 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWikidata as a seed for Web Extraction
Paper and Code
Jan 15, 2024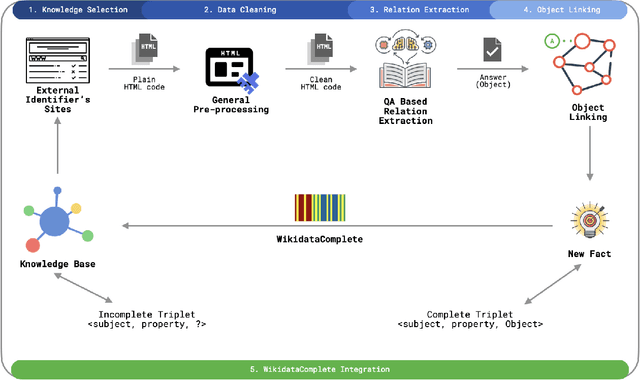
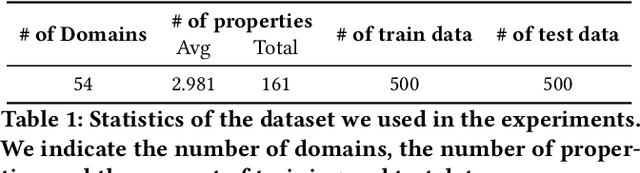

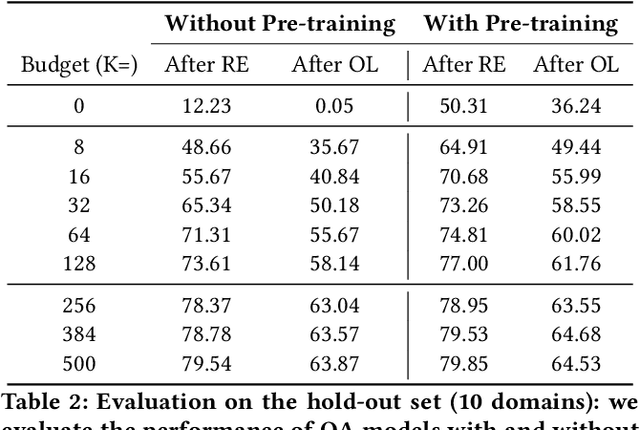
Wikidata has grown to a knowledge graph with an impressive size. To date, it contains more than 17 billion triples collecting information about people, places, films, stars, publications, proteins, and many more. On the other side, most of the information on the Web is not published in highly structured data repositories like Wikidata, but rather as unstructured and semi-structured content, more concretely in HTML pages containing text and tables. Finding, monitoring, and organizing this data in a knowledge graph is requiring considerable work from human editors. The volume and complexity of the data make this task difficult and time-consuming. In this work, we present a framework that is able to identify and extract new facts that are published under multiple Web domains so that they can be proposed for validation by Wikidata editors. The framework is relying on question-answering technologies. We take inspiration from ideas that are used to extract facts from textual collections and adapt them to extract facts from Web pages. For achieving this, we demonstrate that language models can be adapted to extract facts not only from textual collections but also from Web pages. By exploiting the information already contained in Wikidata the proposed framework can be trained without the need for any additional learning signals and can extract new facts for a wide range of properties and domains. Following this path, Wikidata can be used as a seed to extract facts on the Web. Our experiments show that we can achieve a mean performance of 84.07 at F1-score. Moreover, our estimations show that we can potentially extract millions of facts that can be proposed for human validation. The goal is to help editors in their daily tasks and contribute to the completion of the Wikidata knowledge graph.