 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Federated Edge Learning with Overlapped Communication and Computation and Channel-Aware Fair Client Scheduling
Sep 14, 2021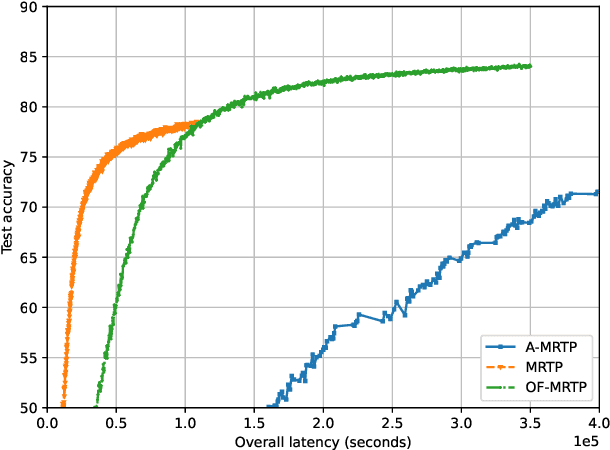
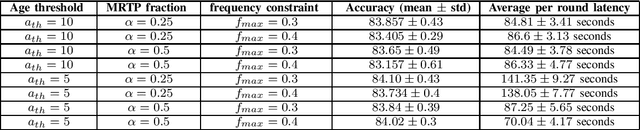

We consider federated edge learning (FEEL) over wireless fading channels taking into account the downlink and uplink channel latencies, and the random computation delays at the clients. We speed up the training process by overlapping the communication with computation. With fountain coded transmission of the global model update, clients receive the global model asynchronously, and start performing local computations right away. Then, we propose a dynamic client scheduling policy, called MRTP, for uploading local model updates to the parameter server (PS), which, at any time, schedules the client with the minimum remaining upload time. However, MRTP can lead to biased participation of clients in the update process, resulting in performance degradation in non-iid data scenarios. To overcome this, we propose two alternative schemes with fairness considerations, termed as age-aware MRTP (A-MRTP), and opportunistically fair MRTP (OF-MRTP). In A-MRTP, the remaining clients are scheduled according to the ratio between their remaining transmission time and the update age, while in OF-MRTP, the selection mechanism utilizes the long term average channel rate of the clients to further reduce the latency while ensuring fair participation of the clients. It is shown through numerical simulations that OF-MRTP provides significant reduction in latency without sacrificing test accuracy.
Dopamine: Differentially Private Federated Learning on Medical Data
Jan 29, 2021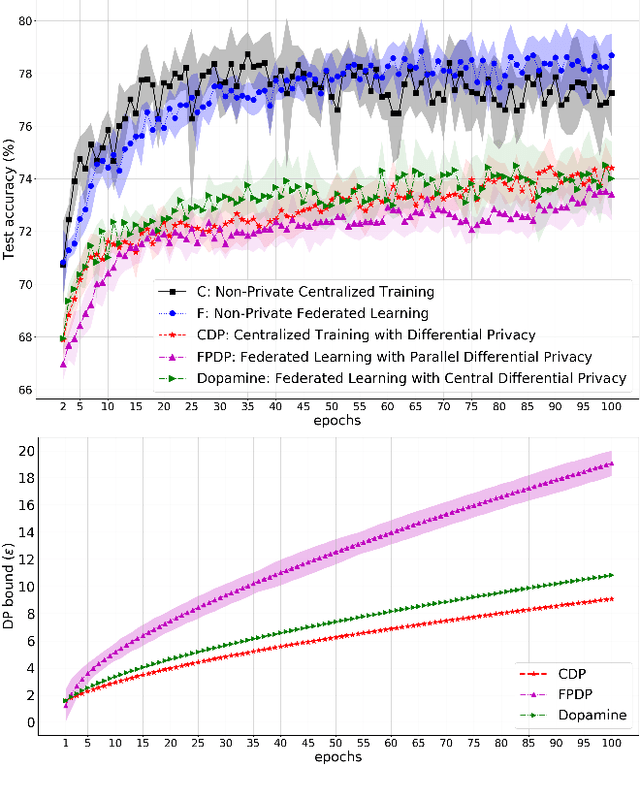
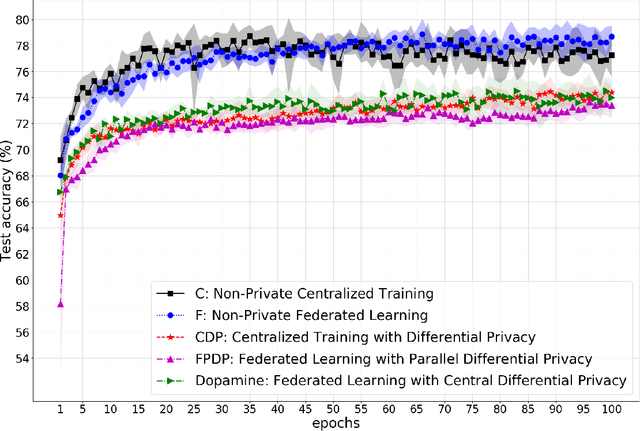
While rich medical datasets are hosted in hospitals distributed across the world, concerns on patients' privacy is a barrier against using such data to train deep neural networks (DNNs) for medical diagnostics. We propose Dopamine, a system to train DNNs on distributed datasets, which employs federated learning (FL) with differentially-private stochastic gradient descent (DPSGD), and, in combination with secure aggregation, can establish a better trade-off between differential privacy (DP) guarantee and DNN's accuracy than other approaches. Results on a diabetic retinopathy~(DR) task show that Dopamine provides a DP guarantee close to the centralized training counterpart, while achieving a better classification accuracy than FL with parallel DP where DPSGD is applied without coordination. Code is available at https://github.com/ipc-lab/private-ml-for-health.