 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficientMonoHair: Fast Strand-Level Reconstruction from Monocular Video via Multi-View Direction Fusion
Apr 07, 2026Strand-level hair geometry reconstruction is a fundamental problem in virtual human modeling and the digitization of hairstyles. However, existing methods still suffer from a significant trade-off between accuracy and efficiency. Implicit neural representations can capture the global hair shape but often fail to preserve fine-grained strand details, while explicit optimization-based approaches achieve high-fidelity reconstructions at the cost of heavy computation and poor scalability. To address this issue, we propose EfficientMonoHair, a fast and accurate framework that combines the implicit neural network with multi-view geometric fusion for strand-level reconstruction from monocular video. Our method introduces a fusion-patch-based multi-view optimization that reduces the number of optimization iterations for point cloud direction, as well as a novel parallel hair-growing strategy that relaxes voxel occupancy constraints, allowing large-scale strand tracing to remain stable and robust even under inaccurate or noisy orientation fields. Extensive experiments on representative real-world hairstyles demonstrate that our method can robustly reconstruct high-fidelity strand geometries with accuracy. On synthetic benchmarks, our method achieves reconstruction quality comparable to state-of-the-art methods, while improving runtime efficiency by nearly an order of magnitude.
ClickAIXR: On-Device Multimodal Vision-Language Interaction with Real-World Objects in Extended Reality
Apr 06, 2026We present ClickAIXR, a novel on-device framework for multimodal vision-language interaction with objects in extended reality (XR). Unlike prior systems that rely on cloud-based AI (e.g., ChatGPT) or gaze-based selection (e.g., GazePointAR), ClickAIXR integrates an on-device vision-language model (VLM) with a controller-based object selection paradigm, enabling users to precisely click on real-world objects in XR. Once selected, the object image is processed locally by the VLM to answer natural language questions through both text and speech. This object-centered interaction reduces ambiguity inherent in gaze- or voice-only interfaces and improves transparency by performing all inference on-device, addressing concerns around privacy and latency. We implemented ClickAIXR in the Magic Leap SDK (C API) with ONNX-based local VLM inference. We conducted a user study comparing ClickAIXR with Gemini 2.5 Flash and ChatGPT 5, evaluating usability, trust, and user satisfaction. Results show that latency is moderate and user experience is acceptable. Our findings demonstrate the potential of click-based object selection combined with on-device AI to advance trustworthy, privacy-preserving XR interactions. The source code and supplementary materials are available at: nanovis.org/ClickAIXR.html
S2D: Sparse-To-Dense Keymask Distillation for Unsupervised Video Instance Segmentation
Dec 16, 2025In recent years, the state-of-the-art in unsupervised video instance segmentation has heavily relied on synthetic video data, generated from object-centric image datasets such as ImageNet. However, video synthesis by artificially shifting and scaling image instance masks fails to accurately model realistic motion in videos, such as perspective changes, movement by parts of one or multiple instances, or camera motion. To tackle this issue, we propose an unsupervised video instance segmentation model trained exclusively on real video data. We start from unsupervised instance segmentation masks on individual video frames. However, these single-frame segmentations exhibit temporal noise and their quality varies through the video. Therefore, we establish temporal coherence by identifying high-quality keymasks in the video by leveraging deep motion priors. The sparse keymask pseudo-annotations are then used to train a segmentation model for implicit mask propagation, for which we propose a Sparse-To-Dense Distillation approach aided by a Temporal DropLoss. After training the final model on the resulting dense labelset, our approach outperforms the current state-of-the-art across various benchmarks.
CutS3D: Cutting Semantics in 3D for 2D Unsupervised Instance Segmentation
Nov 26, 2024Traditionally, algorithms that learn to segment object instances in 2D images have heavily relied on large amounts of human-annotated data. Only recently, novel approaches have emerged tackling this problem in an unsupervised fashion. Generally, these approaches first generate pseudo-masks and then train a class-agnostic detector. While such methods deliver the current state of the art, they often fail to correctly separate instances overlapping in 2D image space since only semantics are considered. To tackle this issue, we instead propose to cut the semantic masks in 3D to obtain the final 2D instances by utilizing a point cloud representation of the scene. Furthermore, we derive a Spatial Importance function, which we use to resharpen the semantics along the 3D borders of instances. Nevertheless, these pseudo-masks are still subject to mask ambiguity. To address this issue, we further propose to augment the training of a class-agnostic detector with three Spatial Confidence components aiming to isolate a clean learning signal. With these contributions, our approach outperforms competing methods across multiple standard benchmarks for unsupervised instance segmentation and object detection.
Evaluating Text-to-Image Synthesis: Survey and Taxonomy of Image Quality Metrics
Mar 29, 2024Recent advances in text-to-image synthesis enabled through a combination of language and vision foundation models have led to a proliferation of the tools available and an increased attention to the field. When conducting text-to-image synthesis, a central goal is to ensure that the content between text and image is aligned. As such, there exist numerous evaluation metrics that aim to mimic human judgement. However, it is often unclear which metric to use for evaluating text-to-image synthesis systems as their evaluation is highly nuanced. In this work, we provide a comprehensive overview of existing text-to-image evaluation metrics. Based on our findings, we propose a new taxonomy for categorizing these metrics. Our taxonomy is grounded in the assumption that there are two main quality criteria, namely compositionality and generality, which ideally map to human preferences. Ultimately, we derive guidelines for practitioners conducting text-to-image evaluation, discuss open challenges of evaluation mechanisms, and surface limitations of current metrics.
Attention-Guided Masked Autoencoders For Learning Image Representations
Feb 23, 2024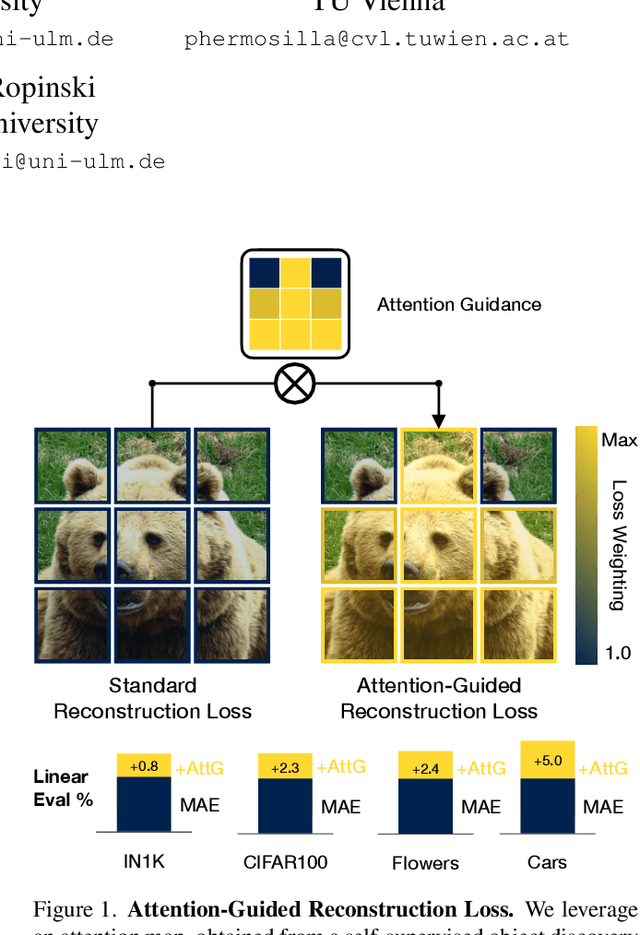
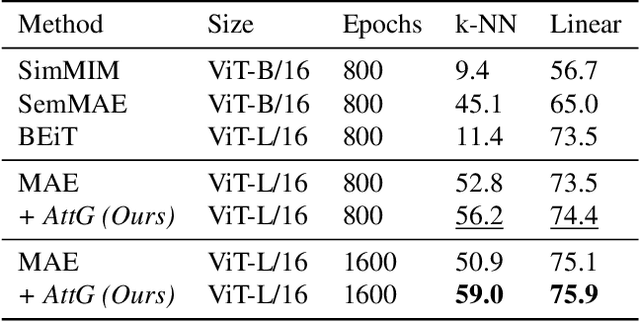
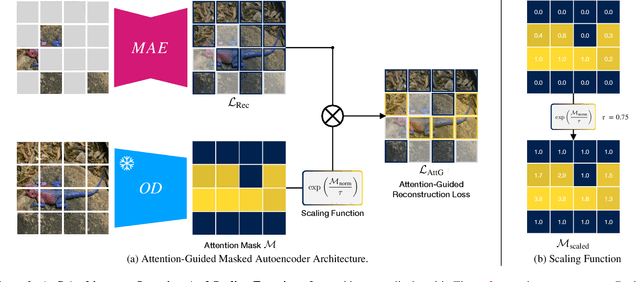
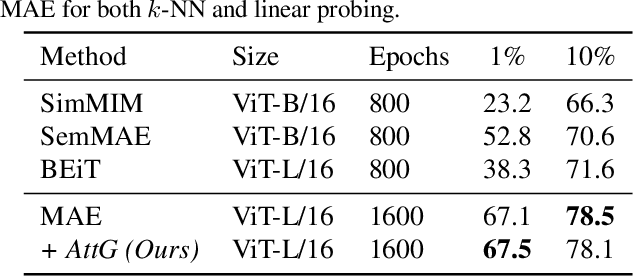
Masked autoencoders (MAEs) have established themselves as a powerful method for unsupervised pre-training for computer vision tasks. While vanilla MAEs put equal emphasis on reconstructing the individual parts of the image, we propose to inform the reconstruction process through an attention-guided loss function. By leveraging advances in unsupervised object discovery, we obtain an attention map of the scene which we employ in the loss function to put increased emphasis on reconstructing relevant objects, thus effectively incentivizing the model to learn more object-focused representations without compromising the established masking strategy. Our evaluations show that our pre-trained models learn better latent representations than the vanilla MAE, demonstrated by improved linear probing and k-NN classification results on several benchmarks while at the same time making ViTs more robust against varying backgrounds.
Spatially Guiding Unsupervised Semantic Segmentation Through Depth-Informed Feature Distillation and Sampling
Sep 21, 2023Traditionally, training neural networks to perform semantic segmentation required expensive human-made annotations. But more recently, advances in the field of unsupervised learning have made significant progress on this issue and towards closing the gap to supervised algorithms. To achieve this, semantic knowledge is distilled by learning to correlate randomly sampled features from images across an entire dataset. In this work, we build upon these advances by incorporating information about the structure of the scene into the training process through the use of depth information. We achieve this by (1) learning depth-feature correlation by spatially correlate the feature maps with the depth maps to induce knowledge about the structure of the scene and (2) implementing farthest-point sampling to more effectively select relevant features by utilizing 3D sampling techniques on depth information of the scene. Finally, we demonstrate the effectiveness of our technical contributions through extensive experimentation and present significant improvements in performance across multiple benchmark datasets.
Leveraging Self-Supervised Vision Transformers for Neural Transfer Function Design
Sep 04, 2023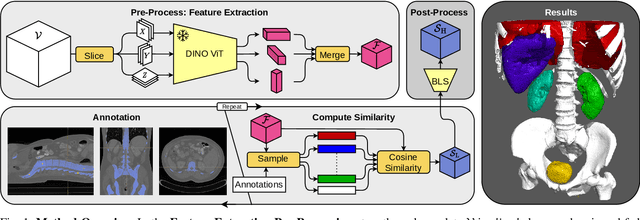
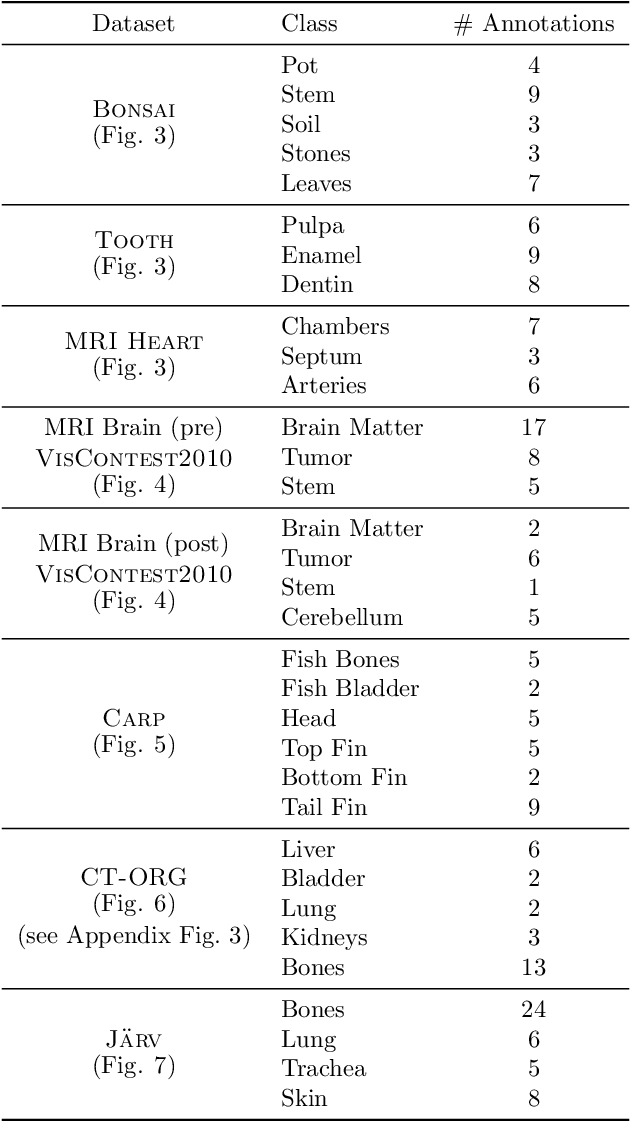
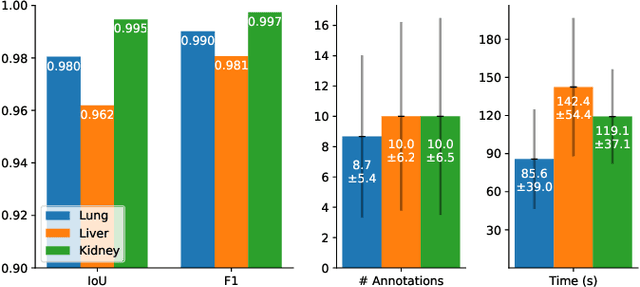
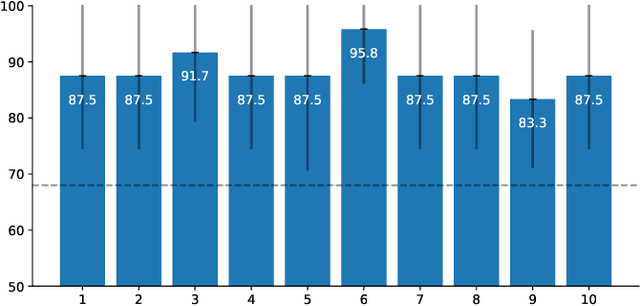
In volume rendering, transfer functions are used to classify structures of interest, and to assign optical properties such as color and opacity. They are commonly defined as 1D or 2D functions that map simple features to these optical properties. As the process of designing a transfer function is typically tedious and unintuitive, several approaches have been proposed for their interactive specification. In this paper, we present a novel method to define transfer functions for volume rendering by leveraging the feature extraction capabilities of self-supervised pre-trained vision transformers. To design a transfer function, users simply select the structures of interest in a slice viewer, and our method automatically selects similar structures based on the high-level features extracted by the neural network. Contrary to previous learning-based transfer function approaches, our method does not require training of models and allows for quick inference, enabling an interactive exploration of the volume data. Our approach reduces the amount of necessary annotations by interactively informing the user about the current classification, so they can focus on annotating the structures of interest that still require annotation. In practice, this allows users to design transfer functions within seconds, instead of minutes. We compare our method to existing learning-based approaches in terms of annotation and compute time, as well as with respect to segmentation accuracy. Our accompanying video showcases the interactivity and effectiveness of our method.
Monocular Depth Estimation for Semi-Transparent Volume Renderings
Jun 27, 2022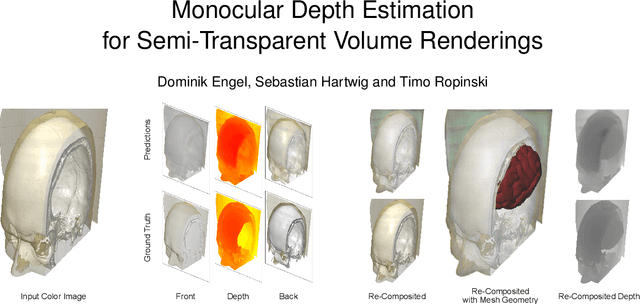
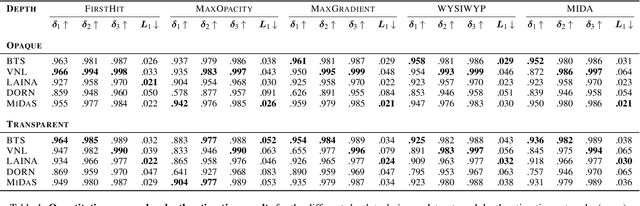
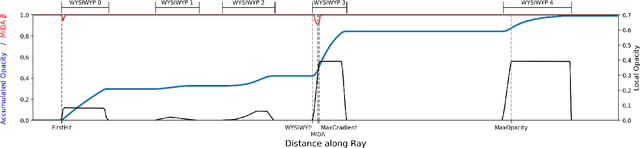
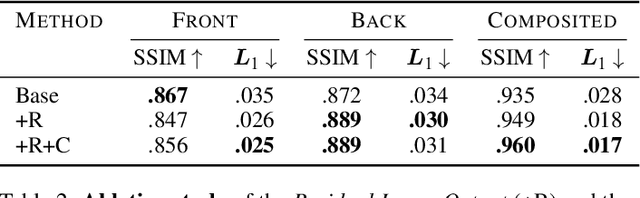
Neural networks have shown great success in extracting geometric information from color images. Especially, monocular depth estimation networks are increasingly reliable in real-world scenes. In this work we investigate the applicability of such monocular depth estimation networks to semi-transparent volume rendered images. As depth is notoriously difficult to define in a volumetric scene without clearly defined surfaces, we consider different depth computations that have emerged in practice, and compare state-of-the-art monocular depth estimation approaches for these different interpretations during an evaluation considering different degrees of opacity in the renderings. Additionally, we investigate how these networks can be extended to further obtain color and opacity information, in order to create a layered representation of the scene based on a single color image. This layered representation consists of spatially separated semi-transparent intervals that composite to the original input rendering. In our experiments we show that adaptions of existing approaches to monocular depth estimation perform well on semi-transparent volume renderings, which has several applications in the area of scientific visualization.
Differentiable Electron Microscopy Simulation: Methods and Applications for Visualization
May 08, 2022
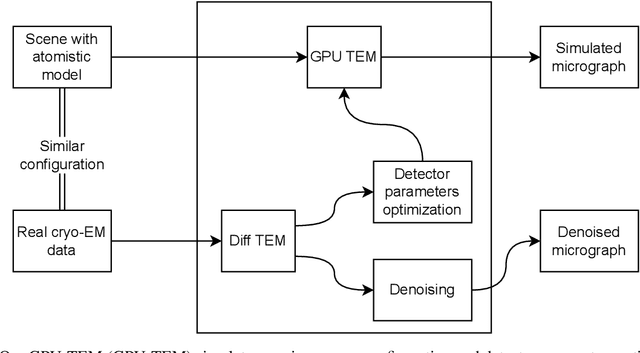
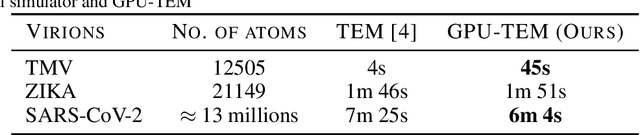
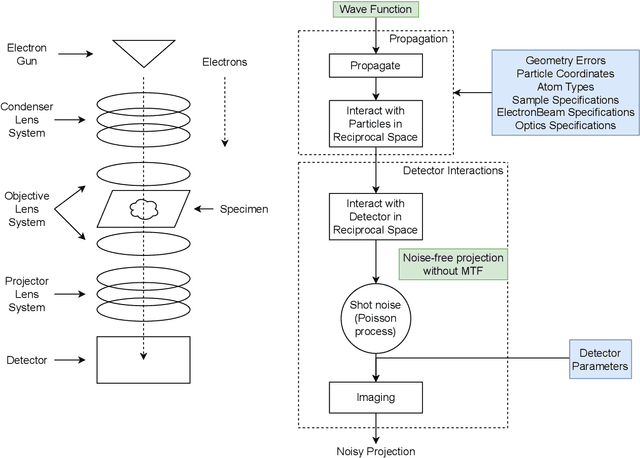
We propose a new microscopy simulation system that can depict atomistic models in a micrograph visual style, similar to results of physical electron microscopy imaging. This system is scalable, able to represent simulation of electron microscopy of tens of viral particles and synthesizes the image faster than previous methods. On top of that, the simulator is differentiable, both its deterministic as well as stochastic stages that form signal and noise representations in the micrograph. This notable property has the capability for solving inverse problems by means of optimization and thus allows for generation of microscopy simulations using the parameter settings estimated from real data. We demonstrate this learning capability through two applications: (1) estimating the parameters of the modulation transfer function defining the detector properties of the simulated and real micrographs, and (2) denoising the real data based on parameters trained from the simulated examples. While current simulators do not support any parameter estimation due to their forward design, we show that the results obtained using estimated parameters are very similar to the results of real micrographs. Additionally, we evaluate the denoising capabilities of our approach and show that the results showed an improvement over state-of-the-art methods. Denoised micrographs exhibit less noise in the tilt-series tomography reconstructions, ultimately reducing the visual dominance of noise in direct volume rendering of microscopy tomograms.