 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generative Location Awareness for Disaster Response: A Probabilistic Cross-view Geolocalization Approach
Dec 23, 2025
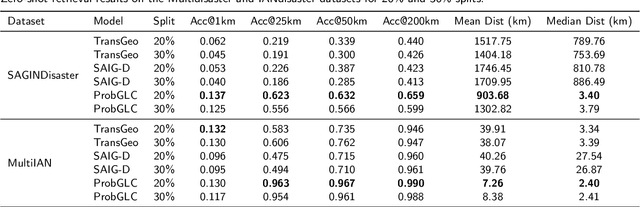
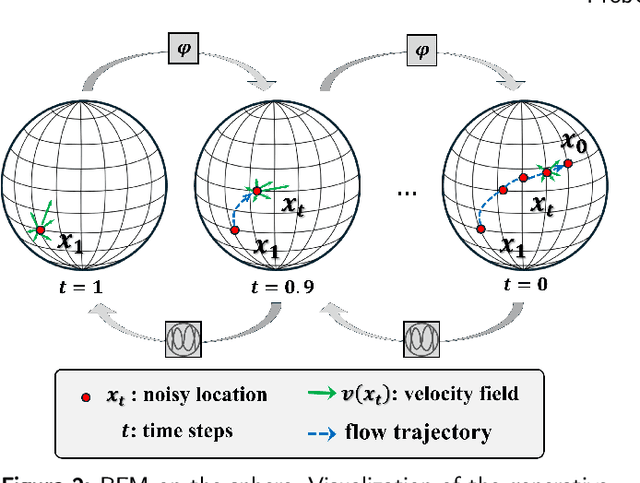
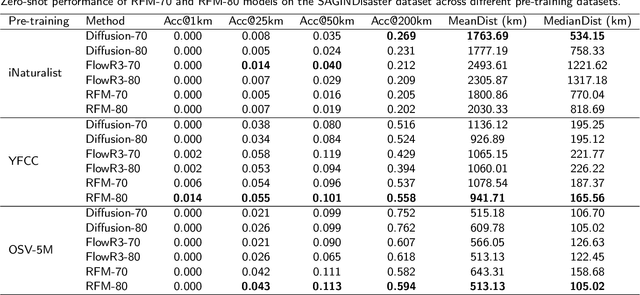
As Earth's climate changes, it is impacting disasters and extreme weather events across the planet. Record-breaking heat waves, drenching rainfalls, extreme wildfires, and widespread flooding during hurricanes are all becoming more frequent and more intense. Rapid and efficient response to disaster events is essential for climate resilience and sustainability. A key challenge in disaster response is to accurately and quickly identify disaster locations to support decision-making and resources allocation. In this paper, we propose a Probabilistic Cross-view Geolocalization approach, called ProbGLC, exploring new pathways towards generative location awareness for rapid disaster response. Herein, we combine probabilistic and deterministic geolocalization models into a unified framework to simultaneously enhance model explainability (via uncertainty quantification) and achieve state-of-the-art geolocalization performance. Designed for rapid diaster response, the ProbGLC is able to address cross-view geolocalization across multiple disaster events as well as to offer unique features of probabilistic distribution and localizability score. To evaluate the ProbGLC, we conduct extensive experiments on two cross-view disaster datasets (i.e., MultiIAN and SAGAINDisaster), consisting diverse cross-view imagery pairs of multiple disaster types (e.g., hurricanes, wildfires, floods, to tornadoes). Preliminary results confirms the superior geolocalization accuracy (i.e., 0.86 in Acc@1km and 0.97 in Acc@25km) and model explainability (i.e., via probabilistic distributions and localizability scores) of the proposed ProbGLC approach, highlighting the great potential of leveraging generative cross-view approach to facilitate location awareness for better and faster disaster response. The data and code is publicly available at https://github.com/bobleegogogo/ProbGLC
ViewSparsifier: Killing Redundancy in Multi-View Plant Phenotyping
Sep 10, 2025Plant phenotyping involves analyzing observable characteristics of plants to better understand their growth, health, and development. In the context of deep learning, this analysis is often approached through single-view classification or regression models. However, these methods often fail to capture all information required for accurate estimation of target phenotypic traits, which can adversely affect plant health assessment and harvest readiness prediction. To address this, the Growth Modelling (GroMo) Grand Challenge at ACM Multimedia 2025 provides a multi-view dataset featuring multiple plants and two tasks: Plant Age Prediction and Leaf Count Estimation. Each plant is photographed from multiple heights and angles, leading to significant overlap and redundancy in the captured information. To learn view-invariant embeddings, we incorporate 24 views, referred to as the selection vector, in a random selection. Our ViewSparsifier approach won both tasks. For further improvement and as a direction for future research, we also experimented with randomized view selection across all five height levels (120 views total), referred to as selection matrices.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
synth-dacl: Does Synthetic Defect Data Enhance Segmentation Accuracy and Robustness for Real-World Bridge Inspections?
Jun 17, 2025Adequate bridge inspection is increasingly challenging in many countries due to growing ailing stocks, compounded with a lack of staff and financial resources. Automating the key task of visual bridge inspection, classification of defects and building components on pixel level, improves efficiency, increases accuracy and enhances safety in the inspection process and resulting building assessment. Models overtaking this task must cope with an assortment of real-world conditions. They must be robust to variations in image quality, as well as background texture, as defects often appear on surfaces of diverse texture and degree of weathering. dacl10k is the largest and most diverse dataset for real-world concrete bridge inspections. However, the dataset exhibits class imbalance, which leads to notably poor model performance particularly when segmenting fine-grained classes such as cracks and cavities. This work introduces "synth-dacl", a compilation of three novel dataset extensions based on synthetic concrete textures. These extensions are designed to balance class distribution in dacl10k and enhance model performance, especially for crack and cavity segmentation. When incorporating the synth-dacl extensions, we observe substantial improvements in model robustness across 15 perturbed test sets. Notably, on the perturbed test set, a model trained on dacl10k combined with all synthetic extensions achieves a 2% increase in mean IoU, F1 score, Recall, and Precision compared to the same model trained solely on dacl10k.
Locality-Sensitive Hashing for Efficient Hard Negative Sampling in Contrastive Learning
May 23, 2025

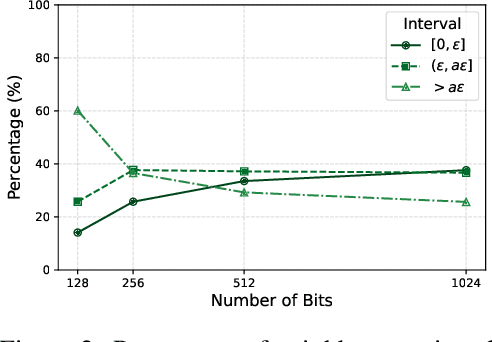

Contrastive learning is a representational learning paradigm in which a neural network maps data elements to feature vectors. It improves the feature space by forming lots with an anchor and examples that are either positive or negative based on class similarity. Hard negative examples, which are close to the anchor in the feature space but from a different class, improve learning performance. Finding such examples of high quality efficiently in large, high-dimensional datasets is computationally challenging. In this paper, we propose a GPU-friendly Locality-Sensitive Hashing (LSH) scheme that quantizes real-valued feature vectors into binary representations for approximate nearest neighbor search. We investigate its theoretical properties and evaluate it on several datasets from textual and visual domain. Our approach achieves comparable or better performance while requiring significantly less computation than existing hard negative mining strategies.
SoccerNet 2024 Challenges Results
Sep 16, 2024

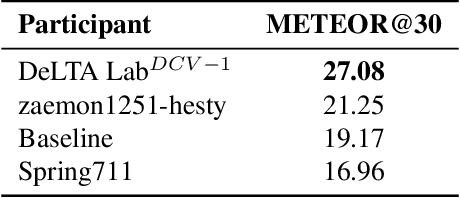
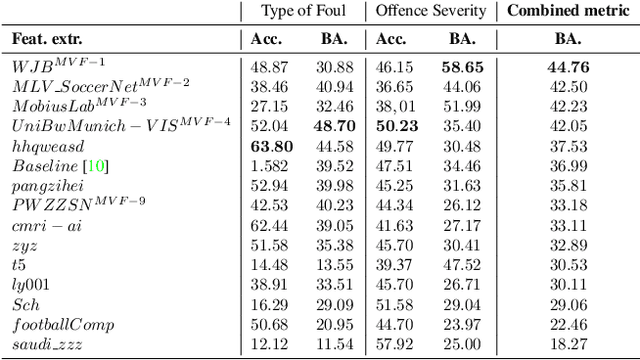
The SoccerNet 2024 challenges represent the fourth annual video understanding challenges organized by the SoccerNet team. These challenges aim to advance research across multiple themes in football, including broadcast video understanding, field understanding, and player understanding. This year, the challenges encompass four vision-based tasks. (1) Ball Action Spotting, focusing on precisely localizing when and which soccer actions related to the ball occur, (2) Dense Video Captioning, focusing on describing the broadcast with natural language and anchored timestamps, (3) Multi-View Foul Recognition, a novel task focusing on analyzing multiple viewpoints of a potential foul incident to classify whether a foul occurred and assess its severity, (4) Game State Reconstruction, another novel task focusing on reconstructing the game state from broadcast videos onto a 2D top-view map of the field. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
Cross-View Geolocalization and Disaster Mapping with Street-View and VHR Satellite Imagery: A Case Study of Hurricane IAN
Aug 13, 2024

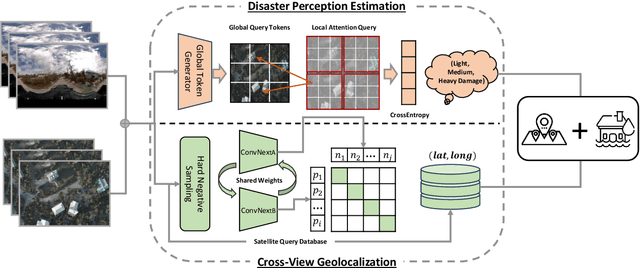

Nature disasters play a key role in shaping human-urban infrastructure interactions. Effective and efficient response to natural disasters is essential for building resilience and a sustainable urban environment. Two types of information are usually the most necessary and difficult to gather in disaster response. The first information is about disaster damage perception, which shows how badly people think that urban infrastructure has been damaged. The second information is geolocation awareness, which means how people whereabouts are made available. In this paper, we proposed a novel disaster mapping framework, namely CVDisaster, aiming at simultaneously addressing geolocalization and damage perception estimation using cross-view Street-View Imagery (SVI) and Very High-Resolution satellite imagery. CVDisaster consists of two cross-view models, where CVDisaster-Geoloc refers to a cross-view geolocalization model based on a contrastive learning objective with a Siamese ConvNeXt image encoder, and CVDisaster-Est is a cross-view classification model based on a Couple Global Context Vision Transformer (CGCViT). Taking Hurricane IAN as a case study, we evaluate the CVDisaster framework by creating a novel cross-view dataset (CVIAN) and conducting extensive experiments. As a result, we show that CVDisaster can achieve highly competitive performance (over 80% for geolocalization and 75% for damage perception estimation) with even limited fine-tuning efforts, which largely motivates future cross-view models and applications within a broader GeoAI research community. The data and code are publicly available at: https://github.com/tum-bgd/CVDisaster.
Unimodal Multi-Task Fusion for Emotional Mimicry Prediction
Mar 22, 2024



In this study, we propose a methodology for the Emotional Mimicry Intensity (EMI) Estimation task within the context of the 6th Workshop and Competition on Affective Behavior Analysis in-the-wild. Our approach leverages the Wav2Vec 2.0 framework, pre-trained on a comprehensive podcast dataset, to extract a broad range of audio features encompassing both linguistic and paralinguistic elements. We enhance feature representation through a fusion technique that integrates individual features with a global mean vector, introducing global contextual insights into our analysis. Additionally, we incorporate a pre-trained valence-arousal-dominance (VAD) module from the Wav2Vec 2.0 model. Our fusion employs a Long Short-Term Memory (LSTM) architecture for efficient temporal analysis of audio data. Utilizing only the provided audio data, our approach demonstrates significant improvements over the established baseline.
SoccerNet 2023 Challenges Results
Sep 12, 2023



The SoccerNet 2023 challenges were the third annual video understanding challenges organized by the SoccerNet team. For this third edition, the challenges were composed of seven vision-based tasks split into three main themes. The first theme, broadcast video understanding, is composed of three high-level tasks related to describing events occurring in the video broadcasts: (1) action spotting, focusing on retrieving all timestamps related to global actions in soccer, (2) ball action spotting, focusing on retrieving all timestamps related to the soccer ball change of state, and (3) dense video captioning, focusing on describing the broadcast with natural language and anchored timestamps. The second theme, field understanding, relates to the single task of (4) camera calibration, focusing on retrieving the intrinsic and extrinsic camera parameters from images. The third and last theme, player understanding, is composed of three low-level tasks related to extracting information about the players: (5) re-identification, focusing on retrieving the same players across multiple views, (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams, and (7) jersey number recognition, focusing on recognizing the jersey number of players from tracklets. Compared to the previous editions of the SoccerNet challenges, tasks (2-3-7) are novel, including new annotations and data, task (4) was enhanced with more data and annotations, and task (6) now focuses on end-to-end approaches. More information on the tasks, challenges, and leaderboards are available on https://www.soccer-net.org. Baselines and development kits can be found on https://github.com/SoccerNet.
Orientation-Guided Contrastive Learning for UAV-View Geo-Localisation
Aug 02, 2023



Retrieving relevant multimedia content is one of the main problems in a world that is increasingly data-driven. With the proliferation of drones, high quality aerial footage is now available to a wide audience for the first time. Integrating this footage into applications can enable GPS-less geo-localisation or location correction. In this paper, we present an orientation-guided training framework for UAV-view geo-localisation. Through hierarchical localisation orientations of the UAV images are estimated in relation to the satellite imagery. We propose a lightweight prediction module for these pseudo labels which predicts the orientation between the different views based on the contrastive learned embeddings. We experimentally demonstrate that this prediction supports the training and outperforms previous approaches. The extracted pseudo-labels also enable aligned rotation of the satellite image as augmentation to further strengthen the generalisation. During inference, we no longer need this orientation module, which means that no additional computations are required. We achieve state-of-the-art results on both the University-1652 and University-160k datasets.