 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking Visual-Inertial Deep Multimodal Fusion for Relative Pose Regression and Odometry-aided Absolute Pose Regression
Paper and Code

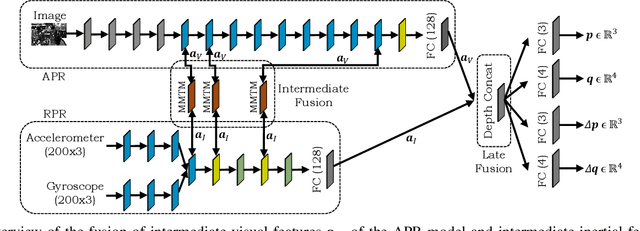
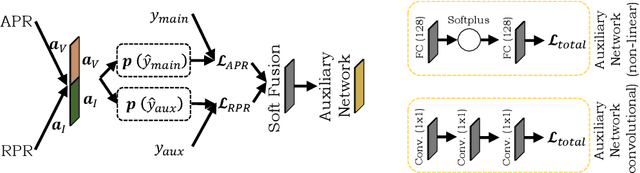

Visual-inertial localization is a key problem in computer vision and robotics applications such as virtual reality, self-driving cars, and aerial vehicles. The goal is to estimate an accurate pose of an object when either the environment or the dynamics are known. Recent methods directly regress the pose using convolutional and spatio-temporal networks. Absolute pose regression (APR) techniques predict the absolute camera pose from an image input in a known scene. Odometry methods perform relative pose regression (RPR) that predicts the relative pose from a known object dynamic (visual or inertial inputs). The localization task can be improved by retrieving information of both data sources for a cross-modal setup, which is a challenging problem due to contradictory tasks. In this work, we conduct a benchmark to evaluate deep multimodal fusion based on PGO and attention networks. Auxiliary and Bayesian learning are integrated for the APR task. We show accuracy improvements for the RPR-aided APR task and for the RPR-RPR task for aerial vehicles and hand-held devices. We conduct experiments on the EuRoC MAV and PennCOSYVIO datasets, and record a novel industry dataset.