 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocality-Sensitive Hashing for Efficient Hard Negative Sampling in Contrastive Learning
May 23, 2025Contrastive learning is a representational learning paradigm in which a neural network maps data elements to feature vectors. It improves the feature space by forming lots with an anchor and examples that are either positive or negative based on class similarity. Hard negative examples, which are close to the anchor in the feature space but from a different class, improve learning performance. Finding such examples of high quality efficiently in large, high-dimensional datasets is computationally challenging. In this paper, we propose a GPU-friendly Locality-Sensitive Hashing (LSH) scheme that quantizes real-valued feature vectors into binary representations for approximate nearest neighbor search. We investigate its theoretical properties and evaluate it on several datasets from textual and visual domain. Our approach achieves comparable or better performance while requiring significantly less computation than existing hard negative mining strategies.
Cross-View Geolocalization and Disaster Mapping with Street-View and VHR Satellite Imagery: A Case Study of Hurricane IAN
Aug 13, 2024

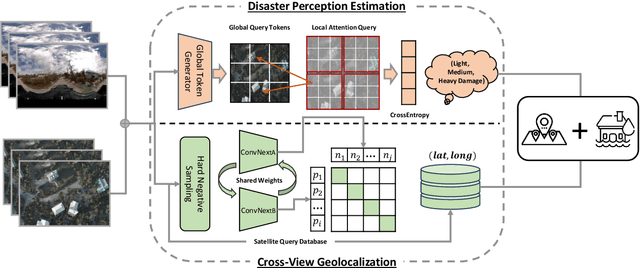

Nature disasters play a key role in shaping human-urban infrastructure interactions. Effective and efficient response to natural disasters is essential for building resilience and a sustainable urban environment. Two types of information are usually the most necessary and difficult to gather in disaster response. The first information is about disaster damage perception, which shows how badly people think that urban infrastructure has been damaged. The second information is geolocation awareness, which means how people whereabouts are made available. In this paper, we proposed a novel disaster mapping framework, namely CVDisaster, aiming at simultaneously addressing geolocalization and damage perception estimation using cross-view Street-View Imagery (SVI) and Very High-Resolution satellite imagery. CVDisaster consists of two cross-view models, where CVDisaster-Geoloc refers to a cross-view geolocalization model based on a contrastive learning objective with a Siamese ConvNeXt image encoder, and CVDisaster-Est is a cross-view classification model based on a Couple Global Context Vision Transformer (CGCViT). Taking Hurricane IAN as a case study, we evaluate the CVDisaster framework by creating a novel cross-view dataset (CVIAN) and conducting extensive experiments. As a result, we show that CVDisaster can achieve highly competitive performance (over 80% for geolocalization and 75% for damage perception estimation) with even limited fine-tuning efforts, which largely motivates future cross-view models and applications within a broader GeoAI research community. The data and code are publicly available at: https://github.com/tum-bgd/CVDisaster.
Cross-City Matters: A Multimodal Remote Sensing Benchmark Dataset for Cross-City Semantic Segmentation using High-Resolution Domain Adaptation Networks
Oct 03, 2023



Artificial intelligence (AI) approaches nowadays have gained remarkable success in single-modality-dominated remote sensing (RS) applications, especially with an emphasis on individual urban environments (e.g., single cities or regions). Yet these AI models tend to meet the performance bottleneck in the case studies across cities or regions, due to the lack of diverse RS information and cutting-edge solutions with high generalization ability. To this end, we build a new set of multimodal remote sensing benchmark datasets (including hyperspectral, multispectral, SAR) for the study purpose of the cross-city semantic segmentation task (called C2Seg dataset), which consists of two cross-city scenes, i.e., Berlin-Augsburg (in Germany) and Beijing-Wuhan (in China). Beyond the single city, we propose a high-resolution domain adaptation network, HighDAN for short, to promote the AI model's generalization ability from the multi-city environments. HighDAN is capable of retaining the spatially topological structure of the studied urban scene well in a parallel high-to-low resolution fusion fashion but also closing the gap derived from enormous differences of RS image representations between different cities by means of adversarial learning. In addition, the Dice loss is considered in HighDAN to alleviate the class imbalance issue caused by factors across cities. Extensive experiments conducted on the C2Seg dataset show the superiority of our HighDAN in terms of segmentation performance and generalization ability, compared to state-of-the-art competitors. The C2Seg dataset and the semantic segmentation toolbox (involving the proposed HighDAN) will be available publicly at https://github.com/danfenghong.
Orientation-Guided Contrastive Learning for UAV-View Geo-Localisation
Aug 02, 2023



Retrieving relevant multimedia content is one of the main problems in a world that is increasingly data-driven. With the proliferation of drones, high quality aerial footage is now available to a wide audience for the first time. Integrating this footage into applications can enable GPS-less geo-localisation or location correction. In this paper, we present an orientation-guided training framework for UAV-view geo-localisation. Through hierarchical localisation orientations of the UAV images are estimated in relation to the satellite imagery. We propose a lightweight prediction module for these pseudo labels which predicts the orientation between the different views based on the contrastive learned embeddings. We experimentally demonstrate that this prediction supports the training and outperforms previous approaches. The extracted pseudo-labels also enable aligned rotation of the satellite image as augmentation to further strengthen the generalisation. During inference, we no longer need this orientation module, which means that no additional computations are required. We achieve state-of-the-art results on both the University-1652 and University-160k datasets.
Semi-supervised Learning from Street-View Images and OpenStreetMap for Automatic Building Height Estimation
Jul 05, 2023



Accurate building height estimation is key to the automatic derivation of 3D city models from emerging big geospatial data, including Volunteered Geographical Information (VGI). However, an automatic solution for large-scale building height estimation based on low-cost VGI data is currently missing. The fast development of VGI data platforms, especially OpenStreetMap (OSM) and crowdsourced street-view images (SVI), offers a stimulating opportunity to fill this research gap. In this work, we propose a semi-supervised learning (SSL) method of automatically estimating building height from Mapillary SVI and OSM data to generate low-cost and open-source 3D city modeling in LoD1. The proposed method consists of three parts: first, we propose an SSL schema with the option of setting a different ratio of "pseudo label" during the supervised regression; second, we extract multi-level morphometric features from OSM data (i.e., buildings and streets) for the purposed of inferring building height; last, we design a building floor estimation workflow with a pre-trained facade object detection network to generate "pseudo label" from SVI and assign it to the corresponding OSM building footprint. In a case study, we validate the proposed SSL method in the city of Heidelberg, Germany and evaluate the model performance against the reference data of building heights. Based on three different regression models, namely Random Forest (RF), Support Vector Machine (SVM), and Convolutional Neural Network (CNN), the SSL method leads to a clear performance boosting in estimating building heights with a Mean Absolute Error (MAE) around 2.1 meters, which is competitive to state-of-the-art approaches. The preliminary result is promising and motivates our future work in scaling up the proposed method based on low-cost VGI data, with possibilities in even regions and areas with diverse data quality and availability.
Geo-Information Harvesting from Social Media Data
Nov 01, 2022As unconventional sources of geo-information, massive imagery and text messages from open platforms and social media form a temporally quasi-seamless, spatially multi-perspective stream, but with unknown and diverse quality. Due to its complementarity to remote sensing data, geo-information from these sources offers promising perspectives, but harvesting is not trivial due to its data characteristics. In this article, we address key aspects in the field, including data availability, analysis-ready data preparation and data management, geo-information extraction from social media text messages and images, and the fusion of social media and remote sensing data. We then showcase some exemplary geographic applications. In addition, we present the first extensive discussion of ethical considerations of social media data in the context of geo-information harvesting and geographic applications. With this effort, we wish to stimulate curiosity and lay the groundwork for researchers who intend to explore social media data for geo-applications. We encourage the community to join forces by sharing their code and data.