 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis Prompt is Measuring <MASK>: Evaluating Bias Evaluation in Language Models
May 22, 2023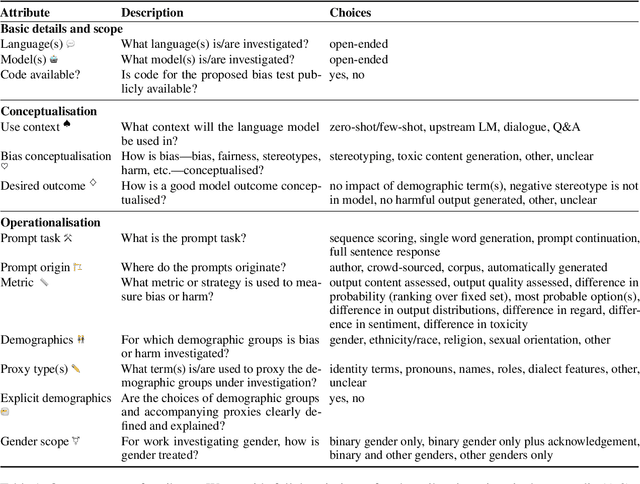
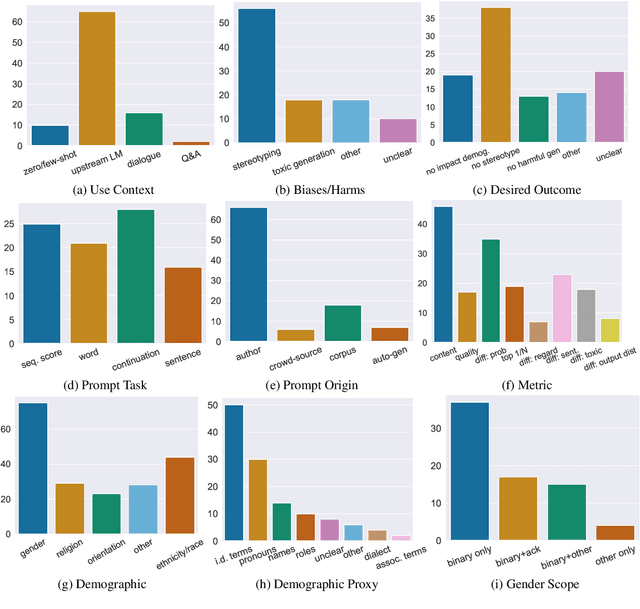
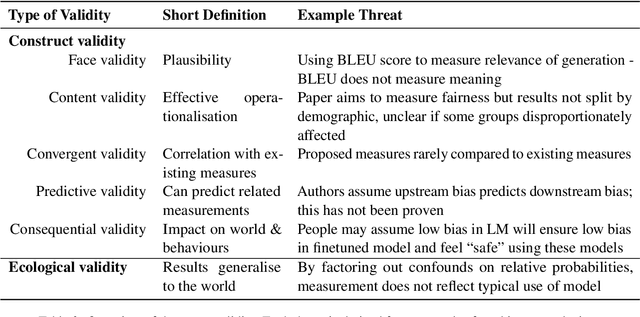
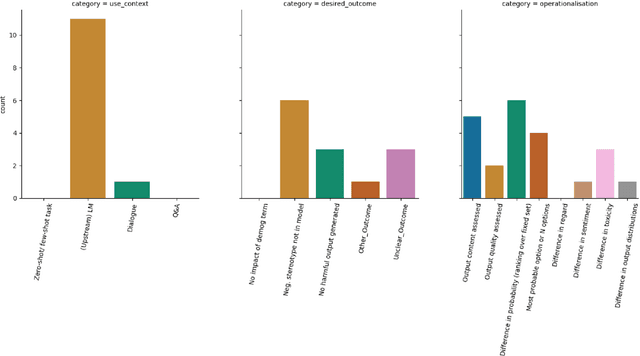
Bias research in NLP seeks to analyse models for social biases, thus helping NLP practitioners uncover, measure, and mitigate social harms. We analyse the body of work that uses prompts and templates to assess bias in language models. We draw on a measurement modelling framework to create a taxonomy of attributes that capture what a bias test aims to measure and how that measurement is carried out. By applying this taxonomy to 90 bias tests, we illustrate qualitatively and quantitatively that core aspects of bias test conceptualisations and operationalisations are frequently unstated or ambiguous, carry implicit assumptions, or be mismatched. Our analysis illuminates the scope of possible bias types the field is able to measure, and reveals types that are as yet under-researched. We offer guidance to enable the community to explore a wider section of the possible bias space, and to better close the gap between desired outcomes and experimental design, both for bias and for evaluating language models more broadly.
Challenges in Applying Explainability Methods to Improve the Fairness of NLP Models
Jun 08, 2022

Motivations for methods in explainable artificial intelligence (XAI) often include detecting, quantifying and mitigating bias, and contributing to making machine learning models fairer. However, exactly how an XAI method can help in combating biases is often left unspecified. In this paper, we briefly review trends in explainability and fairness in NLP research, identify the current practices in which explainability methods are applied to detect and mitigate bias, and investigate the barriers preventing XAI methods from being used more widely in tackling fairness issues.
Does Moral Code Have a Moral Code? Probing Delphi's Moral Philosophy
May 25, 2022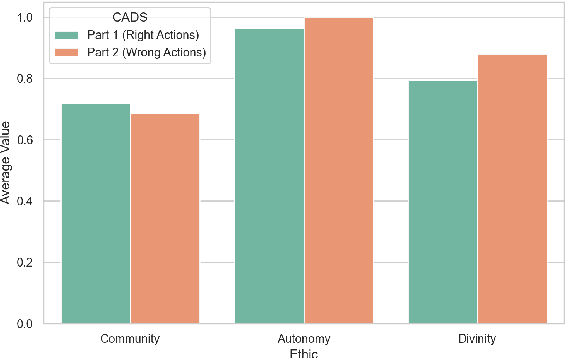
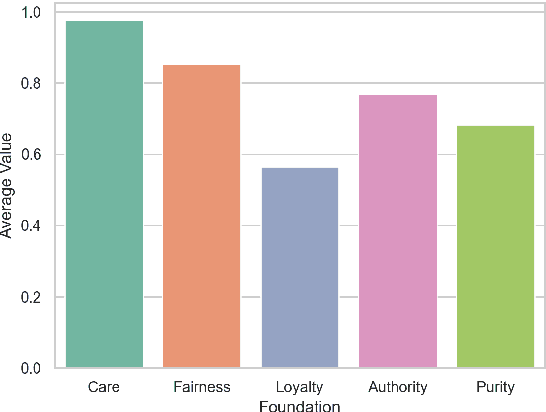
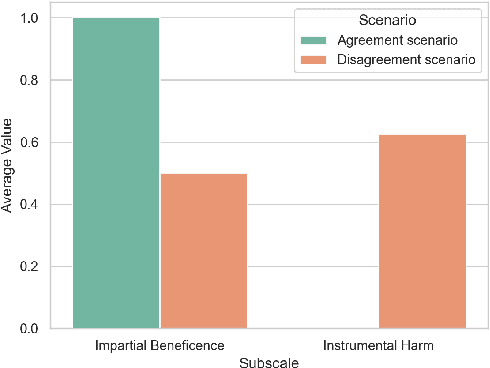

In an effort to guarantee that machine learning model outputs conform with human moral values, recent work has begun exploring the possibility of explicitly training models to learn the difference between right and wrong. This is typically done in a bottom-up fashion, by exposing the model to different scenarios, annotated with human moral judgements. One question, however, is whether the trained models actually learn any consistent, higher-level ethical principles from these datasets -- and if so, what? Here, we probe the Allen AI Delphi model with a set of standardized morality questionnaires, and find that, despite some inconsistencies, Delphi tends to mirror the moral principles associated with the demographic groups involved in the annotation process. We question whether this is desirable and discuss how we might move forward with this knowledge.
Necessity and Sufficiency for Explaining Text Classifiers: A Case Study in Hate Speech Detection
May 06, 2022


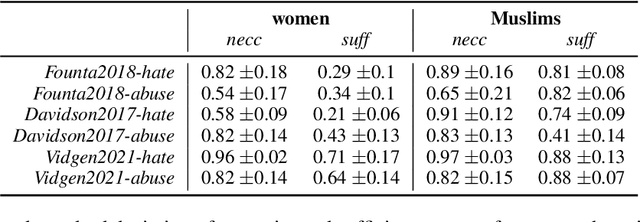
We present a novel feature attribution method for explaining text classifiers, and analyze it in the context of hate speech detection. Although feature attribution models usually provide a single importance score for each token, we instead provide two complementary and theoretically-grounded scores -- necessity and sufficiency -- resulting in more informative explanations. We propose a transparent method that calculates these values by generating explicit perturbations of the input text, allowing the importance scores themselves to be explainable. We employ our method to explain the predictions of different hate speech detection models on the same set of curated examples from a test suite, and show that different values of necessity and sufficiency for identity terms correspond to different kinds of false positive errors, exposing sources of classifier bias against marginalized groups.
Tensors over Semirings for Latent-Variable Weighted Logic Programs
Jun 07, 2020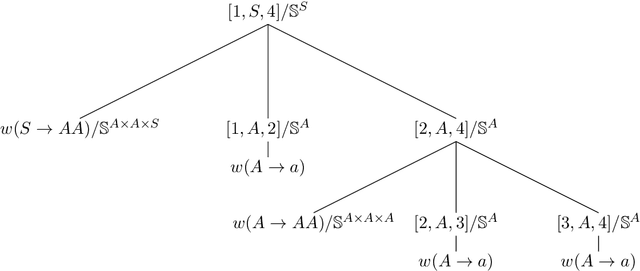
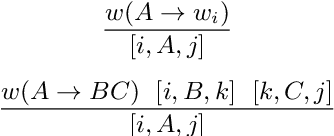
Semiring parsing is an elegant framework for describing parsers by using semiring weighted logic programs. In this paper we present a generalization of this concept: latent-variable semiring parsing. With our framework, any semiring weighted logic program can be latentified by transforming weights from scalar values of a semiring to rank-n arrays, or tensors, of semiring values, allowing the modelling of latent variables within the semiring parsing framework. Semiring is too strong a notion when dealing with tensors, and we have to resort to a weaker structure: a partial semiring. We prove that this generalization preserves all the desired properties of the original semiring framework while strictly increasing its expressiveness.
Using Pairwise Occurrence Information to Improve Knowledge Graph Completion on Large-Scale Datasets
Oct 25, 2019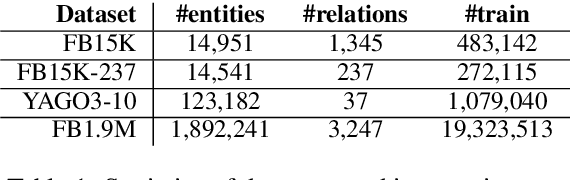
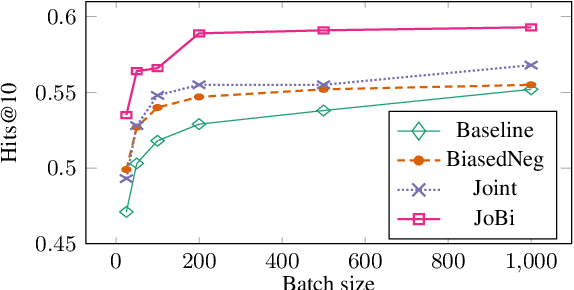
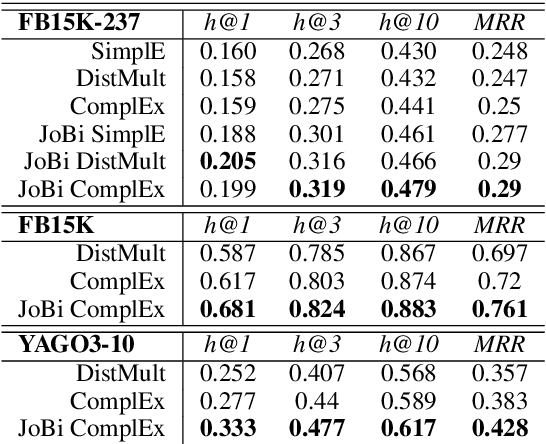
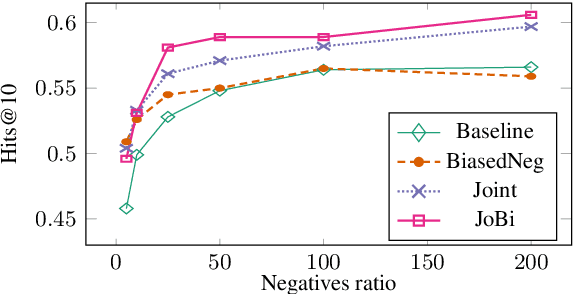
Bilinear models such as DistMult and ComplEx are effective methods for knowledge graph (KG) completion. However, they require large batch sizes, which becomes a performance bottleneck when training on large scale datasets due to memory constraints. In this paper we use occurrences of entity-relation pairs in the dataset to construct a joint learning model and to increase the quality of sampled negatives during training. We show on three standard datasets that when these two techniques are combined, they give a significant improvement in performance, especially when the batch size and the number of generated negative examples are low relative to the size of the dataset. We then apply our techniques to a dataset containing 2 million entities and demonstrate that our model outperforms the baseline by 2.8% absolute on hits@1.
Sentence Entailment in Compositional Distributional Semantics
Oct 09, 2018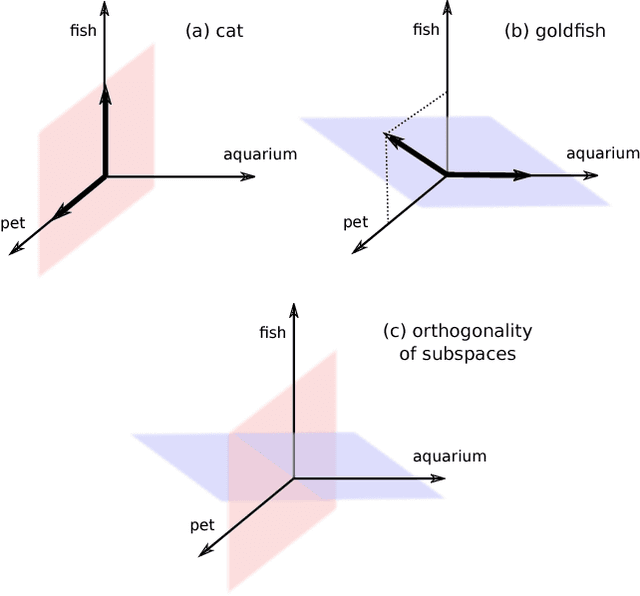
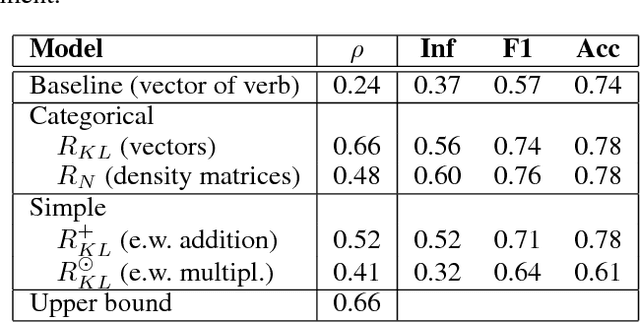

Distributional semantic models provide vector representations for words by gathering co-occurrence frequencies from corpora of text. Compositional distributional models extend these from words to phrases and sentences. In categorical compositional distributional semantics, phrase and sentence representations are functions of their grammatical structure and representations of the words therein. In this setting, grammatical structures are formalised by morphisms of a compact closed category and meanings of words are formalised by objects of the same category. These can be instantiated in the form of vectors or density matrices. This paper concerns the applications of this model to phrase and sentence level entailment. We argue that entropy-based distances of vectors and density matrices provide a good candidate to measure word-level entailment, show the advantage of density matrices over vectors for word level entailments, and prove that these distances extend compositionally from words to phrases and sentences. We exemplify our theoretical constructions on real data and a toy entailment dataset and provide preliminary experimental evidence.
* 8 pages, 1 figure, 2 tables, short version presented in the International Symposium on Artificial Intelligence and Mathematics (ISAIM), 2016
Distributional Sentence Entailment Using Density Matrices
Oct 14, 2015Categorical compositional distributional model of Coecke et al. (2010) suggests a way to combine grammatical composition of the formal, type logical models with the corpus based, empirical word representations of distributional semantics. This paper contributes to the project by expanding the model to also capture entailment relations. This is achieved by extending the representations of words from points in meaning space to density operators, which are probability distributions on the subspaces of the space. A symmetric measure of similarity and an asymmetric measure of entailment is defined, where lexical entailment is measured using von Neumann entropy, the quantum variant of Kullback-Leibler divergence. Lexical entailment, combined with the composition map on word representations, provides a method to obtain entailment relations on the level of sentences. Truth theoretic and corpus-based examples are provided.