 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHARDeg: A Benchmark for Skeletal Human Action Recognition in Degraded Scenarios
May 23, 2025Computer vision (CV) models for detection, prediction or classification tasks operate on video data-streams that are often degraded in the real world, due to deployment in real-time or on resource-constrained hardware. It is therefore critical that these models are robust to degraded data, but state of the art (SoTA) models are often insufficiently assessed with these real-world constraints in mind. This is exemplified by Skeletal Human Action Recognition (SHAR), which is critical in many CV pipelines operating in real-time and at the edge, but robustness to degraded data has previously only been shallowly and inconsistently assessed. Here we address this issue for SHAR by providing an important first data degradation benchmark on the most detailed and largest 3D open dataset, NTU-RGB+D-120, and assess the robustness of five leading SHAR models to three forms of degradation that represent real-world issues. We demonstrate the need for this benchmark by showing that the form of degradation, which has not previously been considered, has a large impact on model accuracy; at the same effective frame rate, model accuracy can vary by >40% depending on degradation type. We also identify that temporal regularity of frames in degraded SHAR data is likely a major driver of differences in model performance, and harness this to improve performance of existing models by up to >40%, through employing a simple mitigation approach based on interpolation. Finally, we highlight how our benchmark has helped identify an important degradation-resistant SHAR model based in Rough Path Theory; the LogSigRNN SHAR model outperforms the SoTA DeGCN model in five out of six cases at low frame rates by an average accuracy of 6%, despite trailing the SoTA model by 11-12% on un-degraded data at high frame rates (30 FPS).
Improving Object Detection by Modifying Synthetic Data with Explainable AI
Dec 02, 2024



In many computer vision domains the collection of sufficient real-world data is challenging and can severely impact model performance, particularly when running inference on samples that are unseen or underrepresented in training. Synthetically generated images provide a promising solution, but it remains unclear how to design synthetic data to optimally improve model performance, for example whether to introduce more realism or more abstraction in such datasets. Here we propose a novel conceptual approach to improve the performance of computer vision models trained on synthetic images, by using robust Explainable AI (XAI) techniques to guide the modification of 3D models used to generate these images. Importantly, this framework allows both modifications that increase and decrease realism in synthetic data, which can both improve model performance. We illustrate this concept using a real-world example where data are sparse; the detection of vehicles in infrared imagery. We fine-tune an initial YOLOv8 model on the ATR DSIAC infrared dataset and synthetic images generated from 3D mesh models in the Unity gaming engine, and then use XAI saliency maps to guide modification of our Unity models. We show that synthetic data can improve detection of vehicles in orientations unseen in training by 4.6\% (to mAP50 scores of 94.6\%). We further improve performance by an additional 1.5\% (to 96.1\%) through our new XAI-guided approach, which reduces misclassifications through both increasing and decreasing the realism of different parts of the synthetic data. These proof-of-concept results pave the way for fine, XAI-controlled curation of synthetic datasets through detailed feature modifications, tailored to improve object detection performance.
Features-over-the-Air: Contrastive Learning Enabled Cooperative Edge Inference
Apr 17, 2023



We study the collaborative image retrieval problem at the wireless edge, where multiple edge devices capture images of the same object, which are then used jointly to retrieve similar images at the edge server over a shared multiple access channel. We propose a semantic non-orthogonal multiple access (NOMA) communication paradigm, in which extracted features from each device are mapped directly to channel inputs, which are then added over-the-air. We propose a novel contrastive learning (CL)-based semantic communication (CL-SC) paradigm, aiming to exploit signal correlations to maximize the retrieval accuracy under a total bandwidth constraints. Specifically, we treat noisy correlated signals as different augmentations of a common identity, and propose a cross-view CL algorithm to optimize the correlated signals in a coarse-to-fine fashion to improve retrieval accuracy. Extensive numerical experiments verify that our method achieves the state-of-the-art performance and can significantly improve retrieval accuracy, with particularly significant gains in low signla-to-noise ratio (SNR) and limited bandwidth regimes.
Collaborative Semantic Communication at the Edge
Jan 10, 2023We study the collaborative image retrieval problem at the wireless edge, where multiple edge devices capture images of the same object from different angles and locations, which are then used jointly to retrieve similar images at the edge server over a shared multiple access channel (MAC). We propose two novel deep learning-based joint source and channel coding (JSCC) schemes for the task over both additive white Gaussian noise (AWGN) and Rayleigh slow fading channels, with the aim of maximizing the retrieval accuracy under a total bandwidth constraint. The proposed schemes are evaluated on a wide range of channel signal-to-noise ratios (SNRs), and shown to outperform the single-device JSCC and the separation-based multiple-access benchmarks. We also propose two novel SNR-aware JSCC schemes with attention modules to improve the performance in the case of channel mismatch between training and test instances.
Neural Distributed Image Compression with Cross-Attention Feature Alignment
Jul 18, 2022
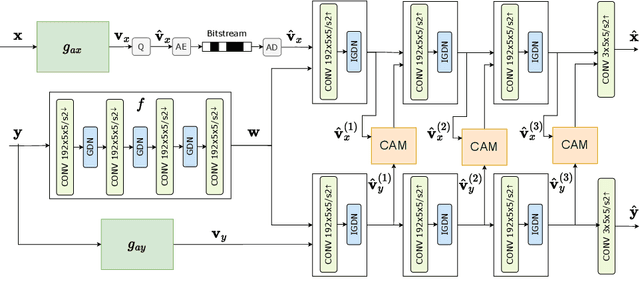
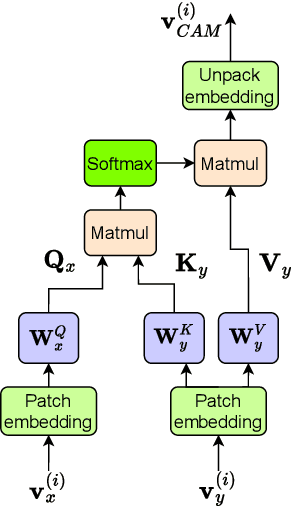
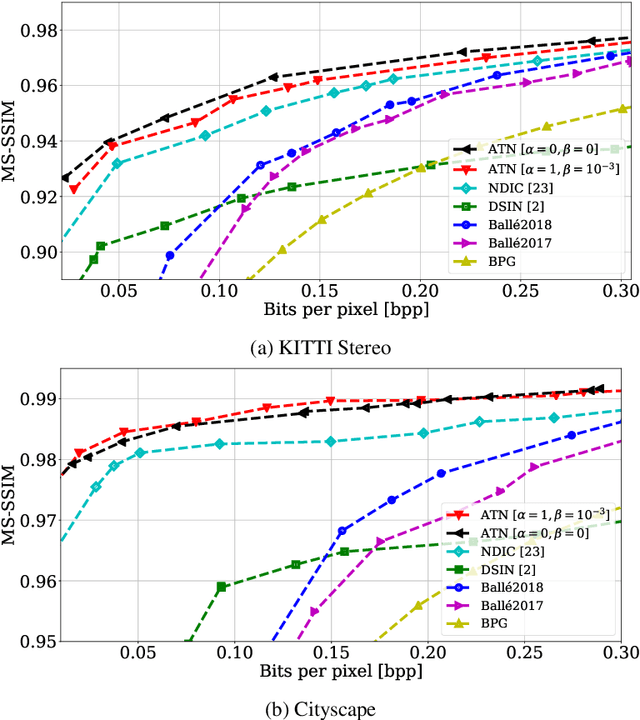
We propose a novel deep neural network (DNN) architecture for compressing an image when a correlated image is available as side information only at the decoder side, a special case of the well-known and heavily studied distributed source coding (DSC) problem. In particular, we consider a pair of stereo images, which have overlapping fields of view, captured by a synchronized and calibrated pair of cameras; and therefore, are highly correlated. We assume that one image of the pair is to be compressed and transmitted, while the other image is available only at the decoder. In the proposed architecture, the encoder maps the input image to a latent space using a DNN, quantizes the latent representation, and compresses it losslessly using entropy coding. The proposed decoder extracts useful information common between the images solely from the available side information, as well as a latent representation of the side information. Then, the latent representations of the two images, one received from the encoder, the other extracted locally, along with the locally generated common information, are fed to the respective decoders of the two images. We employ a cross-attention module (CAM) to align the feature maps obtained in the intermediate layers of the respective decoders of the two images, thus allowing better utilization of the side information. We train and demonstrate the effectiveness of the proposed algorithm on various realistic setups, such as KITTI and Cityscape datasets of stereo image pairs. Our results show that the proposed architecture is capable of exploiting the decoder-only side information in a more efficient manner as it outperforms previous works. We also show that the proposed method is able to provide significant gains even in the case of uncalibrated and unsynchronized camera array use cases.
Deep Stereo Image Compression with Decoder Side Information using Wyner Common Information
Jun 22, 2021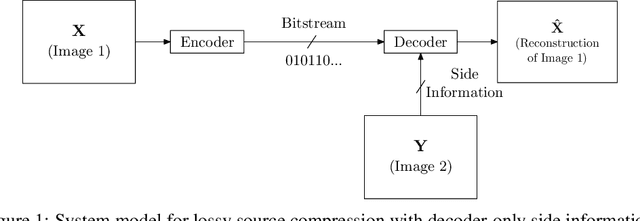
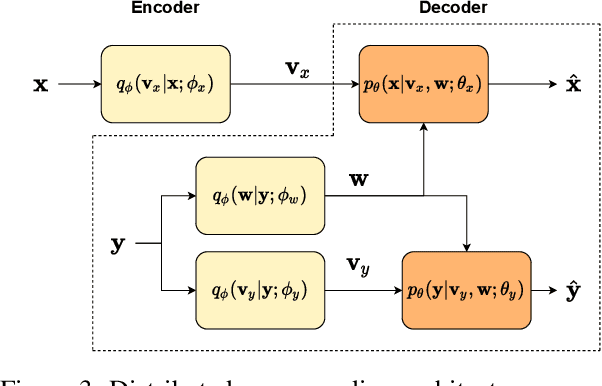
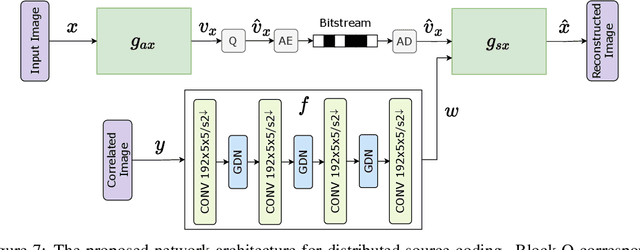
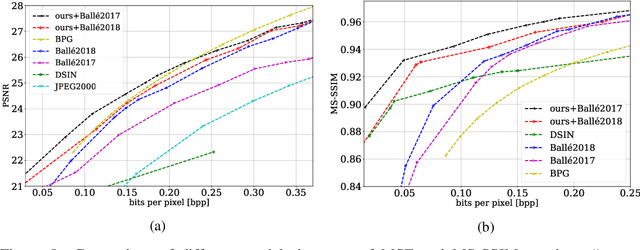
We present a novel deep neural network (DNN) architecture for compressing an image when a correlated image is available as side information only at the decoder. This problem is known as distributed source coding (DSC) in information theory. In particular, we consider a pair of stereo images, which generally have high correlation with each other due to overlapping fields of view, and assume that one image of the pair is to be compressed and transmitted, while the other image is available only at the decoder. In the proposed architecture, the encoder maps the input image to a latent space, quantizes the latent representation, and compresses it using entropy coding. The decoder is trained to extract the Wyner's common information between the input image and the correlated image from the latter. The received latent representation and the locally generated common information are passed through a decoder network to obtain an enhanced reconstruction of the input image. The common information provides a succinct representation of the relevant information at the receiver. We train and demonstrate the effectiveness of the proposed approach on the KITTI dataset of stereo image pairs. Our results show that the proposed architecture is capable of exploiting the decoder-only side information, and outperforms previous work on stereo image compression with decoder side information.
Dopamine: Differentially Private Federated Learning on Medical Data
Jan 29, 2021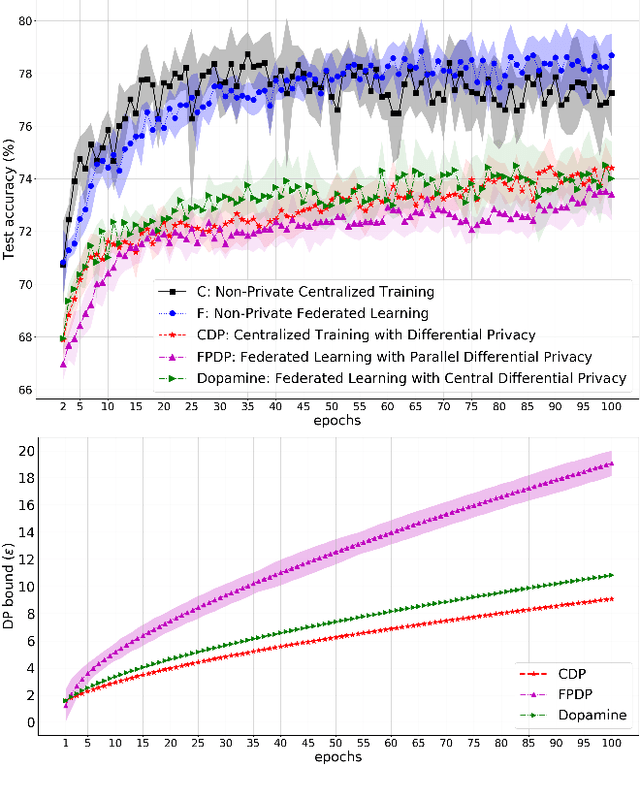
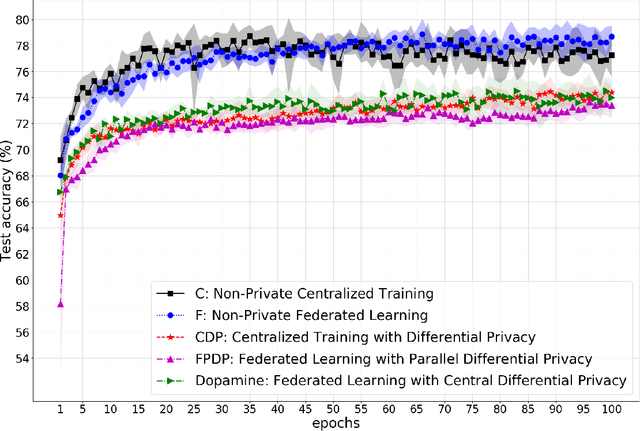
While rich medical datasets are hosted in hospitals distributed across the world, concerns on patients' privacy is a barrier against using such data to train deep neural networks (DNNs) for medical diagnostics. We propose Dopamine, a system to train DNNs on distributed datasets, which employs federated learning (FL) with differentially-private stochastic gradient descent (DPSGD), and, in combination with secure aggregation, can establish a better trade-off between differential privacy (DP) guarantee and DNN's accuracy than other approaches. Results on a diabetic retinopathy~(DR) task show that Dopamine provides a DP guarantee close to the centralized training counterpart, while achieving a better classification accuracy than FL with parallel DP where DPSGD is applied without coordination. Code is available at https://github.com/ipc-lab/private-ml-for-health.