 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcess-Supervised Reward Models for Clinical Note Generation: A Scalable Approach Guided by Domain Expertise
Dec 17, 2024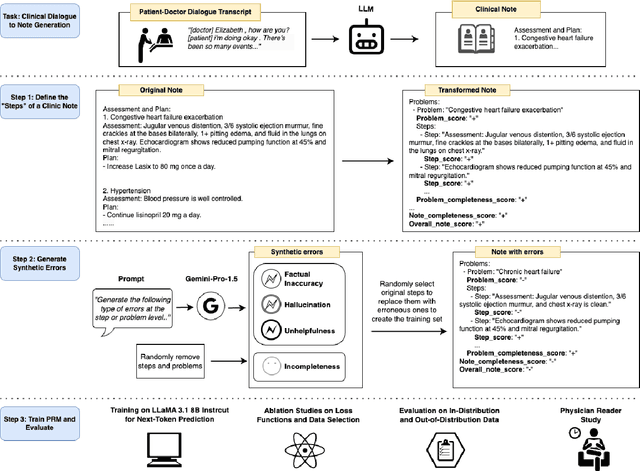
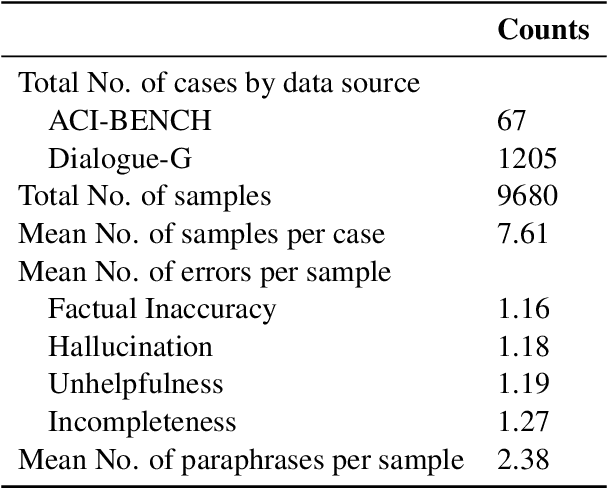

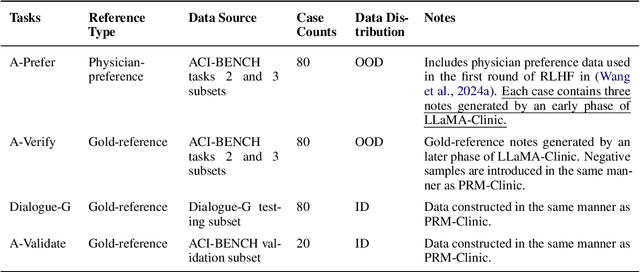
Process-supervised reward models (PRMs), which verify large language model (LLM) outputs step-by-step, have achieved significant success in mathematical and coding problems. However, their application to other domains remains largely unexplored. In this work, we train a PRM to provide step-level reward signals for clinical notes generated by LLMs from patient-doctor dialogues. Guided by real-world clinician expertise, we carefully designed step definitions for clinical notes and utilized Gemini-Pro 1.5 to automatically generate process supervision data at scale. Our proposed PRM, trained on the LLaMA-3.1 8B instruct model, demonstrated superior performance compared to Gemini-Pro 1.5 and an outcome-supervised reward model (ORM) across two key evaluations: (1) the accuracy of selecting gold-reference samples from error-containing samples, achieving 98.8% (versus 61.3% for ORM and 93.8% for Gemini-Pro 1.5), and (2) the accuracy of selecting physician-preferred notes, achieving 56.2% (compared to 51.2% for ORM and 50.0% for Gemini-Pro 1.5). Additionally, we conducted ablation studies to determine optimal loss functions and data selection strategies, along with physician reader studies to explore predictors of downstream Best-of-N performance. Our promising results suggest the potential of PRMs to extend beyond the clinical domain, offering a scalable and effective solution for diverse generative tasks.
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Apr 25, 2024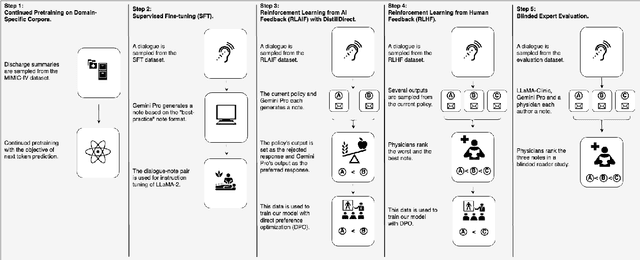
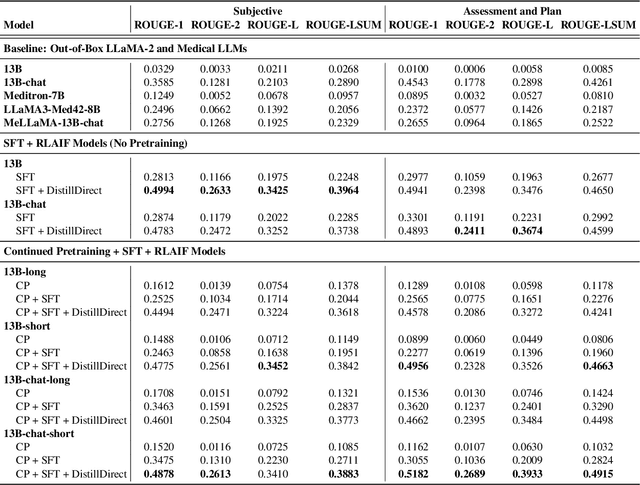
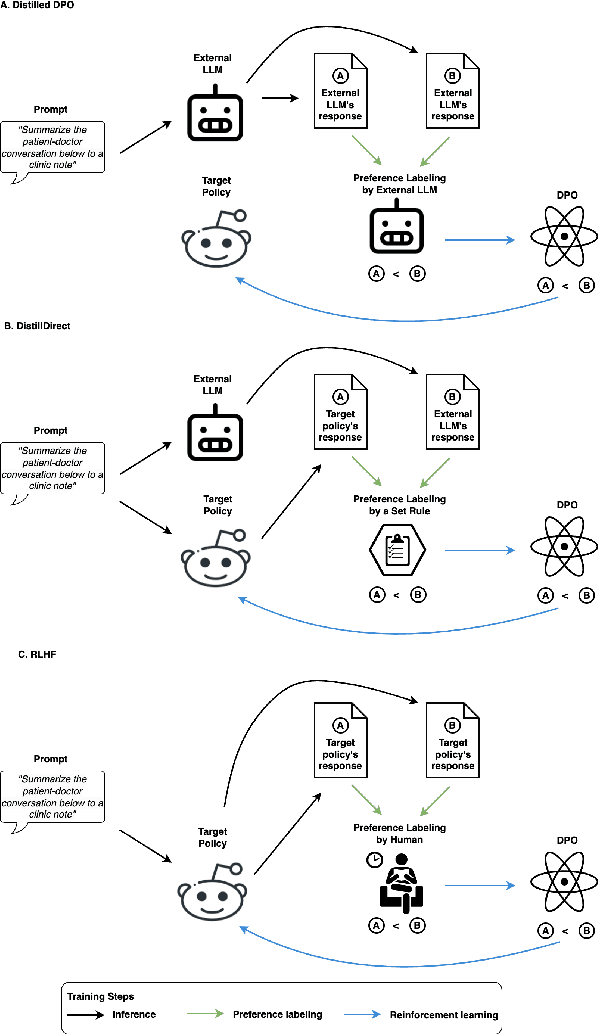
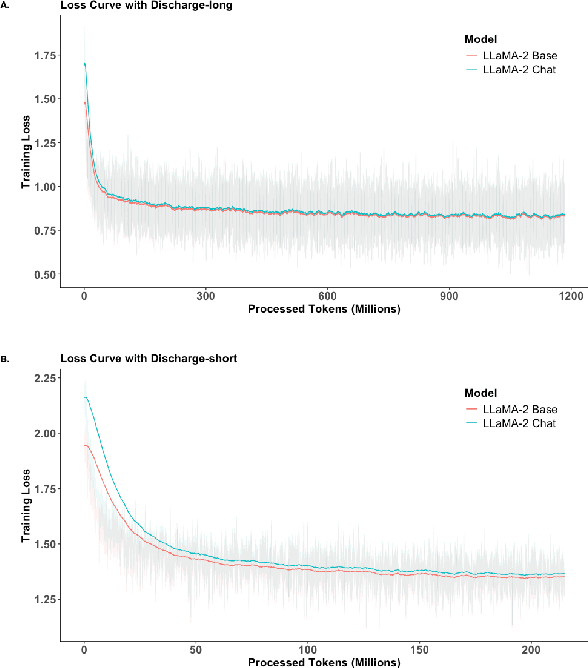
Large Language Models (LLMs) have shown promising capabilities in handling clinical text summarization tasks. In this study, we demonstrate that a small open-source LLM can be effectively trained to generate high-quality clinical notes from outpatient patient-doctor dialogues. We achieve this through a comprehensive domain- and task-specific adaptation process for the LLaMA-2 13 billion parameter model. This process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced an enhanced approach, termed DistillDirect, for performing on-policy reinforcement learning with Gemini Pro serving as the teacher model. Our resulting model, LLaMA-Clinic, is capable of generating clinical notes that are comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as "acceptable" or higher across all three criteria: real-world readiness, completeness, and accuracy. Notably, in the more challenging "Assessment and Plan" section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness compared to physician-authored notes (4.1/5). Additionally, we identified caveats in public clinical note datasets, such as ACI-BENCH. We highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format. Overall, our research demonstrates the potential and feasibility of training smaller, open-source LLMs to assist with clinical documentation, capitalizing on healthcare institutions' access to patient records and domain expertise. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research in this field.