 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-lossless Binarization of Word Embeddings
May 28, 2018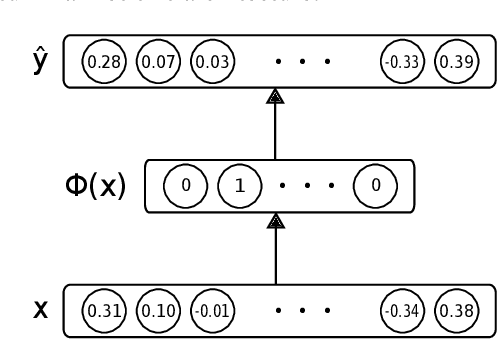
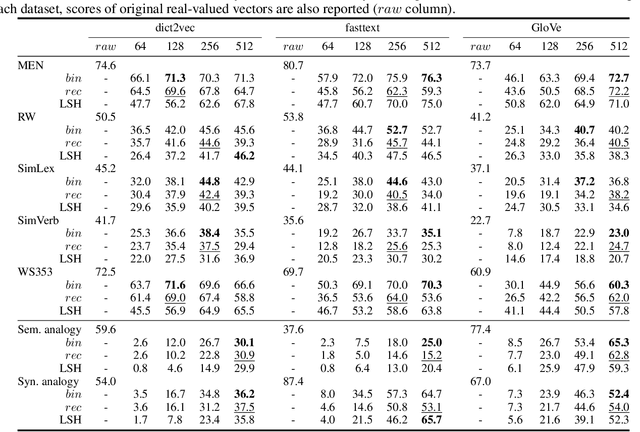
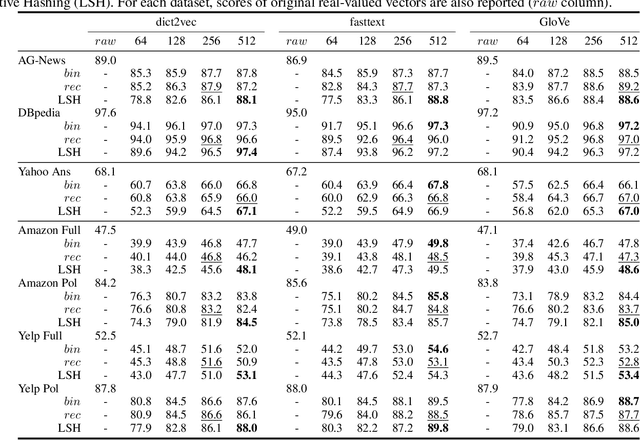
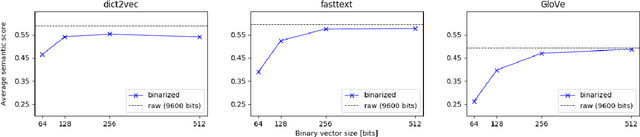
Word embeddings are commonly used as a starting point in many NLP models to achieve state-of-the-art performances. However, with a large vocabulary and many dimensions, these floating-point representations are expensive both in terms of memory and calculation, which makes them unsuitable for use on low-resource devices. The method proposed in this paper transforms real-valued embeddings into binary embeddings while preserving semantic information, requiring only 128 or 256 bits for each vector. This leads to a small memory footprint and fast vector operations. The model is based on an autoencoder architecture, which also allows to reconstruct original vectors from the binary ones. Experimental results on semantic similarity and text classification tasks show that the binarization of word embeddings only leads to a loss of ~2% in accuracy while reducing the vector size by a factor of 37.5. Moreover, a top-k benchmark demonstrates that using binary vectors are 30 times faster than using real-valued vectors.