 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Directional Attention Model for Multilingual Automatic Speech Recognition
Mar 29, 2022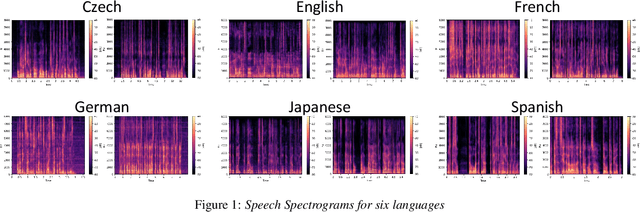
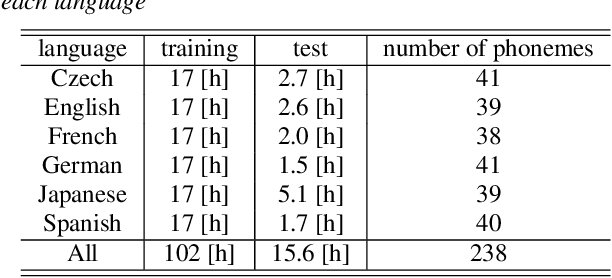
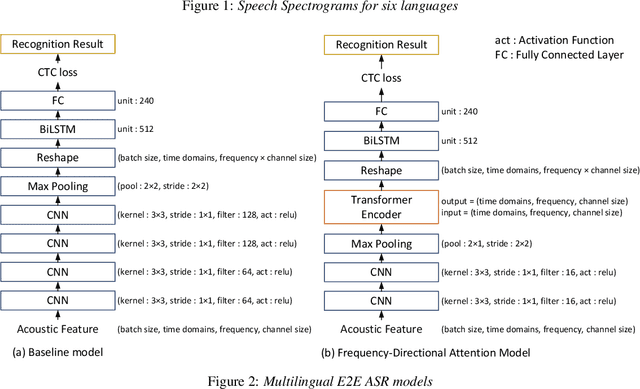

This paper proposes a model for transforming speech features using the frequency-directional attention model for End-to-End (E2E) automatic speech recognition. The idea is based on the hypothesis that in the phoneme system of each language, the characteristics of the frequency bands of speech when uttering them are different. By transforming the input Mel filter bank features with an attention model that characterizes the frequency direction, a feature transformation suitable for ASR in each language can be expected. This paper introduces a Transformer-encoder as a frequency-directional attention model. We evaluated the proposed method on a multilingual E2E ASR system for six different languages and found that the proposed method could achieve, on average, 5.3 points higher accuracy than the ASR model for each language by introducing the frequency-directional attention mechanism. Furthermore, visualization of the attention weights based on the proposed method suggested that it is possible to transform acoustic features considering the frequency characteristics of each language.