Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Wikipedian: Generating Textual Summaries from Knowledge Base Triples
Nov 01, 2017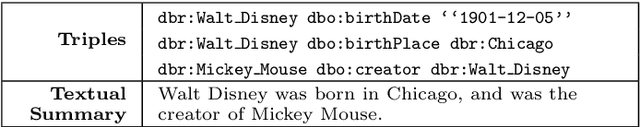
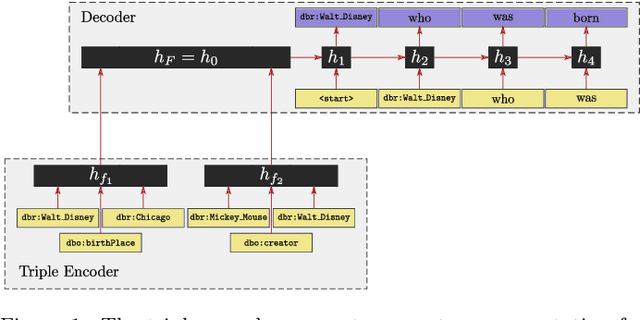
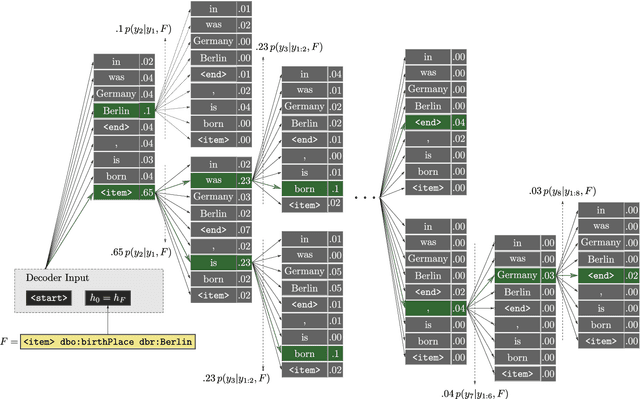

Most people do not interact with Semantic Web data directly. Unless they have the expertise to understand the underlying technology, they need textual or visual interfaces to help them make sense of it. We explore the problem of generating natural language summaries for Semantic Web data. This is non-trivial, especially in an open-domain context. To address this problem, we explore the use of neural networks. Our system encodes the information from a set of triples into a vector of fixed dimensionality and generates a textual summary by conditioning the output on the encoded vector. We train and evaluate our models on two corpora of loosely aligned Wikipedia snippets and DBpedia and Wikidata triples with promising results.
Via