 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquisition of high-quality images for camera calibration in robotics applications via speech prompts
Apr 15, 2025


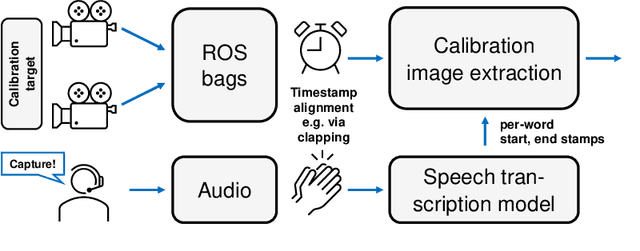
Accurate intrinsic and extrinsic camera calibration can be an important prerequisite for robotic applications that rely on vision as input. While there is ongoing research on enabling camera calibration using natural images, many systems in practice still rely on using designated calibration targets with e.g. checkerboard patterns or April tag grids. Once calibration images from different perspectives have been acquired and feature descriptors detected, those are typically used in an optimization process to minimize the geometric reprojection error. For this optimization to converge, input images need to be of sufficient quality and particularly sharpness; they should neither contain motion blur nor rolling-shutter artifacts that can arise when the calibration board was not static during image capture. In this work, we present a novel calibration image acquisition technique controlled via voice commands recorded with a clip-on microphone, that can be more robust and user-friendly than e.g. triggering capture with a remote control, or filtering out blurry frames from a video sequence in postprocessing. To achieve this, we use a state-of-the-art speech-to-text transcription model with accurate per-word timestamping to capture trigger words with precise temporal alignment. Our experiments show that the proposed method improves user experience by being fast and efficient, allowing us to successfully calibrate complex multi-camera setups.
Cycle-Correspondence Loss: Learning Dense View-Invariant Visual Features from Unlabeled and Unordered RGB Images
Jun 18, 2024



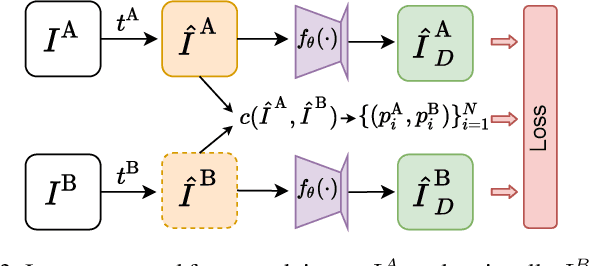
Robot manipulation relying on learned object-centric descriptors became popular in recent years. Visual descriptors can easily describe manipulation task objectives, they can be learned efficiently using self-supervision, and they can encode actuated and even non-rigid objects. However, learning robust, view-invariant keypoints in a self-supervised approach requires a meticulous data collection approach involving precise calibration and expert supervision. In this paper we introduce Cycle-Correspondence Loss (CCL) for view-invariant dense descriptor learning, which adopts the concept of cycle-consistency, enabling a simple data collection pipeline and training on unpaired RGB camera views. The key idea is to autonomously detect valid pixel correspondences by attempting to use a prediction over a new image to predict the original pixel in the original image, while scaling error terms based on the estimated confidence. Our evaluation shows that we outperform other self-supervised RGB-only methods, and approach performance of supervised methods, both with respect to keypoint tracking as well as for a robot grasping downstream task.
Learning Dense Visual Descriptors using Image Augmentations for Robot Manipulation Tasks
Sep 12, 2022

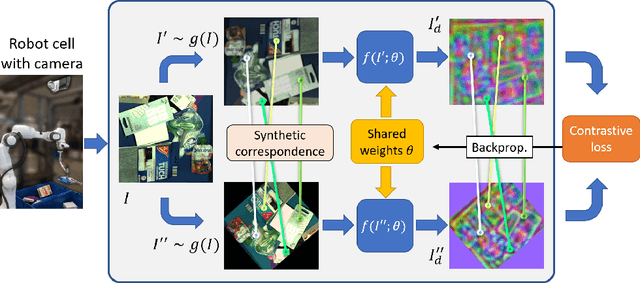

We propose a self-supervised training approach for learning view-invariant dense visual descriptors using image augmentations. Unlike existing works, which often require complex datasets, such as registered RGBD sequences, we train on an unordered set of RGB images. This allows for learning from a single camera view, e.g., in an existing robotic cell with a fix-mounted camera. We create synthetic views and dense pixel correspondences using data augmentations. We find our descriptors are competitive to the existing methods, despite the simpler data recording and setup requirements. We show that training on synthetic correspondences provides descriptor consistency across a broad range of camera views. We compare against training with geometric correspondence from multiple views and provide ablation studies. We also show a robotic bin-picking experiment using descriptors learned from a fix-mounted camera for defining grasp preferences.
Efficient and Robust Training of Dense Object Nets for Multi-Object Robot Manipulation
Jun 24, 2022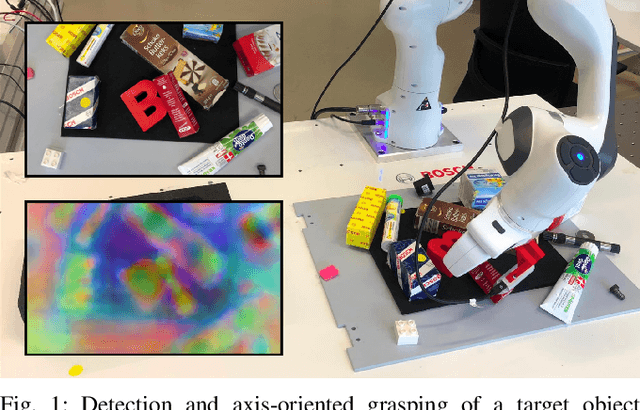

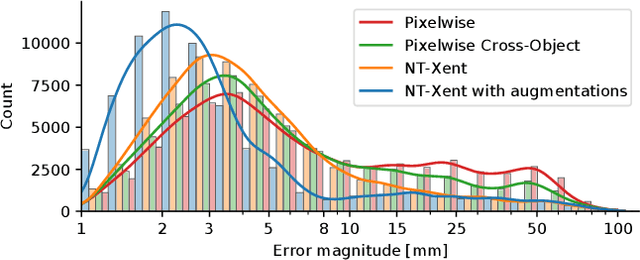
We propose a framework for robust and efficient training of Dense Object Nets (DON) with a focus on multi-object robot manipulation scenarios. DON is a popular approach to obtain dense, view-invariant object descriptors, which can be used for a multitude of downstream tasks in robot manipulation, such as, pose estimation, state representation for control, etc.. However, the original work focused training on singulated objects, with limited results on instance-specific, multi-object applications. Additionally, a complex data collection pipeline, including 3D reconstruction and mask annotation of each object, is required for training. In this paper, we further improve the efficacy of DON with a simplified data collection and training regime, that consistently yields higher precision and enables robust tracking of keypoints with less data requirements. In particular, we focus on training with multi-object data instead of singulated objects, combined with a well-chosen augmentation scheme. We additionally propose an alternative loss formulation to the original pixelwise formulation that offers better results and is less sensitive to hyperparameters. Finally, we demonstrate the robustness and accuracy of our proposed framework on a real-world robotic grasping task.