 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Strategies for Domain Specific Question Answering under Low Annotation Budget Constraints
Paper and Code
Jan 17, 2024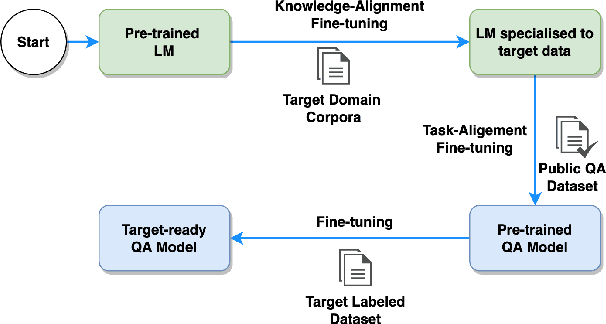

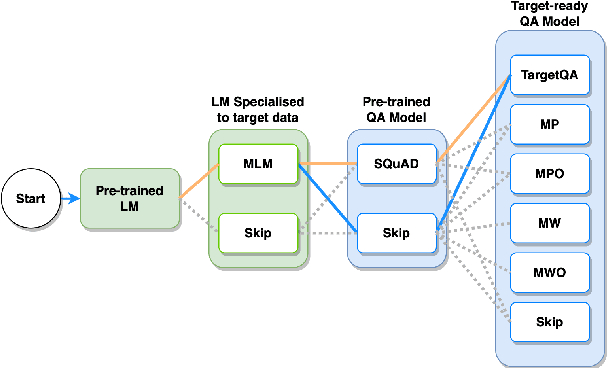
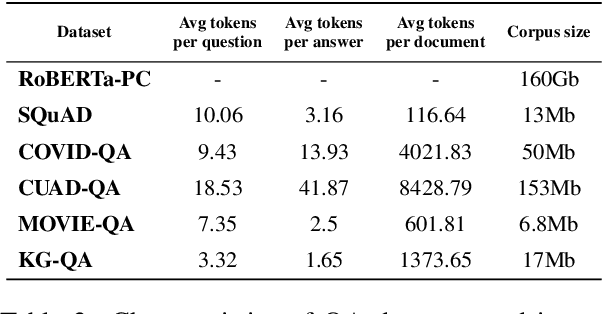
The progress introduced by pre-trained language models and their fine-tuning has resulted in significant improvements in most downstream NLP tasks. The unsupervised training of a language model combined with further target task fine-tuning has become the standard QA fine-tuning procedure. In this work, we demonstrate that this strategy is sub-optimal for fine-tuning QA models, especially under a low QA annotation budget, which is a usual setting in practice due to the extractive QA labeling cost. We draw our conclusions by conducting an exhaustive analysis of the performance of the alternatives of the sequential fine-tuning strategy on different QA datasets. Based on the experiments performed, we observed that the best strategy to fine-tune the QA model in low-budget settings is taking a pre-trained language model (PLM) and then fine-tuning PLM with a dataset composed of the target dataset and SQuAD dataset. With zero extra annotation effort, the best strategy outperforms the standard strategy by 2.28% to 6.48%. Our experiments provide one of the first investigations on how to best fine-tune a QA system under a low budget and are therefore of the utmost practical interest to the QA practitioners.