 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototypical Transformer as Unified Motion Learners
Jun 03, 2024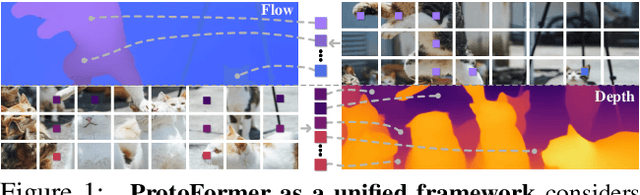
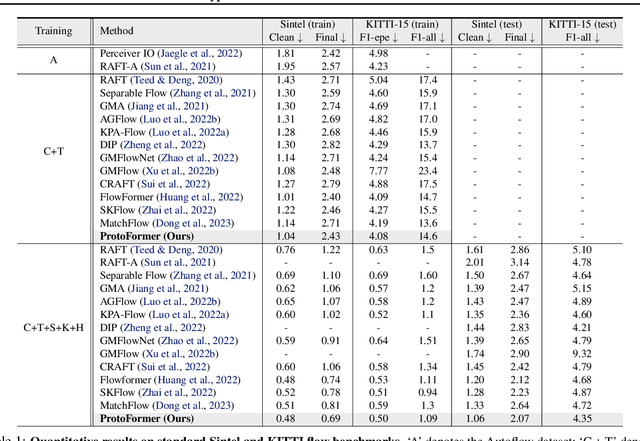
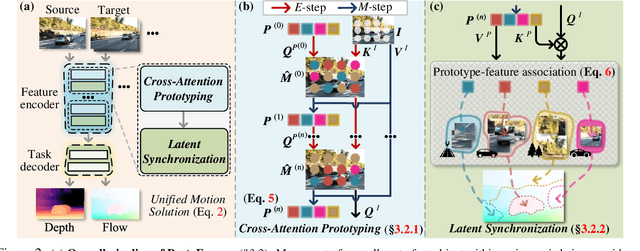
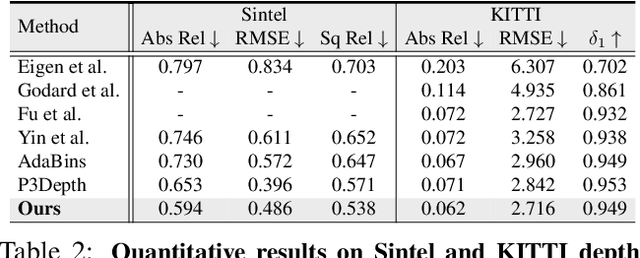
In this work, we introduce the Prototypical Transformer (ProtoFormer), a general and unified framework that approaches various motion tasks from a prototype perspective. ProtoFormer seamlessly integrates prototype learning with Transformer by thoughtfully considering motion dynamics, introducing two innovative designs. First, Cross-Attention Prototyping discovers prototypes based on signature motion patterns, providing transparency in understanding motion scenes. Second, Latent Synchronization guides feature representation learning via prototypes, effectively mitigating the problem of motion uncertainty. Empirical results demonstrate that our approach achieves competitive performance on popular motion tasks such as optical flow and scene depth. Furthermore, it exhibits generality across various downstream tasks, including object tracking and video stabilization.
Image Translation as Diffusion Visual Programmers
Jan 30, 2024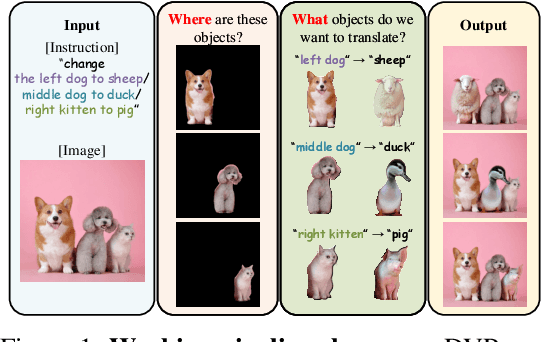



We introduce the novel Diffusion Visual Programmer (DVP), a neuro-symbolic image translation framework. Our proposed DVP seamlessly embeds a condition-flexible diffusion model within the GPT architecture, orchestrating a coherent sequence of visual programs (i.e., computer vision models) for various pro-symbolic steps, which span RoI identification, style transfer, and position manipulation, facilitating transparent and controllable image translation processes. Extensive experiments demonstrate DVP's remarkable performance, surpassing concurrent arts. This success can be attributed to several key features of DVP: First, DVP achieves condition-flexible translation via instance normalization, enabling the model to eliminate sensitivity caused by the manual guidance and optimally focus on textual descriptions for high-quality content generation. Second, the framework enhances in-context reasoning by deciphering intricate high-dimensional concepts in feature spaces into more accessible low-dimensional symbols (e.g., [Prompt], [RoI object]), allowing for localized, context-free editing while maintaining overall coherence. Last but not least, DVP improves systemic controllability and explainability by offering explicit symbolic representations at each programming stage, empowering users to intuitively interpret and modify results. Our research marks a substantial step towards harmonizing artificial image translation processes with cognitive intelligence, promising broader applications.
ClusterFormer: Clustering As A Universal Visual Learner
Oct 01, 2023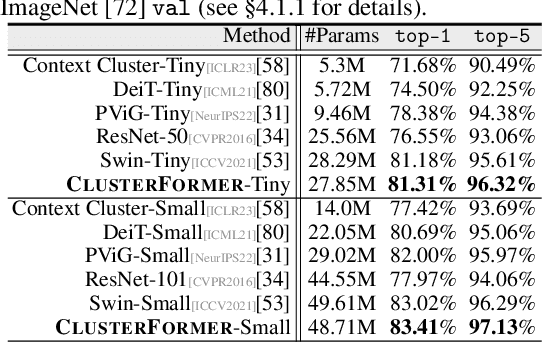
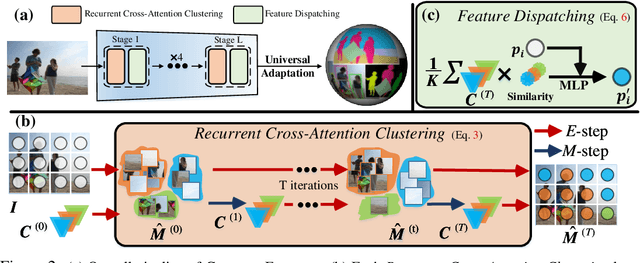
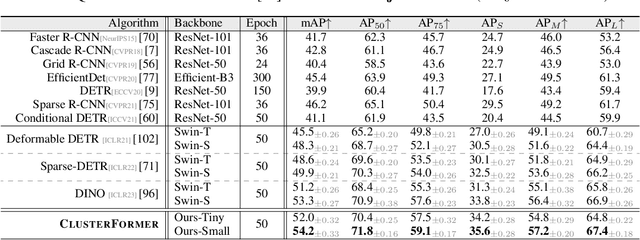

This paper presents CLUSTERFORMER, a universal vision model that is based on the CLUSTERing paradigm with TransFORMER. It comprises two novel designs: 1. recurrent cross-attention clustering, which reformulates the cross-attention mechanism in Transformer and enables recursive updates of cluster centers to facilitate strong representation learning; and 2. feature dispatching, which uses the updated cluster centers to redistribute image features through similarity-based metrics, resulting in a transparent pipeline. This elegant design streamlines an explainable and transferable workflow, capable of tackling heterogeneous vision tasks (i.e., image classification, object detection, and image segmentation) with varying levels of clustering granularity (i.e., image-, box-, and pixel-level). Empirical results demonstrate that CLUSTERFORMER outperforms various well-known specialized architectures, achieving 83.41% top-1 acc. over ImageNet-1K for image classification, 54.2% and 47.0% mAP over MS COCO for object detection and instance segmentation, 52.4% mIoU over ADE20K for semantic segmentation, and 55.8% PQ over COCO Panoptic for panoptic segmentation. For its efficacy, we hope our work can catalyze a paradigm shift in universal models in computer vision.