 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-View Geolocalization and Disaster Mapping with Street-View and VHR Satellite Imagery: A Case Study of Hurricane IAN
Aug 13, 2024

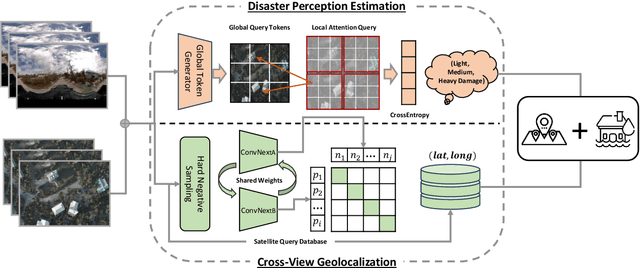

Nature disasters play a key role in shaping human-urban infrastructure interactions. Effective and efficient response to natural disasters is essential for building resilience and a sustainable urban environment. Two types of information are usually the most necessary and difficult to gather in disaster response. The first information is about disaster damage perception, which shows how badly people think that urban infrastructure has been damaged. The second information is geolocation awareness, which means how people whereabouts are made available. In this paper, we proposed a novel disaster mapping framework, namely CVDisaster, aiming at simultaneously addressing geolocalization and damage perception estimation using cross-view Street-View Imagery (SVI) and Very High-Resolution satellite imagery. CVDisaster consists of two cross-view models, where CVDisaster-Geoloc refers to a cross-view geolocalization model based on a contrastive learning objective with a Siamese ConvNeXt image encoder, and CVDisaster-Est is a cross-view classification model based on a Couple Global Context Vision Transformer (CGCViT). Taking Hurricane IAN as a case study, we evaluate the CVDisaster framework by creating a novel cross-view dataset (CVIAN) and conducting extensive experiments. As a result, we show that CVDisaster can achieve highly competitive performance (over 80% for geolocalization and 75% for damage perception estimation) with even limited fine-tuning efforts, which largely motivates future cross-view models and applications within a broader GeoAI research community. The data and code are publicly available at: https://github.com/tum-bgd/CVDisaster.
Clean Implicit 3D Structure from Noisy 2D STEM Images
Mar 29, 2022
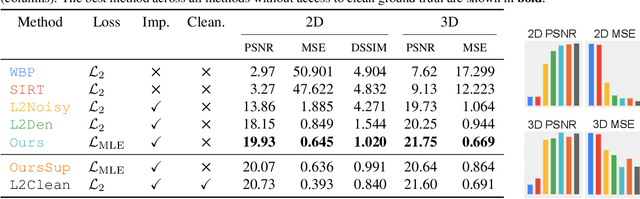
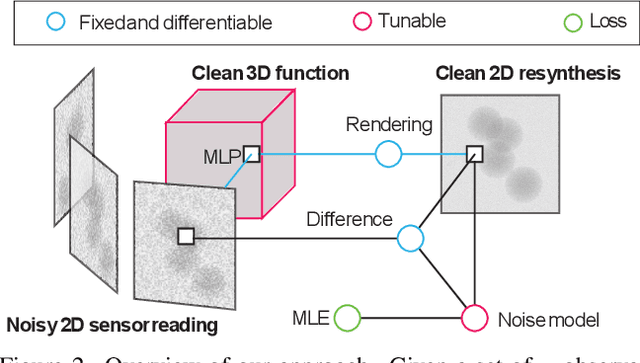

Scanning Transmission Electron Microscopes (STEMs) acquire 2D images of a 3D sample on the scale of individual cell components. Unfortunately, these 2D images can be too noisy to be fused into a useful 3D structure and facilitating good denoisers is challenging due to the lack of clean-noisy pairs. Additionally, representing a detailed 3D structure can be difficult even for clean data when using regular 3D grids. Addressing these two limitations, we suggest a differentiable image formation model for STEM, allowing to learn a joint model of 2D sensor noise in STEM together with an implicit 3D model. We show, that the combination of these models are able to successfully disentangle 3D signal and noise without supervision and outperform at the same time several baselines on synthetic and real data.