 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Road Crack Localization to Guide Highway Maintenance
Jan 21, 2026Highway networks are crucial for economic prosperity. Climate change-induced temperature fluctuations are exacerbating stress on road pavements, resulting in elevated maintenance costs. This underscores the need for targeted and efficient maintenance strategies. This study investigates the potential of open-source data to guide highway infrastructure maintenance. The proposed framework integrates airborne imagery and OpenStreetMap (OSM) to fine-tune YOLOv11 for highway crack localization. To demonstrate the framework's real-world applicability, a Swiss Relative Highway Crack Density (RHCD) index was calculated to inform nationwide highway maintenance. The crack classification model achieved an F1-score of $0.84$ for the positive class (crack) and $0.97$ for the negative class (no crack). The Swiss RHCD index exhibited weak correlations with Long-term Land Surface Temperature Amplitudes (LT-LST-A) (Pearson's $r\ = -0.05$) and Traffic Volume (TV) (Pearson's $r\ = 0.17$), underlining the added value of this novel index for guiding maintenance over other data. Significantly high RHCD values were observed near urban centers and intersections, providing contextual validation for the predictions. These findings highlight the value of open-source data sharing to drive innovation, ultimately enabling more efficient solutions in the public sector.
Assessing Building Heat Resilience Using UAV and Street-View Imagery with Coupled Global Context Vision Transformer
Jan 16, 2026Climate change is intensifying human heat exposure, particularly in densely built urban centers of the Global South. Low-cost construction materials and high thermal-mass surfaces further exacerbate this risk. Yet scalable methods for assessing such heat-relevant building attributes remain scarce. We propose a machine learning framework that fuses openly available unmanned aerial vehicle (UAV) and street-view (SV) imagery via a coupled global context vision transformer (CGCViT) to learn heat-relevant representations of urban structures. Thermal infrared (TIR) measurements from HotSat-1 are used to quantify the relationship between building attributes and heat-associated health risks. Our dual-modality cross-view learning approach outperforms the best single-modality models by up to $9.3\%$, demonstrating that UAV and SV imagery provide valuable complementary perspectives on urban structures. The presence of vegetation surrounding buildings (versus no vegetation), brighter roofing (versus darker roofing), and roofing made of concrete, clay, or wood (versus metal or tarpaulin) are all significantly associated with lower HotSat-1 TIR values. Deployed across the city of Dar es Salaam, Tanzania, the proposed framework illustrates how household-level inequalities in heat exposure - often linked to socio-economic disadvantage and reflected in building materials - can be identified and addressed using machine learning. Our results point to the critical role of localized, data-driven risk assessment in shaping climate adaptation strategies that deliver equitable outcomes.
Paved or unpaved? A Deep Learning derived Road Surface Global Dataset from Mapillary Street-View Imagery
Oct 29, 2024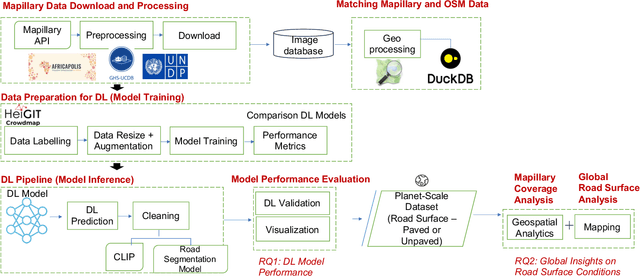

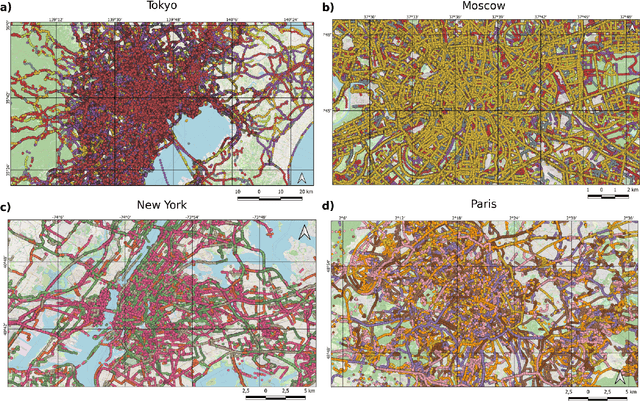

We have released an open dataset with global coverage on road surface characteristics (paved or unpaved) derived utilising 105 million images from the world's largest crowdsourcing-based street view platform, Mapillary, leveraging state-of-the-art geospatial AI methods. We propose a hybrid deep learning approach which combines SWIN-Transformer based road surface prediction and CLIP-and-DL segmentation based thresholding for filtering of bad quality images. The road surface prediction results have been matched and integrated with OpenStreetMap (OSM) road geometries. This study provides global data insights derived from maps and statistics about spatial distribution of Mapillary coverage and road pavedness on a continent and countries scale, with rural and urban distinction. This dataset expands the availability of global road surface information by over 3 million kilometers, now representing approximately 36% of the total length of the global road network. Most regions showed moderate to high paved road coverage (60-80%), but significant gaps were noted in specific areas of Africa and Asia. Urban areas tend to have near-complete paved coverage, while rural regions display more variability. Model validation against OSM surface data achieved strong performance, with F1 scores for paved roads between 91-97% across continents. Taking forward the work of Mapillary and their contributors and enrichment of OSM road attributes, our work provides valuable insights for applications in urban planning, disaster routing, logistics optimisation and addresses various Sustainable Development Goals (SDGS): especially SDGs 1 (No poverty), 3 (Good health and well-being), 8 (Decent work and economic growth), 9 (Industry, Innovation and Infrastructure), 11 (Sustainable cities and communities), 12 (Responsible consumption and production), and 13 (Climate action).
Distortions in Judged Spatial Relations in Large Language Models: The Dawn of Natural Language Geographic Data?
Jan 08, 2024

We present a benchmark for assessing the capability of Large Language Models (LLMs) to discern intercardinal directions between geographic locations and apply it to three prominent LLMs: GPT-3.5, GPT-4, and Llama-2. This benchmark specifically evaluates whether LLMs exhibit a hierarchical spatial bias similar to humans, where judgments about individual locations' spatial relationships are influenced by the perceived relationships of the larger groups that contain them. To investigate this, we formulated 14 questions focusing on well-known American cities. Seven questions were designed to challenge the LLMs with scenarios potentially influenced by the orientation of larger geographical units, such as states or countries, while the remaining seven targeted locations less susceptible to such hierarchical categorization. Among the tested models, GPT-4 exhibited superior performance with 55.3% accuracy, followed by GPT-3.5 at 47.3%, and Llama-2 at 44.7%. The models showed significantly reduced accuracy on tasks with suspected hierarchical bias. For example, GPT-4's accuracy dropped to 32.9% on these tasks, compared to 85.7% on others. Despite these inaccuracies, the models identified the nearest cardinal direction in most cases, suggesting associative learning, embodying human-like misconceptions. We discuss the potential of text-based data representing geographic relationships directly to improve the spatial reasoning capabilities of LLMs.
Cross-City Matters: A Multimodal Remote Sensing Benchmark Dataset for Cross-City Semantic Segmentation using High-Resolution Domain Adaptation Networks
Oct 03, 2023



Artificial intelligence (AI) approaches nowadays have gained remarkable success in single-modality-dominated remote sensing (RS) applications, especially with an emphasis on individual urban environments (e.g., single cities or regions). Yet these AI models tend to meet the performance bottleneck in the case studies across cities or regions, due to the lack of diverse RS information and cutting-edge solutions with high generalization ability. To this end, we build a new set of multimodal remote sensing benchmark datasets (including hyperspectral, multispectral, SAR) for the study purpose of the cross-city semantic segmentation task (called C2Seg dataset), which consists of two cross-city scenes, i.e., Berlin-Augsburg (in Germany) and Beijing-Wuhan (in China). Beyond the single city, we propose a high-resolution domain adaptation network, HighDAN for short, to promote the AI model's generalization ability from the multi-city environments. HighDAN is capable of retaining the spatially topological structure of the studied urban scene well in a parallel high-to-low resolution fusion fashion but also closing the gap derived from enormous differences of RS image representations between different cities by means of adversarial learning. In addition, the Dice loss is considered in HighDAN to alleviate the class imbalance issue caused by factors across cities. Extensive experiments conducted on the C2Seg dataset show the superiority of our HighDAN in terms of segmentation performance and generalization ability, compared to state-of-the-art competitors. The C2Seg dataset and the semantic segmentation toolbox (involving the proposed HighDAN) will be available publicly at https://github.com/danfenghong.
Semi-supervised Learning from Street-View Images and OpenStreetMap for Automatic Building Height Estimation
Jul 05, 2023



Accurate building height estimation is key to the automatic derivation of 3D city models from emerging big geospatial data, including Volunteered Geographical Information (VGI). However, an automatic solution for large-scale building height estimation based on low-cost VGI data is currently missing. The fast development of VGI data platforms, especially OpenStreetMap (OSM) and crowdsourced street-view images (SVI), offers a stimulating opportunity to fill this research gap. In this work, we propose a semi-supervised learning (SSL) method of automatically estimating building height from Mapillary SVI and OSM data to generate low-cost and open-source 3D city modeling in LoD1. The proposed method consists of three parts: first, we propose an SSL schema with the option of setting a different ratio of "pseudo label" during the supervised regression; second, we extract multi-level morphometric features from OSM data (i.e., buildings and streets) for the purposed of inferring building height; last, we design a building floor estimation workflow with a pre-trained facade object detection network to generate "pseudo label" from SVI and assign it to the corresponding OSM building footprint. In a case study, we validate the proposed SSL method in the city of Heidelberg, Germany and evaluate the model performance against the reference data of building heights. Based on three different regression models, namely Random Forest (RF), Support Vector Machine (SVM), and Convolutional Neural Network (CNN), the SSL method leads to a clear performance boosting in estimating building heights with a Mean Absolute Error (MAE) around 2.1 meters, which is competitive to state-of-the-art approaches. The preliminary result is promising and motivates our future work in scaling up the proposed method based on low-cost VGI data, with possibilities in even regions and areas with diverse data quality and availability.