assistance efficiency. Based on extended word alignment, we further propose a novel task called refined word-level QE that outputs refined tags and word-level correspondences. Compared to original word-level QE, the new task is able to directly point out editing operations, thus improves efficiency. To extract extended word alignment, we adopt a supervised method based on mBERT. To solve refined word-level QE, we firstly predict original QE tags by training a regression model for sequence tagging based on mBERT and XLM-R. Then, we refine original word tags with extended word alignment. In addition, we extract source-gap correspondences, meanwhile, obtaining gap tags. Experiments on two language pairs show the feasibility of our method and give us inspirations for further improvement.
ExKaldi-RT: A Real-Time Automatic Speech Recognition Extension Toolkit of Kaldi
Apr 03, 2021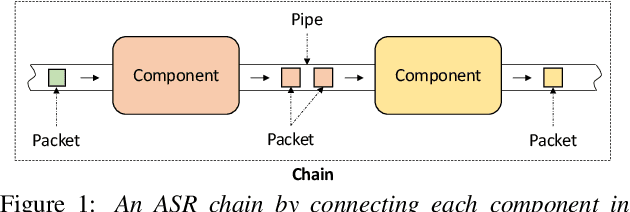

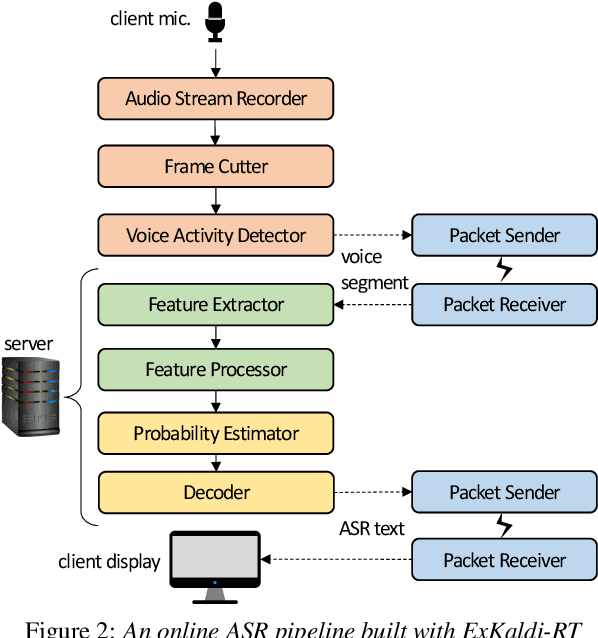
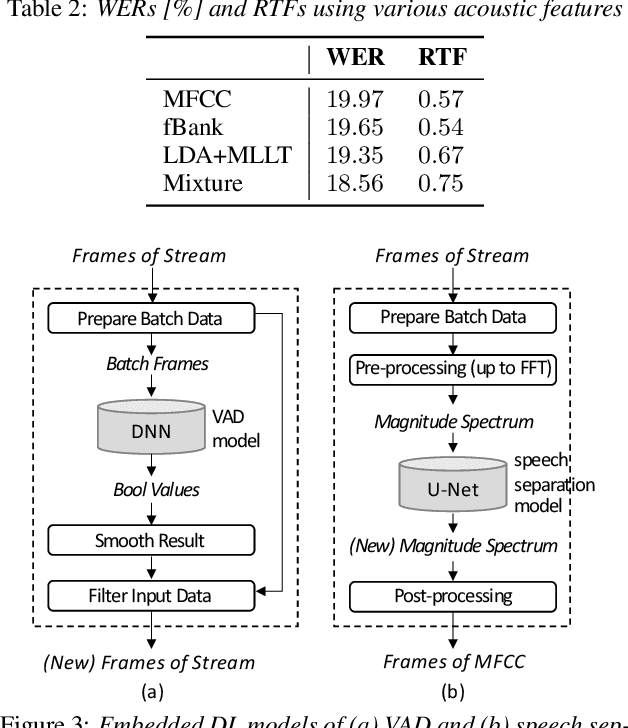
The availability of open-source software is playing a remarkable role in automatic speech recognition (ASR). Kaldi, for instance, is widely used to develop state-of-the-art offline and online ASR systems. This paper describes the "ExKaldi-RT," online ASR toolkit implemented based on Kaldi and Python language. ExKaldi-RT provides tools for providing a real-time audio stream pipeline, extracting acoustic features, transmitting packets with a remote connection, estimating acoustic probabilities with a neural network, and online decoding. While similar functions are available built on Kaldi, a key feature of ExKaldi-RT is completely working on Python language, which has an easy-to-use interface for online ASR system developers to exploit original research, for example, by applying neural network-based signal processing and acoustic model trained with deep learning frameworks. We performed benchmark experiments on the minimum LibriSpeech corpus, and showed that ExKaldi-RT could achieve competitive ASR performance in real-time.