 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Directional Attention Model for Multilingual Automatic Speech Recognition
Mar 29, 2022
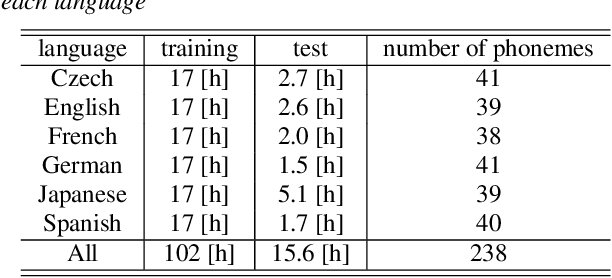
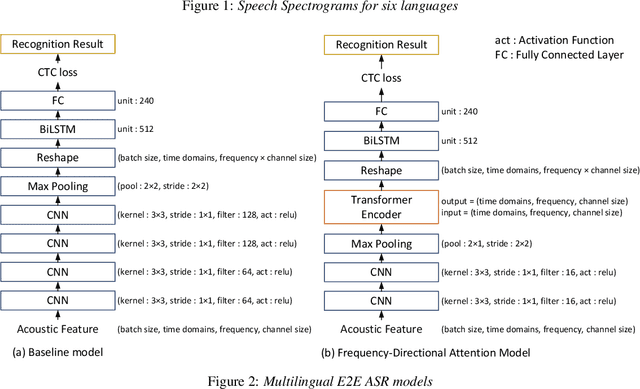

This paper proposes a model for transforming speech features using the frequency-directional attention model for End-to-End (E2E) automatic speech recognition. The idea is based on the hypothesis that in the phoneme system of each language, the characteristics of the frequency bands of speech when uttering them are different. By transforming the input Mel filter bank features with an attention model that characterizes the frequency direction, a feature transformation suitable for ASR in each language can be expected. This paper introduces a Transformer-encoder as a frequency-directional attention model. We evaluated the proposed method on a multilingual E2E ASR system for six different languages and found that the proposed method could achieve, on average, 5.3 points higher accuracy than the ASR model for each language by introducing the frequency-directional attention mechanism. Furthermore, visualization of the attention weights based on the proposed method suggested that it is possible to transform acoustic features considering the frequency characteristics of each language.
ExKaldi-RT: A Real-Time Automatic Speech Recognition Extension Toolkit of Kaldi
Apr 03, 2021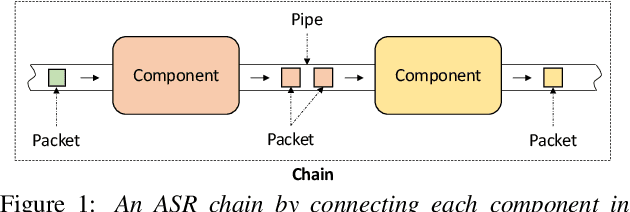

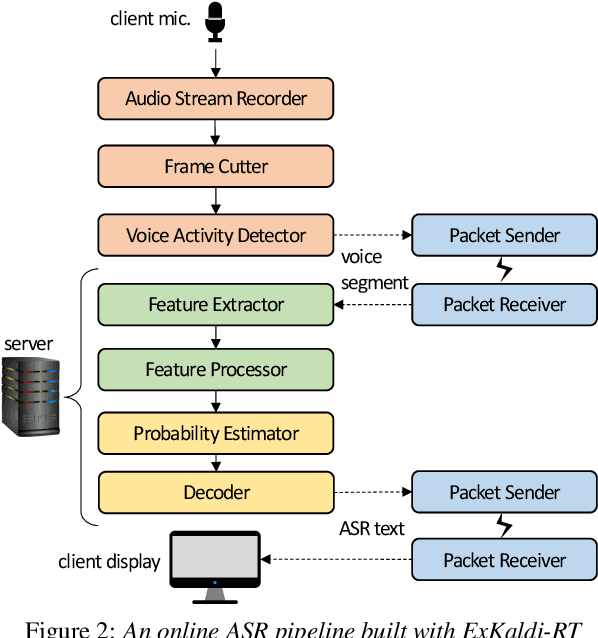
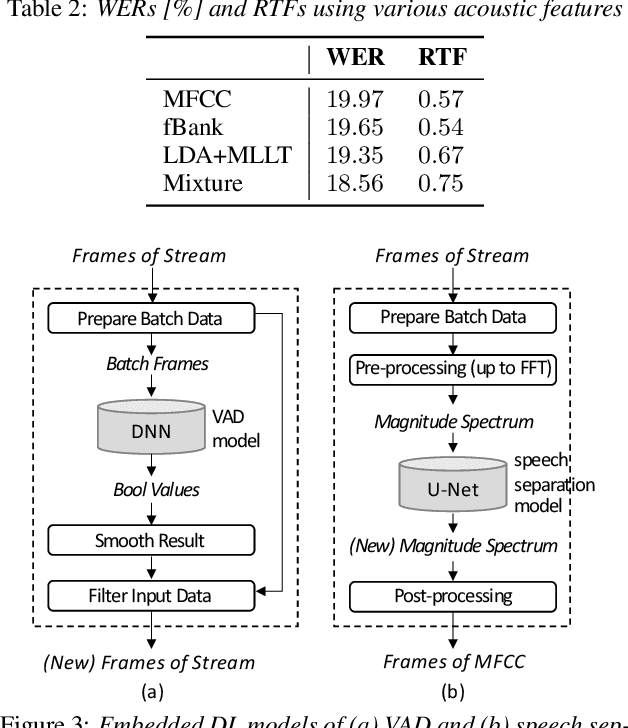
The availability of open-source software is playing a remarkable role in automatic speech recognition (ASR). Kaldi, for instance, is widely used to develop state-of-the-art offline and online ASR systems. This paper describes the "ExKaldi-RT," online ASR toolkit implemented based on Kaldi and Python language. ExKaldi-RT provides tools for providing a real-time audio stream pipeline, extracting acoustic features, transmitting packets with a remote connection, estimating acoustic probabilities with a neural network, and online decoding. While similar functions are available built on Kaldi, a key feature of ExKaldi-RT is completely working on Python language, which has an easy-to-use interface for online ASR system developers to exploit original research, for example, by applying neural network-based signal processing and acoustic model trained with deep learning frameworks. We performed benchmark experiments on the minimum LibriSpeech corpus, and showed that ExKaldi-RT could achieve competitive ASR performance in real-time.