 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuron to Graph: Interpreting Language Model Neurons at Scale
May 31, 2023



Advances in Large Language Models (LLMs) have led to remarkable capabilities, yet their inner mechanisms remain largely unknown. To understand these models, we need to unravel the functions of individual neurons and their contribution to the network. This paper introduces a novel automated approach designed to scale interpretability techniques across a vast array of neurons within LLMs, to make them more interpretable and ultimately safe. Conventional methods require examination of examples with strong neuron activation and manual identification of patterns to decipher the concepts a neuron responds to. We propose Neuron to Graph (N2G), an innovative tool that automatically extracts a neuron's behaviour from the dataset it was trained on and translates it into an interpretable graph. N2G uses truncation and saliency methods to emphasise only the most pertinent tokens to a neuron while enriching dataset examples with diverse samples to better encompass the full spectrum of neuron behaviour. These graphs can be visualised to aid researchers' manual interpretation, and can generate token activations on text for automatic validation by comparison with the neuron's ground truth activations, which we use to show that the model is better at predicting neuron activation than two baseline methods. We also demonstrate how the generated graph representations can be flexibly used to facilitate further automation of interpretability research, by searching for neurons with particular properties, or programmatically comparing neurons to each other to identify similar neurons. Our method easily scales to build graph representations for all neurons in a 6-layer Transformer model using a single Tesla T4 GPU, allowing for wide usability. We release the code and instructions for use at https://github.com/alexjfoote/Neuron2Graph.
Erasure of Unaligned Attributes from Neural Representations
Feb 06, 2023We present the Assignment-Maximization Spectral Attribute removaL (AMSAL) algorithm, which aims at removing information from neural representations when the information to be erased is implicit rather than directly being aligned to each input example. Our algorithm works by alternating between two steps. In one, it finds an assignment of the input representations to the information to be erased, and in the other, it creates projections of both the input representations and the information to be erased into a joint latent space. We test our algorithm on an extensive array of datasets, including a Twitter dataset with multiple guarded attributes, the BiasBios dataset and the BiasBench benchmark. The latter benchmark includes four datasets with various types of protected attributes. Our results demonstrate that bias can often be removed in our setup. We also discuss the limitations of our approach when there is a strong entanglement between the main task and the information to be erased.
Tensors over Semirings for Latent-Variable Weighted Logic Programs
Jun 07, 2020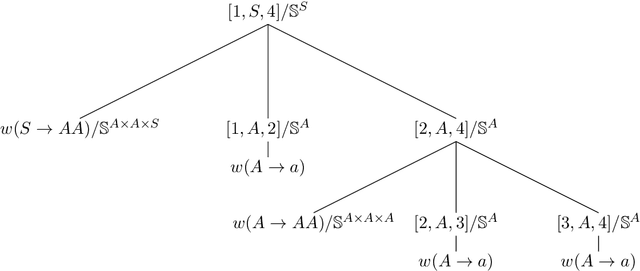
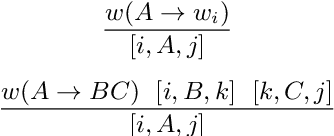
Semiring parsing is an elegant framework for describing parsers by using semiring weighted logic programs. In this paper we present a generalization of this concept: latent-variable semiring parsing. With our framework, any semiring weighted logic program can be latentified by transforming weights from scalar values of a semiring to rank-n arrays, or tensors, of semiring values, allowing the modelling of latent variables within the semiring parsing framework. Semiring is too strong a notion when dealing with tensors, and we have to resort to a weaker structure: a partial semiring. We prove that this generalization preserves all the desired properties of the original semiring framework while strictly increasing its expressiveness.