 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCutS3D: Cutting Semantics in 3D for 2D Unsupervised Instance Segmentation
Nov 26, 2024Traditionally, algorithms that learn to segment object instances in 2D images have heavily relied on large amounts of human-annotated data. Only recently, novel approaches have emerged tackling this problem in an unsupervised fashion. Generally, these approaches first generate pseudo-masks and then train a class-agnostic detector. While such methods deliver the current state of the art, they often fail to correctly separate instances overlapping in 2D image space since only semantics are considered. To tackle this issue, we instead propose to cut the semantic masks in 3D to obtain the final 2D instances by utilizing a point cloud representation of the scene. Furthermore, we derive a Spatial Importance function, which we use to resharpen the semantics along the 3D borders of instances. Nevertheless, these pseudo-masks are still subject to mask ambiguity. To address this issue, we further propose to augment the training of a class-agnostic detector with three Spatial Confidence components aiming to isolate a clean learning signal. With these contributions, our approach outperforms competing methods across multiple standard benchmarks for unsupervised instance segmentation and object detection.
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
ClusterNet: A Perception-Based Clustering Model for Scattered Data
Apr 27, 2023Cluster separation in scatterplots is a task that is typically tackled by widely used clustering techniques, such as for instance k-means or DBSCAN. However, as these algorithms are based on non-perceptual metrics, their output often does not reflect human cluster perception. To bridge the gap between human cluster perception and machine-computed clusters, we propose a learning strategy which directly operates on scattered data. To learn perceptual cluster separation on this data, we crowdsourced a large scale dataset, consisting of 7,320 point-wise cluster affiliations for bivariate data, which has been labeled by 384 human crowd workers. Based on this data, we were able to train ClusterNet, a point-based deep learning model, trained to reflect human perception of cluster separability. In order to train ClusterNet on human annotated data, we omit rendering scatterplots on a 2D canvas, but rather use a PointNet++ architecture enabling inference on point clouds directly. In this work, we provide details on how we collected our dataset, report statistics of the resulting annotations, and investigate perceptual agreement of cluster separation for real-world data. We further report the training and evaluation protocol of ClusterNet and introduce a novel metric, that measures the accuracy between a clustering technique and a group of human annotators. Finally, we compare our approach against existing state-of-the-art clustering techniques.
Monocular Depth Estimation for Semi-Transparent Volume Renderings
Jun 27, 2022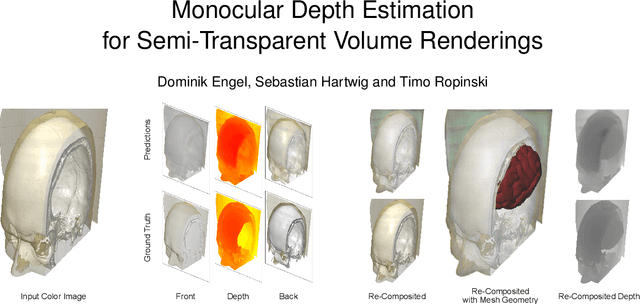
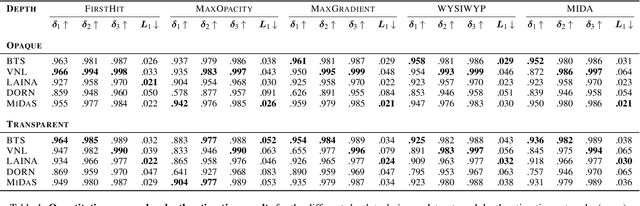
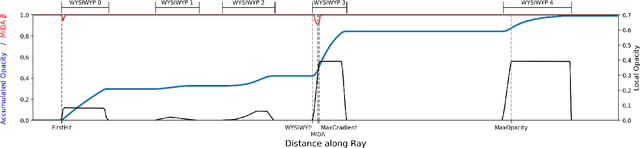
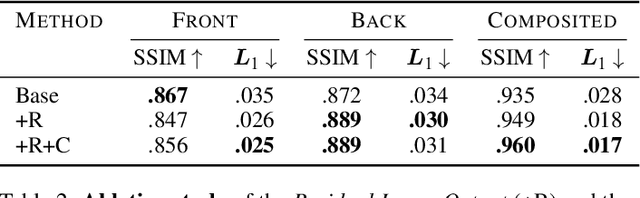
Neural networks have shown great success in extracting geometric information from color images. Especially, monocular depth estimation networks are increasingly reliable in real-world scenes. In this work we investigate the applicability of such monocular depth estimation networks to semi-transparent volume rendered images. As depth is notoriously difficult to define in a volumetric scene without clearly defined surfaces, we consider different depth computations that have emerged in practice, and compare state-of-the-art monocular depth estimation approaches for these different interpretations during an evaluation considering different degrees of opacity in the renderings. Additionally, we investigate how these networks can be extended to further obtain color and opacity information, in order to create a layered representation of the scene based on a single color image. This layered representation consists of spatially separated semi-transparent intervals that composite to the original input rendering. In our experiments we show that adaptions of existing approaches to monocular depth estimation perform well on semi-transparent volume renderings, which has several applications in the area of scientific visualization.
Training Object Detectors on Synthetic Images Containing Reflecting Materials
Mar 29, 2019
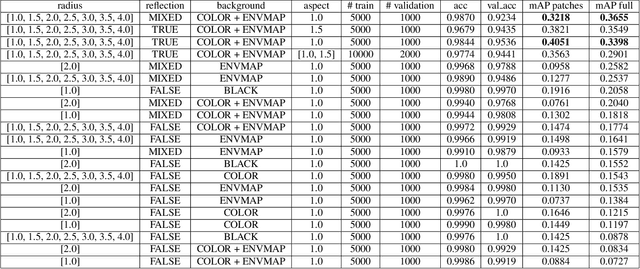
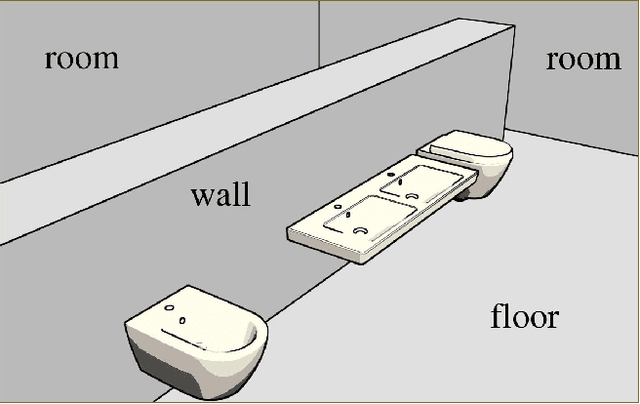
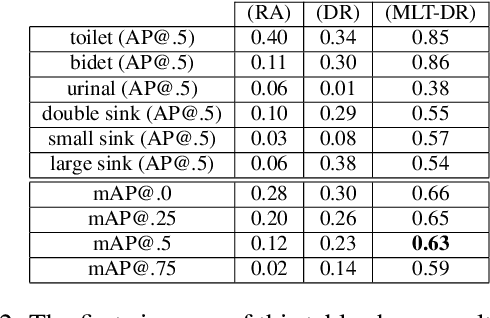
One of the grand challenges of deep learning is the requirement to obtain large labeled training data sets. While synthesized data sets can be used to overcome this challenge, it is important that these data sets close the reality gap, i.e., a model trained on synthetic image data is able to generalize to real images. Whereas, the reality gap can be considered bridged in several application scenarios, training on synthesized images containing reflecting materials requires further research. Since the appearance of objects with reflecting materials is dominated by the surrounding environment, this interaction needs to be considered during training data generation. Therefore, within this paper we examine the effect of reflecting materials in the context of synthetic image generation for training object detectors. We investigate the influence of rendering approach used for image synthesis, the effect of domain randomization, as well as the amount of used training data. To be able to compare our results to the state-of-the-art, we focus on indoor scenes as they have been investigated extensively. Within this scenario, bathroom furniture is a natural choice for objects with reflecting materials, for which we report our findings on real and synthetic testing data.