 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning Inspired ControlNet Guidance for Augmenting Semantic Segmentation Datasets
Mar 12, 2025



Recent advances in conditional image generation from diffusion models have shown great potential in achieving impressive image quality while preserving the constraints introduced by the user. In particular, ControlNet enables precise alignment between ground truth segmentation masks and the generated image content, allowing the enhancement of training datasets in segmentation tasks. This raises a key question: Can ControlNet additionally be guided to generate the most informative synthetic samples for a specific task? Inspired by active learning, where the most informative real-world samples are selected based on sample difficulty or model uncertainty, we propose the first approach to integrate active learning-based selection metrics into the backward diffusion process for sample generation. Specifically, we explore uncertainty, query by committee, and expected model change, which are commonly used in active learning, and demonstrate their application for guiding the sample generation process through gradient approximation. Our method is training-free, modifying only the backward diffusion process, allowing it to be used on any pretrained ControlNet. Using this process, we show that segmentation models trained with guided synthetic data outperform those trained on non-guided synthetic data. Our work underscores the need for advanced control mechanisms for diffusion-based models, which are not only aligned with image content but additionally downstream task performance, highlighting the true potential of synthetic data generation.
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
Clean Implicit 3D Structure from Noisy 2D STEM Images
Mar 29, 2022
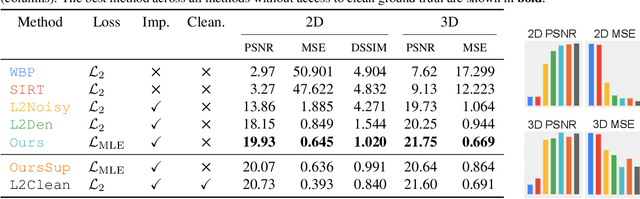
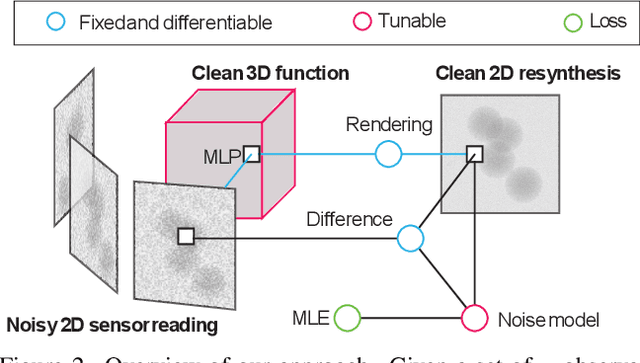

Scanning Transmission Electron Microscopes (STEMs) acquire 2D images of a 3D sample on the scale of individual cell components. Unfortunately, these 2D images can be too noisy to be fused into a useful 3D structure and facilitating good denoisers is challenging due to the lack of clean-noisy pairs. Additionally, representing a detailed 3D structure can be difficult even for clean data when using regular 3D grids. Addressing these two limitations, we suggest a differentiable image formation model for STEM, allowing to learn a joint model of 2D sensor noise in STEM together with an implicit 3D model. We show, that the combination of these models are able to successfully disentangle 3D signal and noise without supervision and outperform at the same time several baselines on synthetic and real data.