 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuality Guided Sketch-to-Photo Image Synthesis
Paper and Code

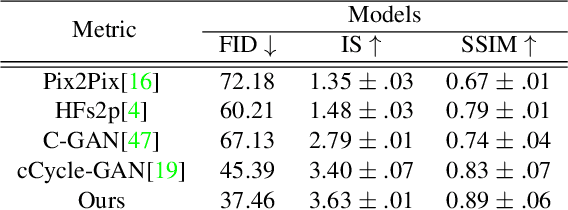
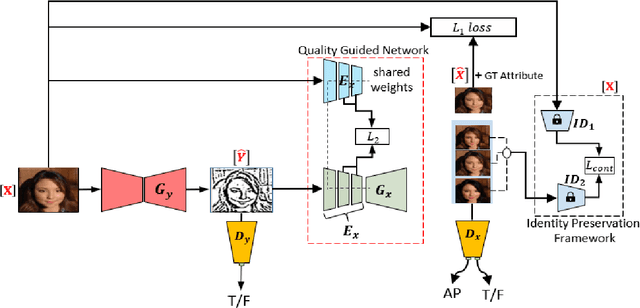
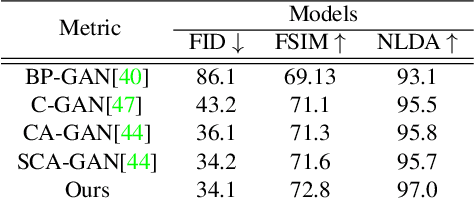
Facial sketches drawn by artists are widely used for visual identification applications and mostly by law enforcement agencies, but the quality of these sketches depend on the ability of the artist to clearly replicate all the key facial features that could aid in capturing the true identity of a subject. Recent works have attempted to synthesize these sketches into plausible visual images to improve visual recognition and identification. However, synthesizing photo-realistic images from sketches proves to be an even more challenging task, especially for sensitive applications such as suspect identification. In this work, we propose a novel approach that adopts a generative adversarial network that synthesizes a single sketch into multiple synthetic images with unique attributes like hair color, sex, etc. We incorporate a hybrid discriminator which performs attribute classification of multiple target attributes, a quality guided encoder that minimizes the perceptual dissimilarity of the latent space embedding of the synthesized and real image at different layers in the network and an identity preserving network that maintains the identity of the synthesised image throughout the training process. Our approach is aimed at improving the visual appeal of the synthesised images while incorporating multiple attribute assignment to the generator without compromising the identity of the synthesised image. We synthesised sketches using XDOG filter for the CelebA, WVU Multi-modal and CelebA-HQ datasets and from an auxiliary generator trained on sketches from CUHK, IIT-D and FERET datasets. Our results are impressive compared to current state of the art.