 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Pairwise Occurrence Information to Improve Knowledge Graph Completion on Large-Scale Datasets
Paper and Code
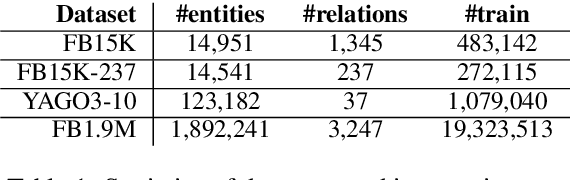
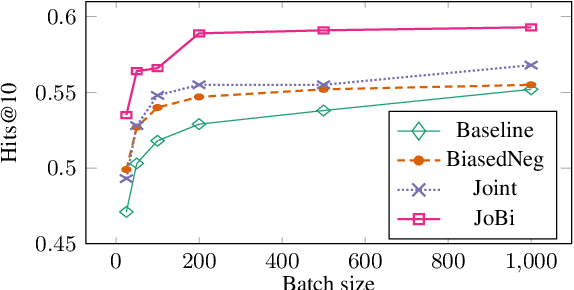
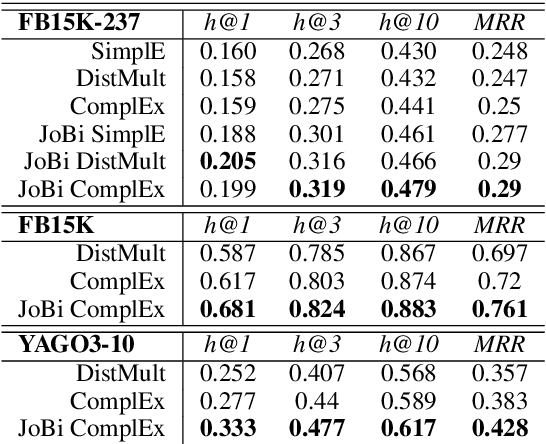
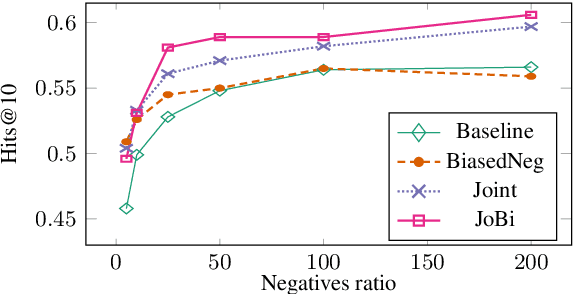
Bilinear models such as DistMult and ComplEx are effective methods for knowledge graph (KG) completion. However, they require large batch sizes, which becomes a performance bottleneck when training on large scale datasets due to memory constraints. In this paper we use occurrences of entity-relation pairs in the dataset to construct a joint learning model and to increase the quality of sampled negatives during training. We show on three standard datasets that when these two techniques are combined, they give a significant improvement in performance, especially when the batch size and the number of generated negative examples are low relative to the size of the dataset. We then apply our techniques to a dataset containing 2 million entities and demonstrate that our model outperforms the baseline by 2.8% absolute on hits@1.