 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
NSL-MT: Linguistically Informed Negative Samples for Efficient Machine Translation in Low-Resource Languages
Nov 12, 2025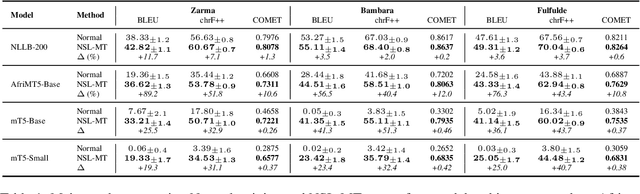
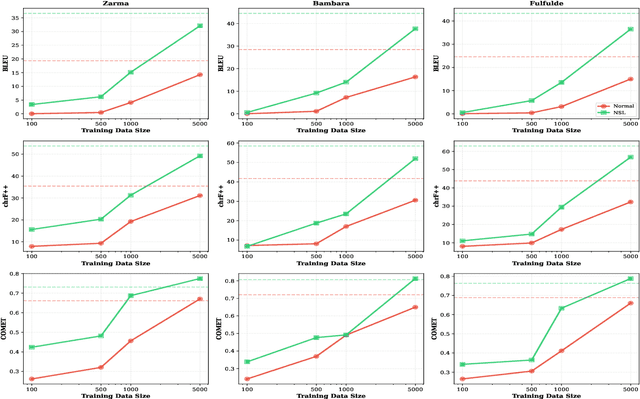

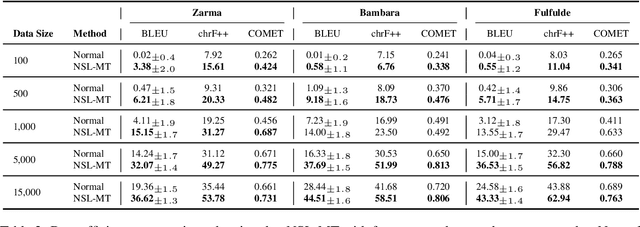
We introduce Negative Space Learning MT (NSL-MT), a training method that teaches models what not to generate by encoding linguistic constraints as severity-weighted penalties in the loss function. NSL-MT increases limited parallel data with synthetically generated violations of target language grammar, explicitly penalizing the model when it assigns high probability to these linguistically invalid outputs. We demonstrate that NSL-MT delivers improvements across all architectures: 3-12\% BLEU gains for well-performing models and 56-89\% gains for models lacking descent initial support. Furthermore, NSL-MT provides a 5x data efficiency multiplier -- training with 1,000 examples matches or exceeds normal training with 5,000 examples. Thus, NSL-MT provides a data-efficient alternative training method for settings where there is limited annotated parallel corporas.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
Geometry-aware RL for Manipulation of Varying Shapes and Deformable Objects
Feb 12, 2025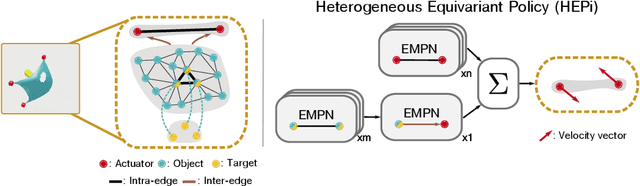

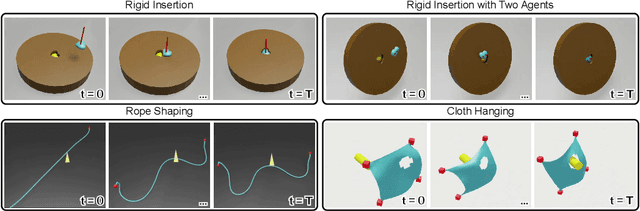
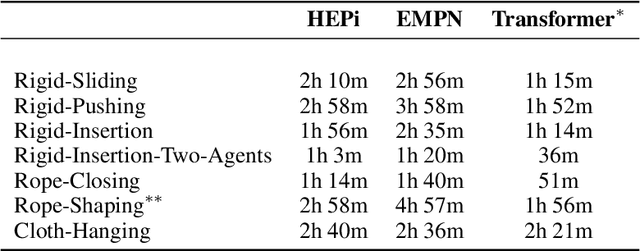
Manipulating objects with varying geometries and deformable objects is a major challenge in robotics. Tasks such as insertion with different objects or cloth hanging require precise control and effective modelling of complex dynamics. In this work, we frame this problem through the lens of a heterogeneous graph that comprises smaller sub-graphs, such as actuators and objects, accompanied by different edge types describing their interactions. This graph representation serves as a unified structure for both rigid and deformable objects tasks, and can be extended further to tasks comprising multiple actuators. To evaluate this setup, we present a novel and challenging reinforcement learning benchmark, including rigid insertion of diverse objects, as well as rope and cloth manipulation with multiple end-effectors. These tasks present a large search space, as both the initial and target configurations are uniformly sampled in 3D space. To address this issue, we propose a novel graph-based policy model, dubbed Heterogeneous Equivariant Policy (HEPi), utilizing $SE(3)$ equivariant message passing networks as the main backbone to exploit the geometric symmetry. In addition, by modeling explicit heterogeneity, HEPi can outperform Transformer-based and non-heterogeneous equivariant policies in terms of average returns, sample efficiency, and generalization to unseen objects.
RAPID: Retrieval-Augmented Parallel Inference Drafting for Text-Based Video Event Retrieval
Jan 27, 2025



Retrieving events from videos using text queries has become increasingly challenging due to the rapid growth of multimedia content. Existing methods for text-based video event retrieval often focus heavily on object-level descriptions, overlooking the crucial role of contextual information. This limitation is especially apparent when queries lack sufficient context, such as missing location details or ambiguous background elements. To address these challenges, we propose a novel system called RAPID (Retrieval-Augmented Parallel Inference Drafting), which leverages advancements in Large Language Models (LLMs) and prompt-based learning to semantically correct and enrich user queries with relevant contextual information. These enriched queries are then processed through parallel retrieval, followed by an evaluation step to select the most relevant results based on their alignment with the original query. Through extensive experiments on our custom-developed dataset, we demonstrate that RAPID significantly outperforms traditional retrieval methods, particularly for contextually incomplete queries. Our system was validated for both speed and accuracy through participation in the Ho Chi Minh City AI Challenge 2024, where it successfully retrieved events from over 300 hours of video. Further evaluation comparing RAPID with the baseline proposed by the competition organizers demonstrated its superior effectiveness, highlighting the strength and robustness of our approach.
Enhancing Exploration with Diffusion Policies in Hybrid Off-Policy RL: Application to Non-Prehensile Manipulation
Nov 22, 2024



Learning diverse policies for non-prehensile manipulation is essential for improving skill transfer and generalization to out-of-distribution scenarios. In this work, we enhance exploration through a two-fold approach within a hybrid framework that tackles both discrete and continuous action spaces. First, we model the continuous motion parameter policy as a diffusion model, and second, we incorporate this into a maximum entropy reinforcement learning framework that unifies both the discrete and continuous components. The discrete action space, such as contact point selection, is optimized through Q-value function maximization, while the continuous part is guided by a diffusion-based policy. This hybrid approach leads to a principled objective, where the maximum entropy term is derived as a lower bound using structured variational inference. We propose the Hybrid Diffusion Policy algorithm (HyDo) and evaluate its performance on both simulation and zero-shot sim2real tasks. Our results show that HyDo encourages more diverse behavior policies, leading to significantly improved success rates across tasks - for example, increasing from 53% to 72% on a real-world 6D pose alignment task. Project page: https://leh2rng.github.io/hydo
Pseudo-Labeling and Contextual Curriculum Learning for Online Grasp Learning in Robotic Bin Picking
Mar 04, 2024



The prevailing grasp prediction methods predominantly rely on offline learning, overlooking the dynamic grasp learning that occurs during real-time adaptation to novel picking scenarios. These scenarios may involve previously unseen objects, variations in camera perspectives, and bin configurations, among other factors. In this paper, we introduce a novel approach, SSL-ConvSAC, that combines semi-supervised learning and reinforcement learning for online grasp learning. By treating pixels with reward feedback as labeled data and others as unlabeled, it efficiently exploits unlabeled data to enhance learning. In addition, we address the imbalance between labeled and unlabeled data by proposing a contextual curriculum-based method. We ablate the proposed approach on real-world evaluation data and demonstrate promise for improving online grasp learning on bin picking tasks using a physical 7-DoF Franka Emika robot arm with a suction gripper. Video: https://youtu.be/OAro5pg8I9U
WAVER: Writing-style Agnostic Video Retrieval via Distilling Vision-Language Models Through Open-Vocabulary Knowledge
Dec 27, 2023Text-video retrieval, a prominent sub-field within the domain of multimodal information retrieval, has witnessed remarkable growth in recent years. However, existing methods assume video scenes are consistent with unbiased descriptions. These limitations fail to align with real-world scenarios since descriptions can be influenced by annotator biases, diverse writing styles, and varying textual perspectives. To overcome the aforementioned problems, we introduce WAVER, a cross-domain knowledge distillation framework via vision-language models through open-vocabulary knowledge designed to tackle the challenge of handling different writing styles in video descriptions. WAVER capitalizes on the open-vocabulary properties that lie in pre-trained vision-language models and employs an implicit knowledge distillation approach to transfer text-based knowledge from a teacher model to a vision-based student. Empirical studies conducted across four standard benchmark datasets, encompassing various settings, provide compelling evidence that WAVER can achieve state-of-the-art performance in text-video retrieval task while handling writing-style variations.
Towards Autoencoding Variational Inference for Aspect-based Opinion Summary
Feb 16, 2019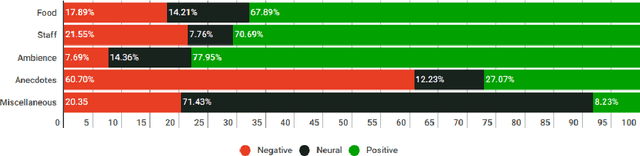
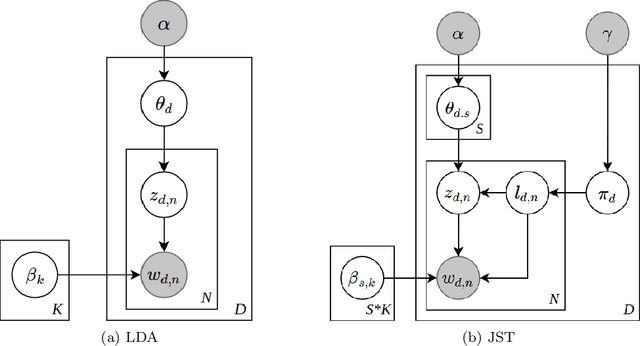
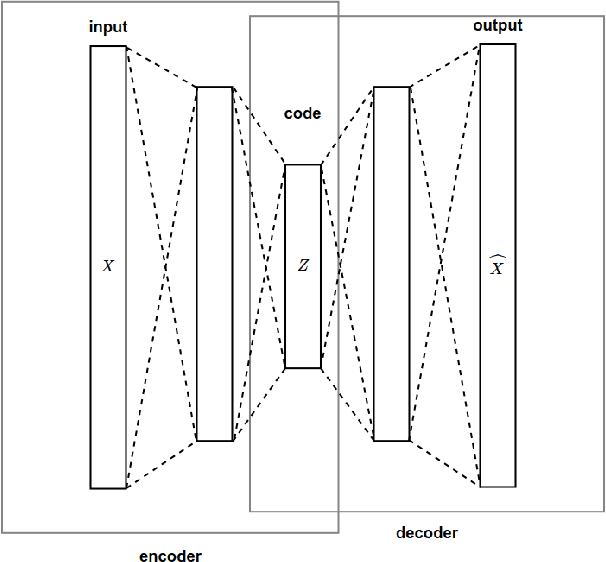

Aspect-based Opinion Summary (AOS), consisting of aspect discovery and sentiment classification steps, has recently been emerging as one of the most crucial data mining tasks in e-commerce systems. Along this direction, the LDA-based model is considered as a notably suitable approach, since this model offers both topic modeling and sentiment classification. However, unlike traditional topic modeling, in the context of aspect discovery it is often required some initial seed words, whose prior knowledge is not easy to be incorporated into LDA models. Moreover, LDA approaches rely on sampling methods, which need to load the whole corpus into memory, making them hardly scalable. In this research, we study an alternative approach for AOS problem, based on Autoencoding Variational Inference (AVI). Firstly, we introduce the Autoencoding Variational Inference for Aspect Discovery (AVIAD) model, which extends the previous work of Autoencoding Variational Inference for Topic Models (AVITM) to embed prior knowledge of seed words. This work includes enhancement of the previous AVI architecture and also modification of the loss function. Ultimately, we present the Autoencoding Variational Inference for Joint Sentiment/Topic (AVIJST) model. In this model, we substantially extend the AVI model to support the JST model, which performs topic modeling for corresponding sentiment. The experimental results show that our proposed models enjoy higher topic coherent, faster convergence time and better accuracy on sentiment classification, as compared to their LDA-based counterparts.