 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Text Classification via Transferable Representations
Mar 10, 2025Group fairness is a central research topic in text classification, where reaching fair treatment between sensitive groups (e.g., women and men) remains an open challenge. We propose an approach that extends the use of the Wasserstein Dependency Measure for learning unbiased neural text classifiers. Given the challenge of distinguishing fair from unfair information in a text encoder, we draw inspiration from adversarial training by inducing independence between representations learned for the target label and those for a sensitive attribute. We further show that Domain Adaptation can be efficiently leveraged to remove the need for access to the sensitive attributes in the dataset we cure. We provide both theoretical and empirical evidence that our approach is well-founded.
Histoires Morales: A French Dataset for Assessing Moral Alignment
Jan 28, 2025Aligning language models with human values is crucial, especially as they become more integrated into everyday life. While models are often adapted to user preferences, it is equally important to ensure they align with moral norms and behaviours in real-world social situations. Despite significant progress in languages like English and Chinese, French has seen little attention in this area, leaving a gap in understanding how LLMs handle moral reasoning in this language. To address this gap, we introduce Histoires Morales, a French dataset derived from Moral Stories, created through translation and subsequently refined with the assistance of native speakers to guarantee grammatical accuracy and adaptation to the French cultural context. We also rely on annotations of the moral values within the dataset to ensure their alignment with French norms. Histoires Morales covers a wide range of social situations, including differences in tipping practices, expressions of honesty in relationships, and responsibilities toward animals. To foster future research, we also conduct preliminary experiments on the alignment of multilingual models on French and English data and the robustness of the alignment. We find that while LLMs are generally aligned with human moral norms by default, they can be easily influenced with user-preference optimization for both moral and immoral data.
Fine-tuning Strategies for Domain Specific Question Answering under Low Annotation Budget Constraints
Jan 17, 2024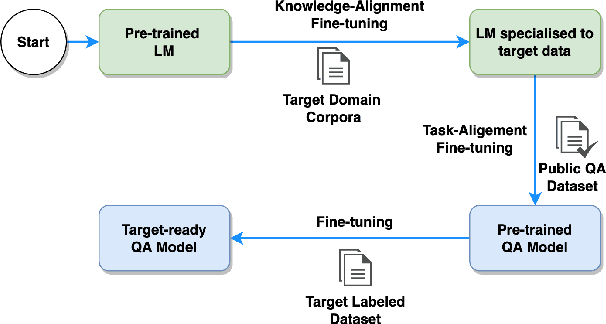

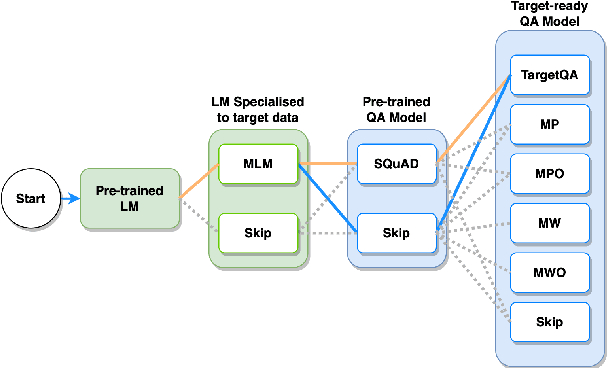
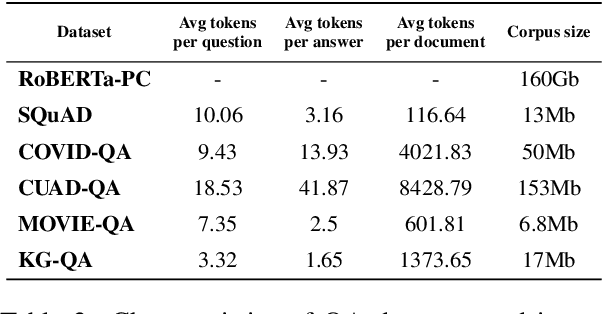
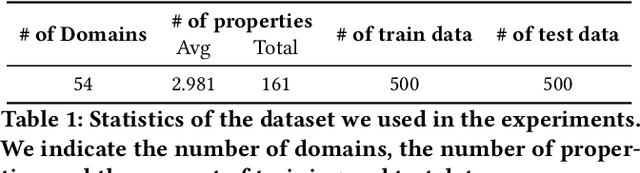
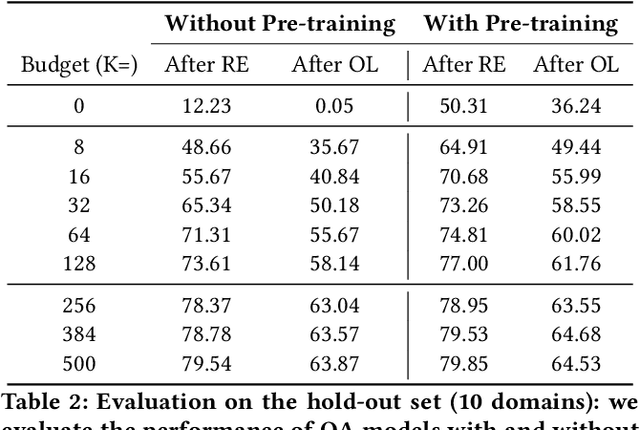
The progress introduced by pre-trained language models and their fine-tuning has resulted in significant improvements in most downstream NLP tasks. The unsupervised training of a language model combined with further target task fine-tuning has become the standard QA fine-tuning procedure. In this work, we demonstrate that this strategy is sub-optimal for fine-tuning QA models, especially under a low QA annotation budget, which is a usual setting in practice due to the extractive QA labeling cost. We draw our conclusions by conducting an exhaustive analysis of the performance of the alternatives of the sequential fine-tuning strategy on different QA datasets. Based on the experiments performed, we observed that the best strategy to fine-tune the QA model in low-budget settings is taking a pre-trained language model (PLM) and then fine-tuning PLM with a dataset composed of the target dataset and SQuAD dataset. With zero extra annotation effort, the best strategy outperforms the standard strategy by 2.28% to 6.48%. Our experiments provide one of the first investigations on how to best fine-tune a QA system under a low budget and are therefore of the utmost practical interest to the QA practitioners.
QAnswer: Towards Question Answering Search over Websites
Jan 17, 2024Question Answering (QA) is increasingly used by search engines to provide results to their end-users, yet very few websites currently use QA technologies for their search functionality. To illustrate the potential of QA technologies for the website search practitioner, we demonstrate web searches that combine QA over knowledge graphs and QA over free text -- each being usually tackled separately. We also discuss the different benefits and drawbacks of both approaches for web site searches. We use the case studies made of websites hosted by the Wikimedia Foundation (namely Wikipedia and Wikidata). Differently from a search engine (e.g. Google, Bing, etc), the data are indexed integrally, i.e. we do not index only a subset, and they are indexed exclusively, i.e. we index only data available on the corresponding website.
Wikidata as a seed for Web Extraction
Jan 15, 2024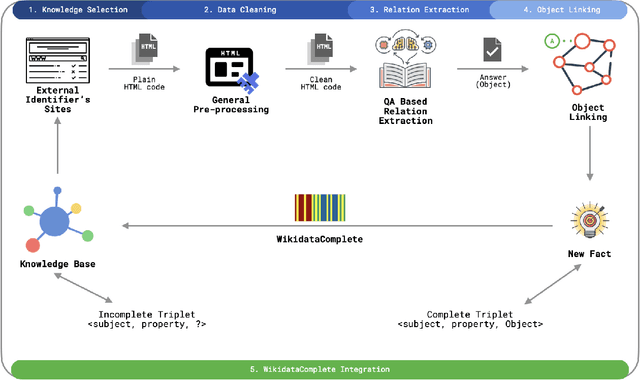

Wikidata has grown to a knowledge graph with an impressive size. To date, it contains more than 17 billion triples collecting information about people, places, films, stars, publications, proteins, and many more. On the other side, most of the information on the Web is not published in highly structured data repositories like Wikidata, but rather as unstructured and semi-structured content, more concretely in HTML pages containing text and tables. Finding, monitoring, and organizing this data in a knowledge graph is requiring considerable work from human editors. The volume and complexity of the data make this task difficult and time-consuming. In this work, we present a framework that is able to identify and extract new facts that are published under multiple Web domains so that they can be proposed for validation by Wikidata editors. The framework is relying on question-answering technologies. We take inspiration from ideas that are used to extract facts from textual collections and adapt them to extract facts from Web pages. For achieving this, we demonstrate that language models can be adapted to extract facts not only from textual collections but also from Web pages. By exploiting the information already contained in Wikidata the proposed framework can be trained without the need for any additional learning signals and can extract new facts for a wide range of properties and domains. Following this path, Wikidata can be used as a seed to extract facts on the Web. Our experiments show that we can achieve a mean performance of 84.07 at F1-score. Moreover, our estimations show that we can potentially extract millions of facts that can be proposed for human validation. The goal is to help editors in their daily tasks and contribute to the completion of the Wikidata knowledge graph.
An investigation of structures responsible for gender bias in BERT and DistilBERT
Jan 12, 2024In recent years, large Transformer-based Pre-trained Language Models (PLM) have changed the Natural Language Processing (NLP) landscape, by pushing the performance boundaries of the state-of-the-art on a wide variety of tasks. However, this performance gain goes along with an increase in complexity, and as a result, the size of such models (up to billions of parameters) represents a constraint for their deployment on embedded devices or short-inference time tasks. To cope with this situation, compressed models emerged (e.g. DistilBERT), democratizing their usage in a growing number of applications that impact our daily lives. A crucial issue is the fairness of the predictions made by both PLMs and their distilled counterparts. In this paper, we propose an empirical exploration of this problem by formalizing two questions: (1) Can we identify the neural mechanism(s) responsible for gender bias in BERT (and by extension DistilBERT)? (2) Does distillation tend to accentuate or mitigate gender bias (e.g. is DistilBERT more prone to gender bias than its uncompressed version, BERT)? Our findings are the following: (I) one cannot identify a specific layer that produces bias; (II) every attention head uniformly encodes bias; except in the context of underrepresented classes with a high imbalance of the sensitive attribute; (III) this subset of heads is different as we re-fine tune the network; (IV) bias is more homogeneously produced by the heads in the distilled model.
Fair Text Classification with Wasserstein Independence
Nov 21, 2023Group fairness is a central research topic in text classification, where reaching fair treatment between sensitive groups (e.g. women vs. men) remains an open challenge. This paper presents a novel method for mitigating biases in neural text classification, agnostic to the model architecture. Considering the difficulty to distinguish fair from unfair information in a text encoder, we take inspiration from adversarial training to induce Wasserstein independence between representations learned to predict our target label and the ones learned to predict some sensitive attribute. Our approach provides two significant advantages. Firstly, it does not require annotations of sensitive attributes in both testing and training data. This is more suitable for real-life scenarios compared to existing methods that require annotations of sensitive attributes at train time. Second, our approach exhibits a comparable or better fairness-accuracy trade-off compared to existing methods.
ProtAugment: Unsupervised diverse short-texts paraphrasing for intent detection meta-learning
May 27, 2021Recent research considers few-shot intent detection as a meta-learning problem: the model is learning to learn from a consecutive set of small tasks named episodes. In this work, we propose ProtAugment, a meta-learning algorithm for short texts classification (the intent detection task). ProtAugment is a novel extension of Prototypical Networks, that limits overfitting on the bias introduced by the few-shots classification objective at each episode. It relies on diverse paraphrasing: a conditional language model is first fine-tuned for paraphrasing, and diversity is later introduced at the decoding stage at each meta-learning episode. The diverse paraphrasing is unsupervised as it is applied to unlabelled data, and then fueled to the Prototypical Network training objective as a consistency loss. ProtAugment is the state-of-the-art method for intent detection meta-learning, at no extra labeling efforts and without the need to fine-tune a conditional language model on a given application domain.
A Neural Few-Shot Text Classification Reality Check
Jan 28, 2021Modern classification models tend to struggle when the amount of annotated data is scarce. To overcome this issue, several neural few-shot classification models have emerged, yielding significant progress over time, both in Computer Vision and Natural Language Processing. In the latter, such models used to rely on fixed word embeddings before the advent of transformers. Additionally, some models used in Computer Vision are yet to be tested in NLP applications. In this paper, we compare all these models, first adapting those made in the field of image processing to NLP, and second providing them access to transformers. We then test these models equipped with the same transformer-based encoder on the intent detection task, known for having a large number of classes. Our results reveal that while methods perform almost equally on the ARSC dataset, this is not the case for the Intent Detection task, where the most recent and supposedly best competitors perform worse than older and simpler ones (while all are given access to transformers). We also show that a simple baseline is surprisingly strong. All the new developed models, as well as the evaluation framework, are made publicly available.
Near-lossless Binarization of Word Embeddings
May 28, 2018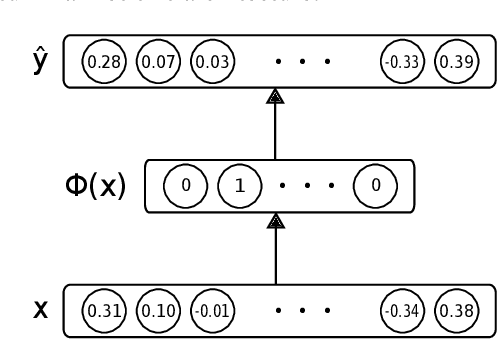
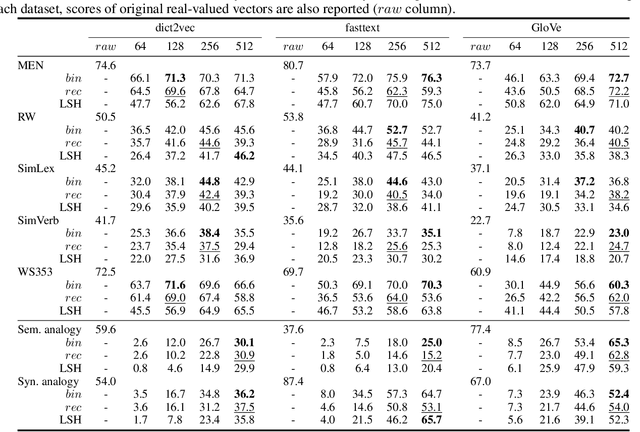
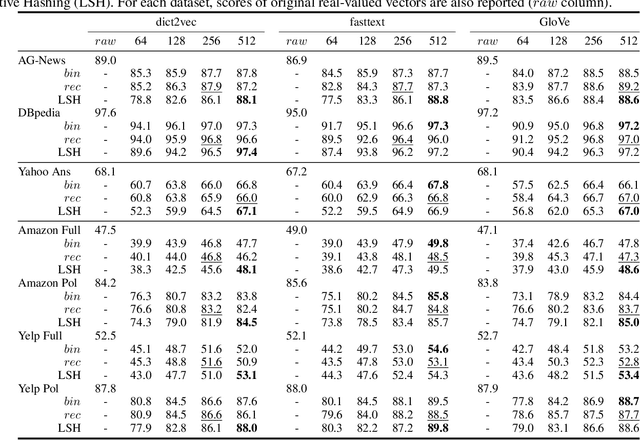
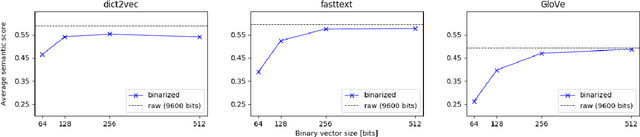
Word embeddings are commonly used as a starting point in many NLP models to achieve state-of-the-art performances. However, with a large vocabulary and many dimensions, these floating-point representations are expensive both in terms of memory and calculation, which makes them unsuitable for use on low-resource devices. The method proposed in this paper transforms real-valued embeddings into binary embeddings while preserving semantic information, requiring only 128 or 256 bits for each vector. This leads to a small memory footprint and fast vector operations. The model is based on an autoencoder architecture, which also allows to reconstruct original vectors from the binary ones. Experimental results on semantic similarity and text classification tasks show that the binarization of word embeddings only leads to a loss of ~2% in accuracy while reducing the vector size by a factor of 37.5. Moreover, a top-k benchmark demonstrates that using binary vectors are 30 times faster than using real-valued vectors.