 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Moral Code Have a Moral Code? Probing Delphi's Moral Philosophy
Paper and Code
May 25, 2022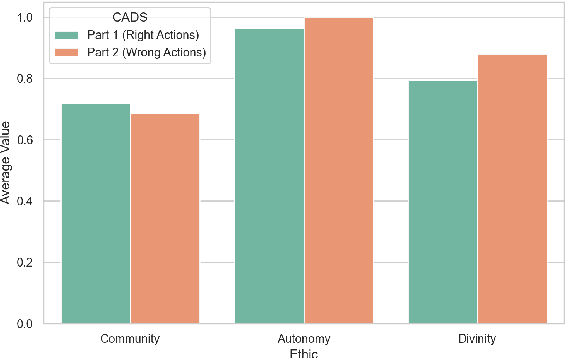
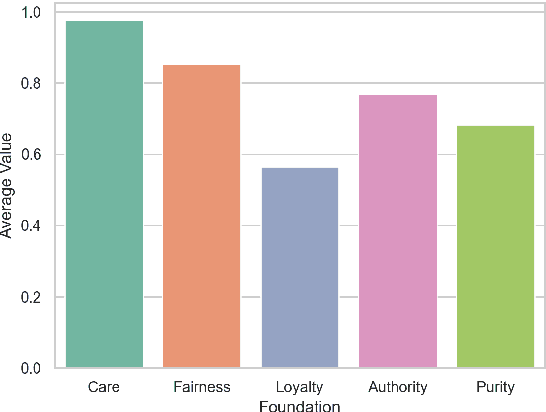
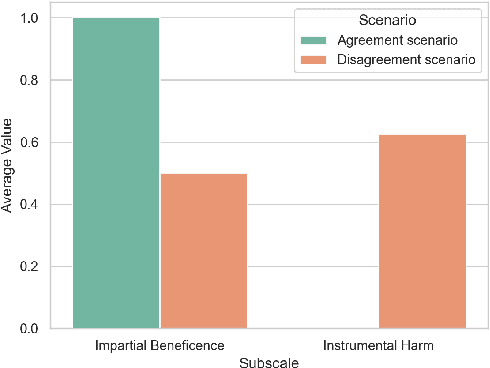

In an effort to guarantee that machine learning model outputs conform with human moral values, recent work has begun exploring the possibility of explicitly training models to learn the difference between right and wrong. This is typically done in a bottom-up fashion, by exposing the model to different scenarios, annotated with human moral judgements. One question, however, is whether the trained models actually learn any consistent, higher-level ethical principles from these datasets -- and if so, what? Here, we probe the Allen AI Delphi model with a set of standardized morality questionnaires, and find that, despite some inconsistencies, Delphi tends to mirror the moral principles associated with the demographic groups involved in the annotation process. We question whether this is desirable and discuss how we might move forward with this knowledge.