 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFDCT: Frequency-Aware Decomposition and Cross-Modal Token-Alignment for Multi-Sensor Target Classification
Paper and Code
Mar 12, 2025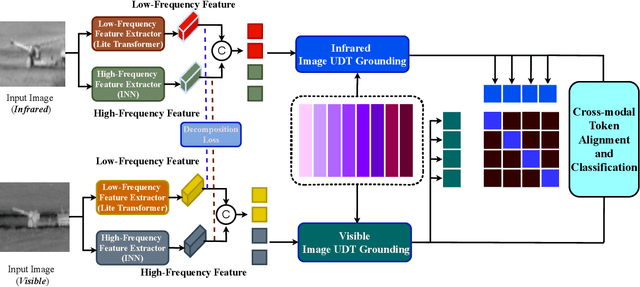
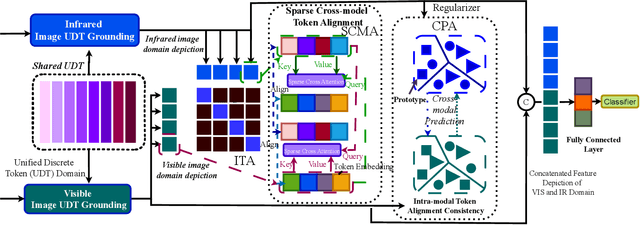
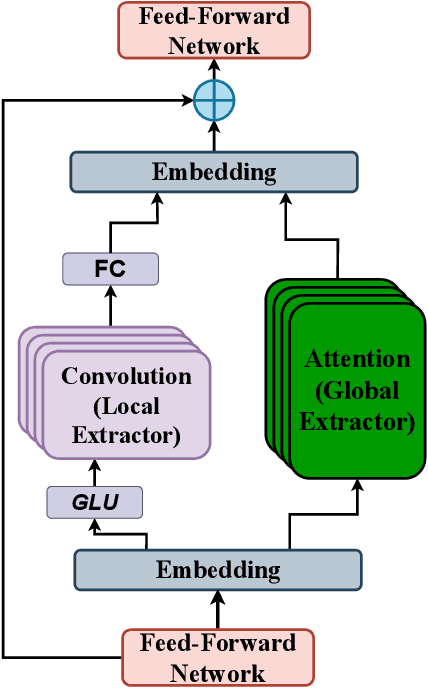
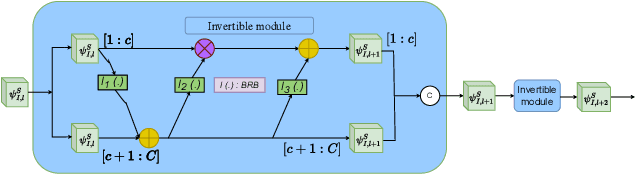
In automatic target recognition (ATR) systems, sensors may fail to capture discriminative, fine-grained detail features due to environmental conditions, noise created by CMOS chips, occlusion, parallaxes, and sensor misalignment. Therefore, multi-sensor image fusion is an effective choice to overcome these constraints. However, multi-modal image sensors are heterogeneous and have domain and granularity gaps. In addition, the multi-sensor images can be misaligned due to intricate background clutters, fluctuating illumination conditions, and uncontrolled sensor settings. In this paper, to overcome these issues, we decompose, align, and fuse multiple image sensor data for target classification. We extract the domain-specific and domain-invariant features from each sensor data. We propose to develop a shared unified discrete token (UDT) space between sensors to reduce the domain and granularity gaps. Additionally, we develop an alignment module to overcome the misalignment between multi-sensors and emphasize the discriminative representation of the UDT space. In the alignment module, we introduce sparsity constraints to provide a better cross-modal representation of the UDT space and robustness against various sensor settings. We achieve superior classification performance compared to single-modality classifiers and several state-of-the-art multi-modal fusion algorithms on four multi-sensor ATR datasets.